Multimodal LLMs as Customized Reward Models for Text-to-Image Generation
作者: Shijie Zhou, Ruiyi Zhang, Huaisheng Zhu, Branislav Kveton, Yufan Zhou, Jiuxiang Gu, Jian Chen, Changyou Chen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-07-28 (更新: 2025-07-30)
备注: Accepted at ICCV 2025. Code available at https://github.com/sjz5202/LLaVA-Reward
💡 一句话要点
提出LLaVA-Reward,利用多模态LLM为文本到图像生成定制奖励模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大型语言模型 文本到图像生成 奖励模型 自动评估 交叉注意力
📋 核心要点
- 现有基于MLLM的文本到图像生成评估方法依赖指令数据微调和文本分析,效率低且训练困难。
- LLaVA-Reward直接利用MLLM的隐藏状态,并通过SkipCA模块增强文本和图像特征的交互。
- 实验表明,LLaVA-Reward在文本-图像对齐、保真度、安全性和整体排名方面优于现有方法。
📝 摘要(中文)
本文提出LLaVA-Reward,一种高效的奖励模型,旨在利用预训练的多模态大型语言模型(MLLM)自动评估文本到图像(T2I)生成的多个方面。现有的基于MLLM的方法需要指令遵循数据进行监督微调,并通过分析文本响应来评估生成质量,这既耗时又难以训练。为了解决这个问题,我们提出了LLaVA-Reward,它直接利用MLLM在给定文本-图像对时的隐藏状态。为了增强仅解码器MLLM中视觉和文本表示之间的双向交互,我们进一步提出添加一个跳跃连接交叉注意力(SkipCA)模块。这种设计通过将早期视觉特征与后期隐藏表示连接起来,增强了文本-图像相关性推理。此外,LLaVA-Reward支持不同类型的偏好数据,以实现高效的微调,包括配对偏好数据和非配对数据。我们在四个评估角度上训练LLaVA-Reward:文本-图像对齐、保真度/伪影、安全性和整体排名。实验结果表明,LLaVA-Reward在生成与人类对齐的分数方面优于传统的和基于MLLM的方法,可用于文本到图像生成中的自动评估和推理时缩放。
🔬 方法详解
问题定义:现有基于多模态大型语言模型(MLLM)的文本到图像(T2I)生成评估方法,通常需要大量的指令遵循数据进行监督微调,并且主要通过分析生成的文本输出来评估图像质量。这种方式不仅训练成本高昂,而且文本分析的间接性也限制了评估的准确性。因此,如何更直接、更高效地利用MLLM的强大能力来评估T2I生成质量是一个关键问题。
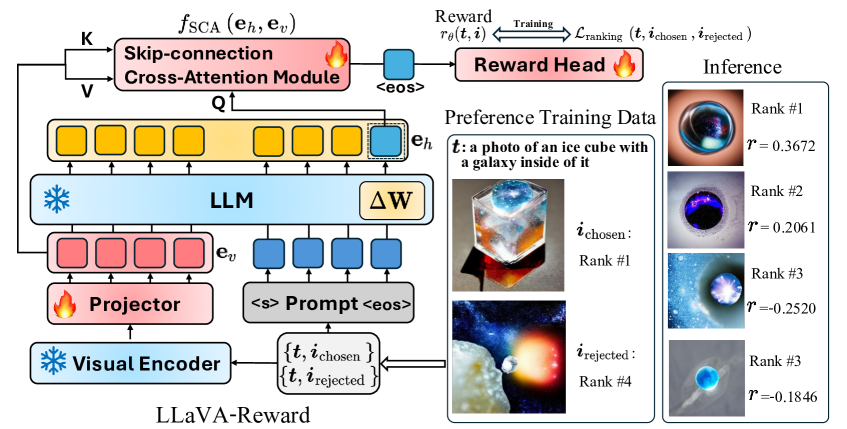
核心思路:LLaVA-Reward的核心思路是直接利用预训练MLLM处理文本-图像对时的隐藏状态,避免了对大量指令数据的依赖。通过将文本和图像信息同时输入MLLM,并提取其内部的隐藏状态,可以更直接地捕捉文本和图像之间的关联性。此外,引入Skip-connection Cross Attention (SkipCA)模块,进一步增强了文本和图像特征之间的交互,从而提升了评估的准确性。
技术框架:LLaVA-Reward的整体框架包括以下几个主要部分:1) 文本编码器:将输入的文本描述转换为文本嵌入向量。2) 图像编码器:将生成的图像转换为图像嵌入向量。3) 多模态大型语言模型(MLLM):将文本和图像嵌入向量输入MLLM,并提取其隐藏状态。4) SkipCA模块:增强文本和图像特征之间的交互。5) 奖励预测器:利用提取的隐藏状态预测奖励分数,用于评估图像质量。整个流程旨在直接从MLLM的内部表示中提取信息,从而实现高效且准确的T2I生成评估。
关键创新:LLaVA-Reward最重要的技术创新点在于其直接利用MLLM的隐藏状态进行评估,避免了对指令数据的依赖,并引入SkipCA模块增强了文本和图像特征的交互。与现有方法相比,LLaVA-Reward更加高效、直接,并且能够更准确地捕捉文本和图像之间的关联性。这种方法为T2I生成评估提供了一种新的思路,并具有广泛的应用前景。
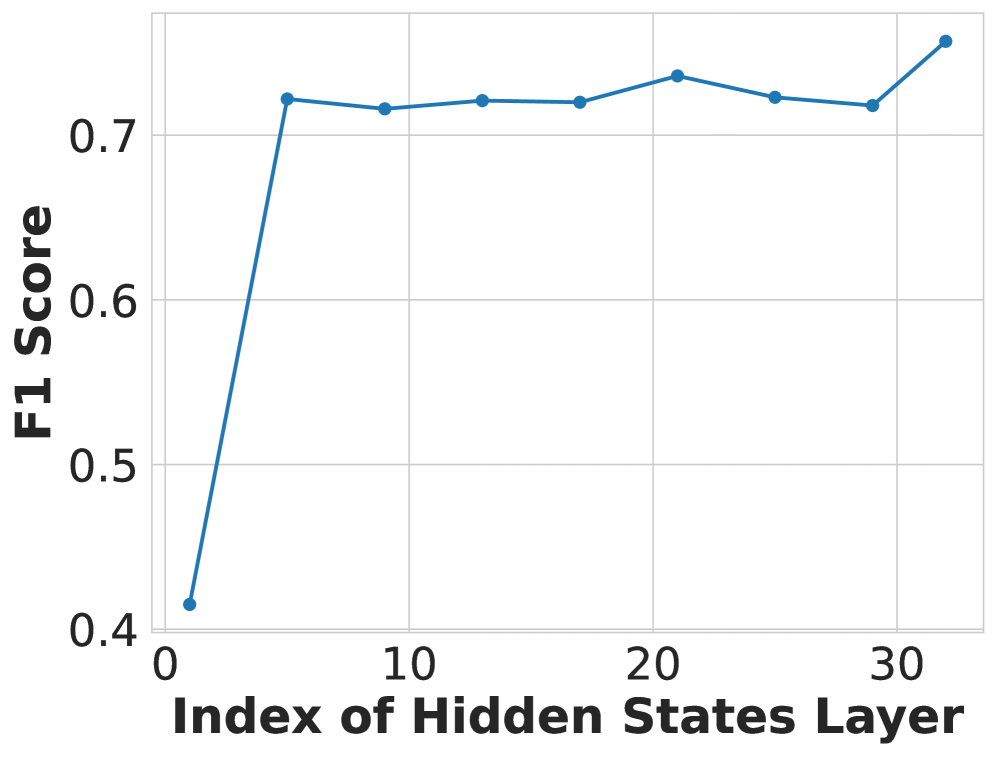
