MAGE: Multimodal Alignment and Generation Enhancement via Bridging Visual and Semantic Spaces
作者: Shaojun E, Yuchen Yang, Jiaheng Wu, Yan Zhang, Tiejun Zhao, Ziyan Chen
分类: cs.CV, cs.MM
发布日期: 2025-07-29
备注: 9 pages
🔗 代码/项目: GITHUB
💡 一句话要点
MAGE:通过桥接视觉和语义空间,增强多模态对齐和生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语义对齐 智能对齐网络 多模态生成 大型语言模型
📋 核心要点
- 现有方法在多模态学习中,视觉数据编码后存在空间和语义损失,影响模型性能。
- MAGE通过智能对齐网络(IAN)桥接视觉和文本语义空间,实现维度和语义对齐。
- MAGE在MME、MMBench和SEED等基准测试中,性能显著优于同类模型。
📝 摘要(中文)
最新的多模态学习进展中,有效解决视觉数据编码后的空间和语义损失仍然是一个关键挑战。这是因为大型多模态模型的性能与视觉编码器和大型语言模型之间的耦合程度呈正相关。现有方法通常面临向量差距或语义差异等问题,导致信息在传播过程中丢失。为了解决这些问题,我们提出了一种新颖的框架MAGE(多模态对齐和生成增强),它通过创新的对齐机制桥接视觉和文本的语义空间。通过引入智能对齐网络(IAN),MAGE实现了维度和语义对齐。为了减少同义异构数据之间的差距,我们采用了一种结合交叉熵和均方误差的训练策略,显著增强了对齐效果。此外,为了增强MAGE的“Any-to-Any”能力,我们开发了一个用于多模态工具调用指令的微调数据集,以扩展模型的输出能力边界。最后,我们提出的多模态大型模型架构MAGE在各种评估基准(包括MME、MMBench和SEED)上,与类似工作相比,取得了显著更好的性能。
🔬 方法详解
问题定义:现有的大型多模态模型在处理视觉信息时,由于视觉编码器和大型语言模型之间的耦合不足,导致视觉信息在编码后出现空间和语义上的损失。这种损失体现在向量空间上的差距以及语义理解上的差异,最终影响模型的整体性能,尤其是在需要精确理解图像内容并进行复杂推理的任务中。
核心思路:MAGE的核心思路是通过一个创新的对齐机制,显式地桥接视觉和文本的语义空间,从而减少信息损失。具体来说,它旨在将视觉特征和文本特征映射到一个共同的语义空间中,使得模型能够更好地理解和利用视觉信息。这种对齐机制的目标是最小化异构数据(即视觉和文本数据)之间的语义差距,从而提高模型的理解和生成能力。
技术框架:MAGE的整体架构包含视觉编码器、智能对齐网络(IAN)和大型语言模型。首先,视觉编码器将图像转换为视觉特征。然后,IAN负责将视觉特征与文本特征进行对齐,使其位于同一语义空间。对齐后的视觉特征被输入到大型语言模型中,用于生成文本描述或执行其他多模态任务。为了增强模型的“Any-to-Any”能力,还使用了多模态工具调用指令进行微调。
关键创新:MAGE最关键的创新点在于智能对齐网络(IAN),它能够同时实现维度和语义上的对齐。传统的对齐方法可能只关注维度上的匹配,而忽略了语义上的差异。IAN通过学习一个映射函数,将视觉特征和文本特征映射到一个共同的语义空间,从而更好地保留了视觉信息中的语义信息。此外,结合交叉熵和均方误差的训练策略也是一个创新点,它能够更有效地减少同义异构数据之间的差距。
关键设计:IAN的具体结构未知,但根据描述,它应该包含一些可学习的参数,用于将视觉特征映射到文本特征的语义空间。损失函数方面,采用了交叉熵和均方误差的组合,其中交叉熵用于分类任务,均方误差用于回归任务,以实现更精确的对齐。微调数据集的设计也至关重要,它包含了多模态工具调用指令,用于扩展模型的输出能力边界。具体的网络结构和参数设置在论文中可能包含更多细节,但摘要中未明确说明。
🖼️ 关键图片
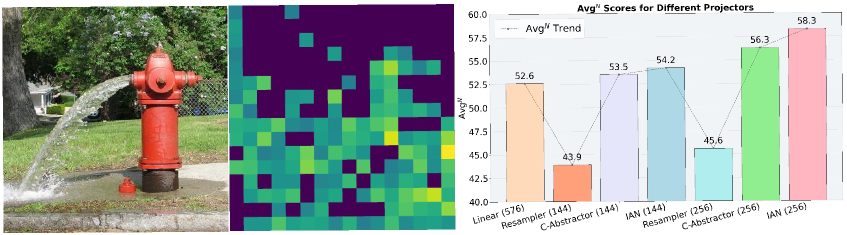
