TARS: MinMax Token-Adaptive Preference Strategy for MLLM Hallucination Reduction
作者: Kejia Zhang, Keda Tao, Zhiming Luo, Chang Liu, Jiasheng Tang, Huan Wang
分类: cs.CV
发布日期: 2025-07-29 (更新: 2025-08-09)
💡 一句话要点
TARS:一种MinMax Token自适应偏好策略,用于降低MLLM的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉抑制 直接偏好优化 MinMax优化 Token自适应 视觉语言推理 因果关系
📋 核心要点
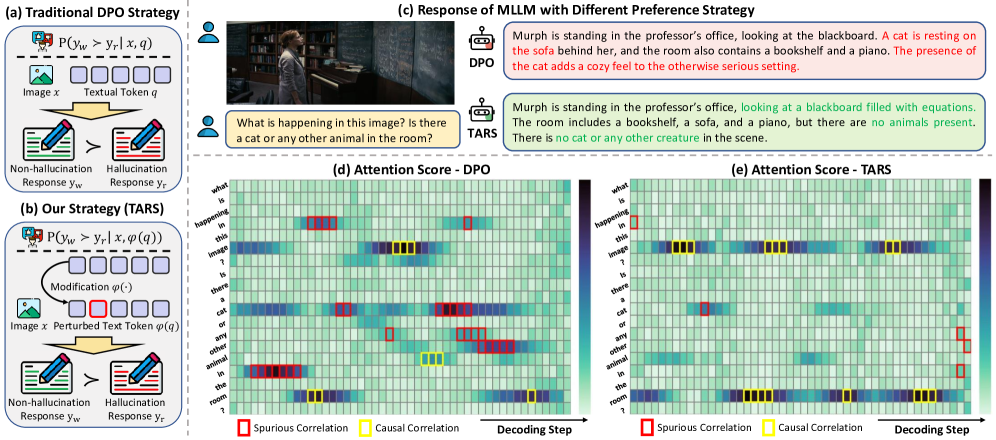
- 现有DPO方法易过度拟合偏好数据中的表面语言线索,导致模型难以有效利用视觉信息进行推理,产生幻觉。
- TARS将DPO重构为min-max优化问题,通过最大化token级别分布偏移来模拟对齐不确定性,提升模型的鲁棒性。
- 实验表明,TARS仅使用少量偏好样本即可显著降低MLLM的幻觉率,并在关键指标上与GPT-4o相媲美。
📝 摘要(中文)
多模态大型语言模型(MLLM)实现了视觉-语言推理,但经常生成看似合理但实际上不正确的输出,从而损害了其可靠性。直接偏好优化(DPO)是一种通过将模型输出与人类偏好对齐来纠正幻觉的常用策略。现有的DPO策略通常将与幻觉相关的偏好视为固定目标,依赖于训练期间的静态监督信号。这种方法容易过度拟合偏好数据中的表面语言线索,导致分布刚性和虚假相关性,从而损害了对因果相关的视觉信息的理解。为了克服这个限制,我们提出了一种token自适应偏好策略TARS,它将DPO重新定义为一个min-max优化问题。TARS在语义约束下最大化token级别的分布偏移以模拟对齐不确定性,并同时最小化在这些受控扰动下的预期偏好损失。这种联合目标保留了因果关系,同时减轻了对偏好模式的过度拟合,从而减少了多模态推理中的幻觉。我们在多个幻觉基准上评估了TARS,发现了一致的强大性能。仅使用4.8k个偏好样本且没有专家反馈,TARS将幻觉率从26.4%降低到13.2%,并将认知价值从2.5降低到0.4。它优于标准DPO,并在几个关键指标上与GPT-4o相匹配。
🔬 方法详解
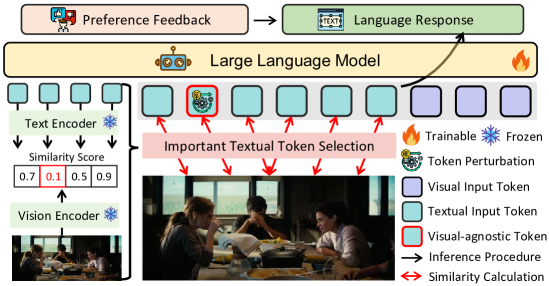
问题定义:MLLM的幻觉问题,即生成看似合理但与事实不符或视觉上无根据的输出。现有DPO方法过度依赖静态的偏好数据,导致模型学习到虚假相关性,无法有效利用视觉信息进行推理,从而产生幻觉。
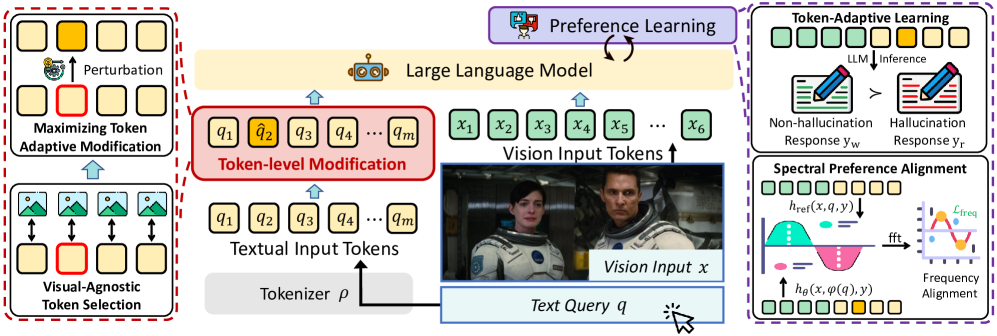
核心思路:将DPO过程视为一个min-max优化问题。通过最大化token级别的分布偏移来模拟对齐的不确定性,迫使模型学习更鲁棒的特征表示,从而减少对偏好数据中表面语言线索的过度拟合。同时,最小化在这些扰动下的预期偏好损失,以保证模型的性能。
技术框架:TARS的核心是一个min-max优化框架。首先,通过在token级别引入扰动来模拟对齐的不确定性。然后,在这些扰动下,最大化token级别的分布偏移,以增加模型的鲁棒性。最后,最小化在这些扰动下的预期偏好损失,以保证模型的性能。整个框架通过联合优化这两个目标来实现。
关键创新:TARS的关键创新在于将DPO过程重新定义为一个min-max优化问题,并引入token级别的扰动来模拟对齐的不确定性。这种方法能够有效地减少模型对偏好数据中表面语言线索的过度拟合,从而提高模型的鲁棒性和泛化能力。与现有方法相比,TARS能够更好地利用视觉信息进行推理,从而减少幻觉的产生。
关键设计:TARS的关键设计包括:1) token级别的扰动策略,用于模拟对齐的不确定性;2) min-max优化目标,用于平衡模型的鲁棒性和性能;3) 语义约束,用于保证扰动的合理性。具体的损失函数包括偏好损失和分布偏移损失。参数设置方面,需要仔细调整扰动的幅度,以保证模型的训练稳定性和性能。