关键设计:SkipCA模块的关键设计在于将早期视觉特征与后期隐藏表示连接起来,从而增强文本-图像相关性推理。具体来说,SkipCA模块将图像编码器早期层的输出与MLLM后期层的隐藏状态进行交叉注意力计算,从而使MLLM能够更好地利用图像的底层特征。此外,LLaVA-Reward支持不同类型的偏好数据进行微调,包括配对偏好数据和非配对数据,从而提高了模型的泛化能力。损失函数的设计也至关重要,需要根据具体的评估角度(如文本-图像对齐、保真度、安全性等)进行调整。
🖼️ 关键图片
📊 实验亮点
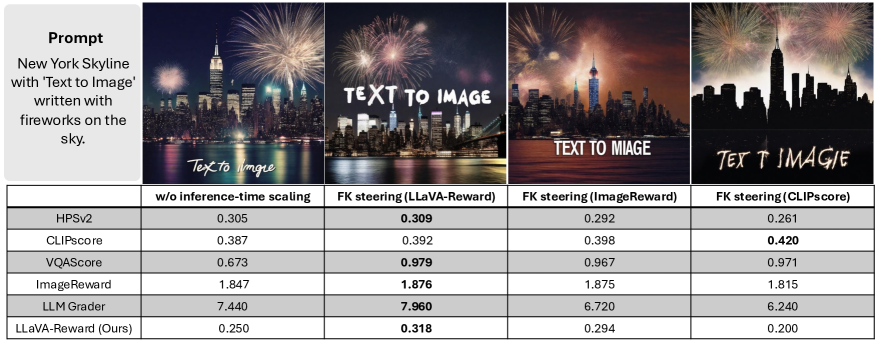
实验结果表明,LLaVA-Reward在生成与人类对齐的分数方面优于传统的和基于MLLM的方法。具体来说,LLaVA-Reward在文本-图像对齐、保真度、安全性和整体排名等多个评估指标上都取得了显著的提升。这些结果证明了LLaVA-Reward在T2I生成评估方面的有效性和优越性。
🎯 应用场景
LLaVA-Reward可广泛应用于文本到图像生成模型的自动评估、模型选择和优化。它能够帮助研究人员和开发者更高效地评估和改进T2I模型,从而提升生成图像的质量和用户体验。此外,该方法还可以应用于其他多模态生成任务,例如视频生成、3D模型生成等,具有重要的实际价值和未来影响。
📄 摘要(原文)
We introduce LLaVA-Reward, an efficient reward model designed to automatically evaluate text-to-image (T2I) generations across multiple perspectives, leveraging pretrained multimodal large language models (MLLMs). Existing MLLM-based approaches require instruction-following data for supervised fine-tuning and evaluate generation quality on analyzing text response, which is time-consuming and difficult to train. To address this problem, we propose LLaVA-Reward, which directly utilizes the hidden states of MLLMs given text-image pairs. To enhance the bidirectional interaction between visual and textual representations in decoder-only MLLMs, we further propose adding a Skip-connection Cross Attention (SkipCA) module. This design enhances text-image correlation reasoning by connecting early-layer visual features with later-layer hidden representations. In addition, LLaVA-Reward supports different types of preference data for efficient fine-tuning, including paired preference data and unpaired data. We train LLaVA-Reward on four evaluation perspectives: text-image alignment, fidelity/artifact, safety, and overall ranking. Empirical results demonstrate that LLaVA-Reward outperforms conventional and MLLM-based methods in generating human-aligned scores for automatic evaluations and inference-time scaling in text-to-image generations.