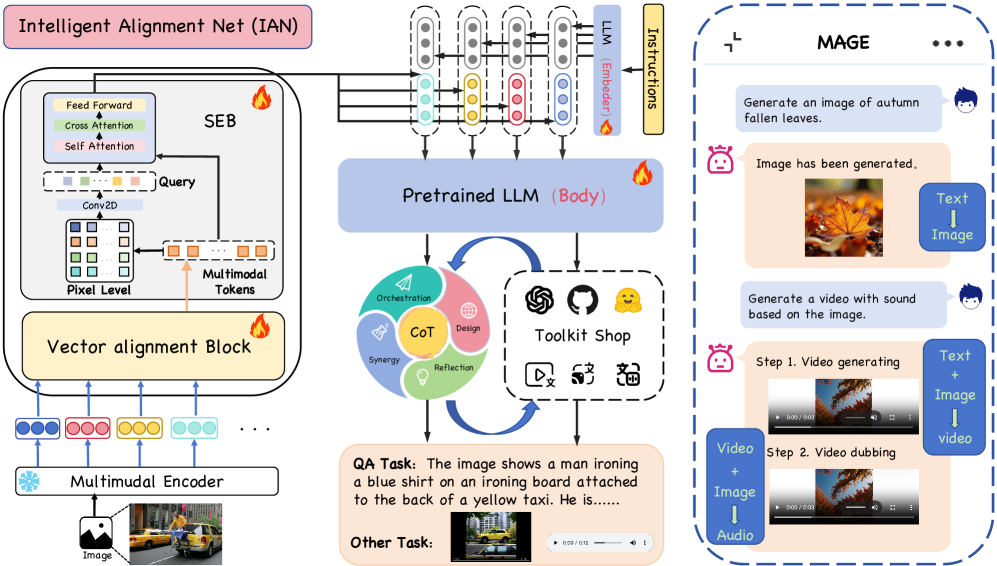

📊 实验亮点
MAGE在MME、MMBench和SEED等多个多模态评估基准上取得了显著的性能提升,表明其在多模态对齐和生成方面具有优越性。具体的性能数据和提升幅度需要在论文中查找,摘要中未提供详细的数值结果。与现有方法相比,MAGE能够更好地保留视觉信息中的语义信息,从而提高模型的整体性能。
🎯 应用场景
MAGE具有广泛的应用前景,例如智能客服、图像描述生成、视觉问答、多模态对话系统等。通过增强多模态对齐和生成能力,MAGE可以帮助机器更好地理解和利用视觉信息,从而实现更智能的人机交互。未来,MAGE有望在医疗诊断、自动驾驶、智能家居等领域发挥重要作用。
📄 摘要(原文)
In the latest advancements in multimodal learning, effectively addressing the spatial and semantic losses of visual data after encoding remains a critical challenge. This is because the performance of large multimodal models is positively correlated with the coupling between visual encoders and large language models. Existing approaches often face issues such as vector gaps or semantic disparities, resulting in information loss during the propagation process. To address these issues, we propose MAGE (Multimodal Alignment and Generation Enhancement), a novel framework that bridges the semantic spaces of vision and text through an innovative alignment mechanism. By introducing the Intelligent Alignment Network (IAN), MAGE achieves dimensional and semantic alignment. To reduce the gap between synonymous heterogeneous data, we employ a training strategy that combines cross-entropy and mean squared error, significantly enhancing the alignment effect. Moreover, to enhance MAGE's "Any-to-Any" capability, we developed a fine-tuning dataset for multimodal tool-calling instructions to expand the model's output capability boundaries. Finally, our proposed multimodal large model architecture, MAGE, achieved significantly better performance compared to similar works across various evaluation benchmarks, including MME, MMBench, and SEED. Complete code and appendix are available at: https://github.com/GTCOM-NLP/MAGE.