On Explaining Visual Captioning with Hybrid Markov Logic Networks
作者: Monika Shah, Somdeb Sarkhel, Deepak Venugopal
分类: cs.CV, cs.AI
发布日期: 2025-07-28
💡 一句话要点
提出基于混合马尔可夫逻辑网络的视觉描述解释框架,提升模型可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述 可解释性 混合马尔可夫逻辑网络 多模态学习 深度学习 模型解释 视觉推理
📋 核心要点
- 深度学习图像描述模型缺乏可解释性,难以理解模型如何融合多模态信息生成描述。
- 提出基于混合马尔可夫逻辑网络(HMLN)的解释框架,通过学习训练数据分布来推断生成描述的影响因素。
- 实验表明,该框架能够提供可解释的解释,并可用于比较不同描述模型的可解释性。
📝 摘要(中文)
深度神经网络在图像描述等多模态任务中取得了显著进展。然而,解释这些模型如何整合视觉信息、语言信息和知识表示以生成有意义的描述仍然是一个具有挑战性的问题。传统的性能评估指标通常依赖于将生成的描述与人工撰写的描述进行比较,这可能无法为用户提供对这种整合的深入理解。本文提出了一种新颖的解释框架,该框架基于混合马尔可夫逻辑网络(HMLN),这是一种可以将符号规则与实值函数相结合的语言,并且易于解释。我们假设来自训练数据的相关示例可能影响了观察到的描述的生成。为此,我们学习了训练实例上的HMLN分布,并推断当以生成的样本为条件时,这些实例上的分布变化,从而量化哪些示例可能是生成观察到的描述的更丰富的信息来源。我们在使用Amazon Mechanical Turk为多个最先进的描述模型生成的描述上进行的实验,证明了我们解释的可解释性,并允许我们沿着可解释性的维度比较这些模型。
