Describe, Adapt and Combine: Empowering CLIP Encoders for Open-set 3D Object Retrieval
作者: Zhichuan Wang, Yang Zhou, Zhe Liu, Rui Yu, Song Bai, Yulong Wang, Xinwei He, Xiang Bai
分类: cs.CV
发布日期: 2025-07-29
备注: Accepted to ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出DAC框架,利用CLIP和MLLM增强开放集3D物体检索能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放集3D物体检索 CLIP 多模态大语言模型 知识迁移 参数高效微调
📋 核心要点
- 现有3D物体检索方法依赖大量3D数据,泛化性差,难以处理未见类别。
- DAC框架结合CLIP和MLLM,利用MLLM描述类别信息并提供外部提示,提升泛化能力。
- 实验表明,DAC在开放集3DOR任务上显著优于现有方法,mAP平均提升10.01%。
📝 摘要(中文)
开放集3D物体检索(3DOR)是一项新兴任务,旨在检索训练集中未见过的类别的3D物体。现有方法通常利用所有模态(如体素、点云、多视角图像)并训练特定的骨干网络,但由于3D训练数据不足,泛化能力受限。本文提出Describe, Adapt and Combine (DAC)框架,仅使用多视角图像,通过结合CLIP模型和多模态大语言模型(MLLM)来学习广义的3D表示,其中MLLM用于双重目的:在训练期间描述已见类别信息以与CLIP的训练目标对齐,并在推理期间提供关于未知物体的外部提示,以补充视觉线索。为了改善协同作用,引入了Additive-Bias Low-Rank adaptation (AB-LoRA),减轻过拟合并进一步增强对未见类别的泛化。在四个开放集3DOR数据集上,DAC仅使用多视角图像就显著超越了现有技术,平均mAP提升+10.01%。此外,其泛化能力也在基于图像和跨数据集设置中得到验证。
🔬 方法详解
问题定义:开放集3D物体检索旨在检索训练集中未出现的3D物体类别。现有方法依赖于大量3D数据进行训练,导致模型泛化能力不足,难以有效处理未见过的类别。这些方法通常需要训练特定的3D骨干网络,增加了计算成本和模型复杂度。
核心思路:本文的核心思路是利用预训练的CLIP模型和多模态大语言模型(MLLM)的强大泛化能力,通过多视角图像学习广义的3D表示。CLIP在海量图像-文本数据上进行对比学习,具备良好的视觉语义对齐能力。MLLM则用于提供类别描述和外部提示,辅助模型理解和识别未见类别。
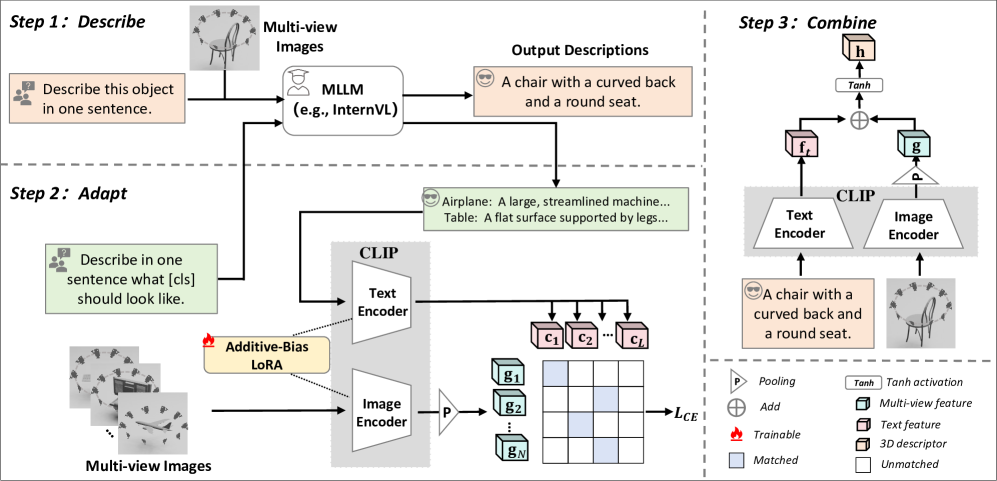