🖼️ 关键图片
📊 实验亮点
TARS在多个幻觉基准测试中表现出色,仅使用4.8k个偏好样本,就将幻觉率从26.4%降低到13.2%,认知价值从2.5降低到0.4。在某些关键指标上,TARS甚至可以与GPT-4o相媲美,证明了其在降低MLLM幻觉方面的有效性。
🎯 应用场景
TARS可应用于各种需要可靠多模态推理的场景,例如:自动驾驶、医疗诊断、智能客服等。通过降低MLLM的幻觉率,提高其决策的准确性和可靠性,从而提升用户体验和安全性。未来,该方法有望进一步推广到其他类型的多模态任务中。
📄 摘要(原文)
Multimodal large language models (MLLMs) enable vision-language reasoning, yet often generate plausible outputs that are factually incorrect or visually ungrounded, thereby compromising their reliability. Direct preference optimization (DPO) is a common strategy for correcting hallucinations by aligning model outputs with human preferences. Existing DPO strategies typically treat hallucination-related preferences as fixed targets, relying on static supervision signals during training. This approach tends to overfit to superficial linguistic cues in preference data, leading to distributional rigidity and spurious correlations that impair grounding in causally relevant visual information. To overcome this limitation, we propose TARS, a token-adaptive preference strategy that reformulates DPO as a min-max optimization problem. TARS maximizes token-level distributional shifts under semantic constraints to simulate alignment uncertainty, and simultaneously minimizes the expected preference loss under these controlled perturbations. This joint objective preserves causal grounding while mitigating overfitting to preference patterns, thereby reducing hallucinations in multimodal reasoning. We evaluate TARS on multiple hallucination benchmarks and find consistently strong performance. Using only 4.8k preference samples and no expert feedback, TARS reduces hallucination rates from 26.4% to 13.2% and decreases cognition value from 2.5 to 0.4. It outperforms standard DPO and matches GPT-4o on several key metrics.