🔬 方法详解
问题定义:现有的图像描述模型,虽然在生成描述的准确性上取得了很大进展,但是缺乏可解释性。用户难以理解模型是如何利用图像信息、语言信息以及知识表示来生成最终的描述的。传统的评估指标,如BLEU,主要关注生成描述与人工标注的相似度,无法提供模型内部运作机制的洞察。因此,如何解释图像描述模型的决策过程,成为了一个重要的研究问题。
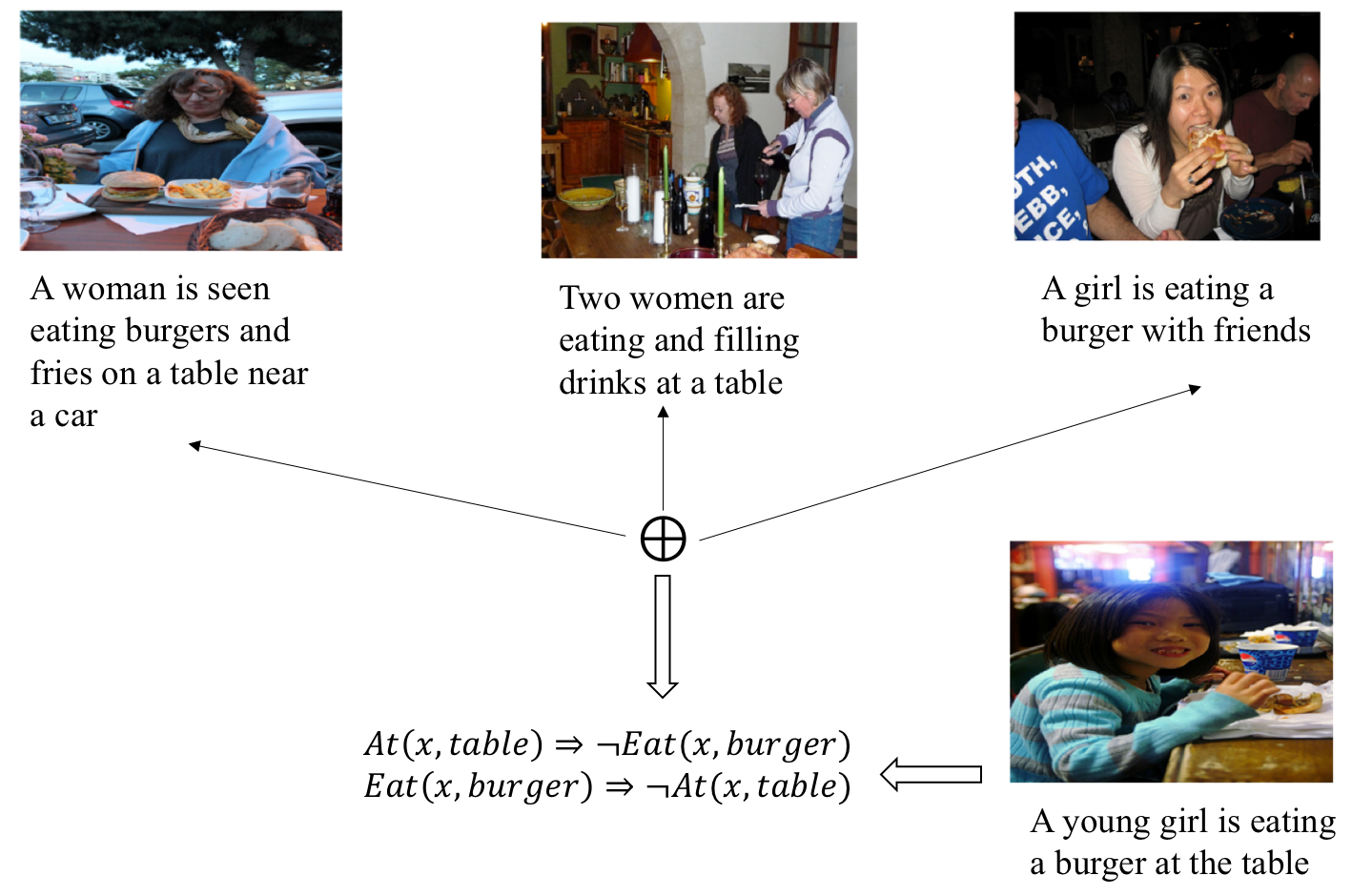
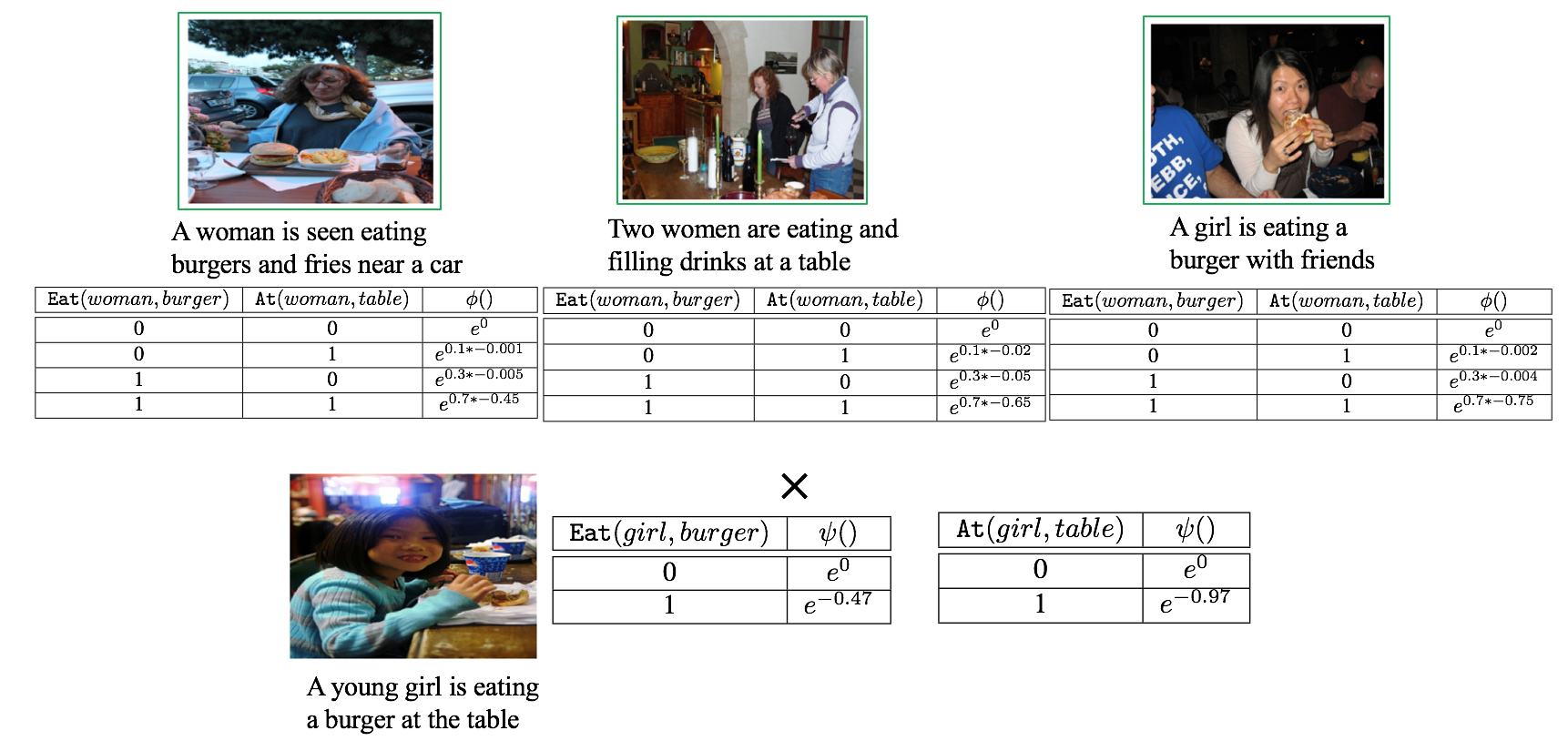
核心思路:本文的核心思路是利用混合马尔可夫逻辑网络(HMLN)来构建一个可解释的解释框架。HMLN能够将符号规则和实值函数结合起来,从而可以同时处理离散的知识表示和连续的视觉信息。通过学习训练数据的HMLN分布,可以推断出哪些训练样本对生成特定描述产生了更大的影响。这种方法将模型的决策过程与具体的训练样本联系起来,从而提供了更直观的解释。
技术框架:该框架主要包含以下几个阶段:1. 数据准备:收集图像描述数据集,并对数据进行预处理,例如提取图像特征和文本特征。2. HMLN学习:利用训练数据学习一个HMLN分布。这个分布描述了训练样本之间的关系,以及它们对生成描述的影响。3. 推断:给定一个生成的描述,利用学习到的HMLN分布,推断哪些训练样本对生成该描述产生了更大的影响。具体来说,就是计算在给定生成描述的条件下,训练样本分布的偏移。4. 解释生成:根据推断结果,选择对生成描述影响最大的训练样本,并将其作为解释提供给用户。