技术框架:DAC框架包含三个主要阶段:Describe, Adapt, 和 Combine。首先,Describe阶段利用MLLM描述已见类别的信息,将其与CLIP的训练目标对齐,从而实现知识迁移。其次,Adapt阶段使用Additive-Bias Low-Rank adaptation (AB-LoRA)方法,微调CLIP模型,减轻过拟合,增强泛化能力。最后,Combine阶段在推理时,利用MLLM提供关于未知物体的外部提示,结合视觉线索,进行3D物体检索。
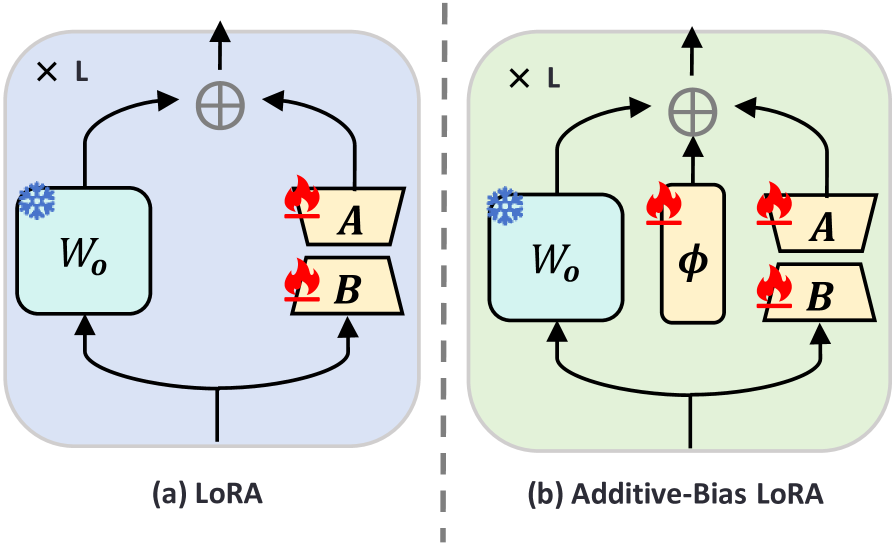
关键创新:DAC的关键创新在于将CLIP和MLLM有效结合,用于开放集3D物体检索。与现有方法相比,DAC无需训练特定的3D骨干网络,而是利用预训练模型的泛化能力,显著提升了对未见类别的检索性能。AB-LoRA是一种新的参数高效微调方法,能够有效缓解过拟合,进一步提升模型的泛化能力。
关键设计:AB-LoRA通过在LoRA的基础上引入Additive-Bias,更好地适应下游任务。MLLM的使用方式是关键,训练时提供类别描述,推理时提供外部提示。损失函数方面,采用对比学习损失,鼓励模型学习视觉和语义之间的对齐关系。多视角图像的使用也至关重要,提供了3D物体的多方面信息。
🖼️ 关键图片
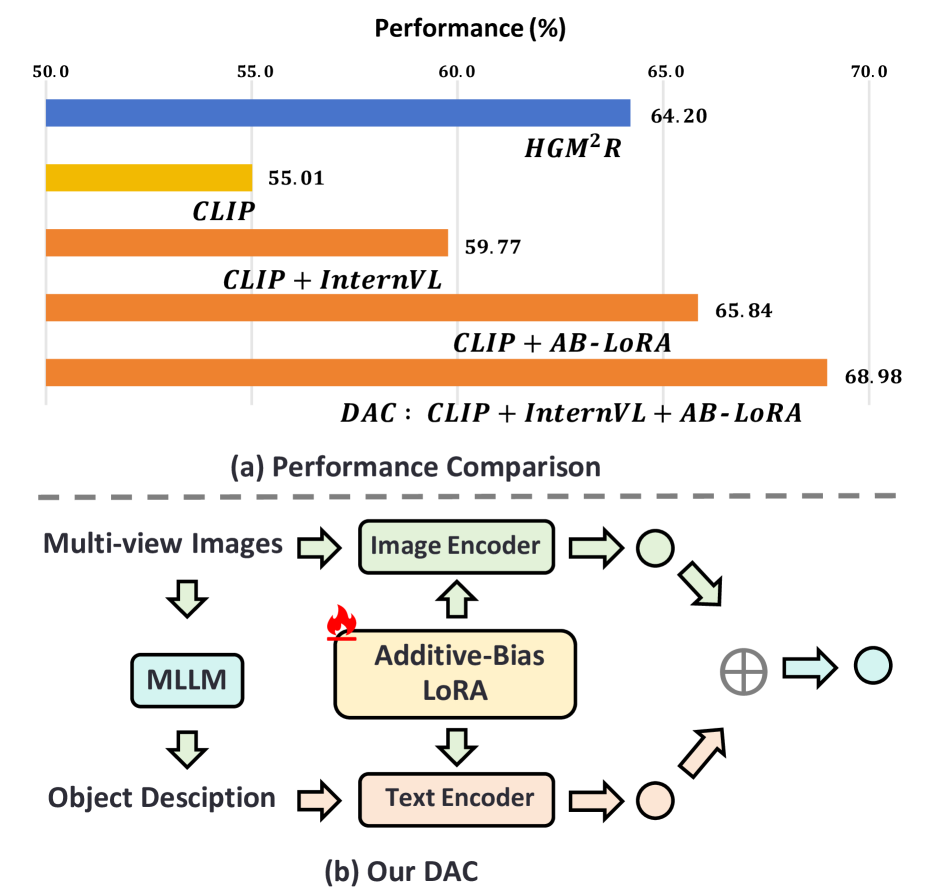
📊 实验亮点
DAC在四个开放集3DOR数据集上取得了显著的性能提升,平均mAP提升了10.01%。在ModelNet40数据集上,DAC的mAP达到了75.32%,超过了现有最佳方法。在ShapeNet数据集上,DAC的mAP达到了68.54%,同样取得了领先地位。此外,DAC在基于图像和跨数据集的实验中也表现出良好的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能家居等领域,提升机器人在复杂环境中识别和检索未知物体的能力。例如,机器人可以根据用户的文本描述,在未知的环境中找到目标物体,从而实现更智能的人机交互。此外,该方法还可以用于3D模型库的检索和管理,方便用户快速找到所需的3D模型。
📄 摘要(原文)
Open-set 3D object retrieval (3DOR) is an emerging task aiming to retrieve 3D objects of unseen categories beyond the training set. Existing methods typically utilize all modalities (i.e., voxels, point clouds, multi-view images) and train specific backbones before fusion. However, they still struggle to produce generalized representations due to insufficient 3D training data. Being contrastively pre-trained on web-scale image-text pairs, CLIP inherently produces generalized representations for a wide range of downstream tasks. Building upon it, we present a simple yet effective framework named Describe, Adapt and Combine (DAC) by taking only multi-view images for open-set 3DOR. DAC innovatively synergizes a CLIP model with a multi-modal large language model (MLLM) to learn generalized 3D representations, where the MLLM is used for dual purposes. First, it describes the seen category information to align with CLIP's training objective for adaptation during training. Second, it provides external hints about unknown objects complementary to visual cues during inference. To improve the synergy, we introduce an Additive-Bias Low-Rank adaptation (AB-LoRA), which alleviates overfitting and further enhances the generalization to unseen categories. With only multi-view images, DAC significantly surpasses prior arts by an average of +10.01\% mAP on four open-set 3DOR datasets. Moreover, its generalization is also validated on image-based and cross-dataset setups. Code is available at https://github.com/wangzhichuan123/DAC.