关键创新:该论文的关键创新在于将HMLN应用于图像描述的可解释性研究。HMLN能够同时处理符号规则和实值函数,从而可以更好地表示图像描述模型中的复杂关系。此外,该论文还提出了一种基于分布偏移的推断方法,可以有效地识别对生成描述影响最大的训练样本。与现有的可解释性方法相比,该方法更加直观和易于理解。
关键设计:HMLN的具体形式需要根据具体的数据集和任务进行设计。例如,可以利用图像的视觉特征和文本的语义特征来定义HMLN中的原子谓词。HMLN中的权重可以通过最大似然估计等方法进行学习。在推断阶段,可以使用吉布斯采样等方法来计算条件分布。此外,如何选择对生成描述影响最大的训练样本,也是一个需要仔细考虑的问题。例如,可以选择分布偏移最大的前K个样本作为解释。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够提供可解释的解释,并可用于比较不同描述模型的可解释性。通过Amazon Mechanical Turk进行的用户研究表明,用户认为该方法提供的解释是直观和有用的。此外,实验还表明,不同的描述模型在可解释性方面存在差异,例如,一些模型可能过度依赖某些特定的训练样本。
🎯 应用场景
该研究成果可应用于提升图像描述模型的可信度和用户体验。通过提供可解释的描述生成过程,用户可以更好地理解模型的决策依据,从而增强对模型的信任。此外,该方法还可以用于诊断模型的潜在问题,例如识别模型过度依赖的训练样本,从而改进模型的泛化能力。未来,该方法可以扩展到其他多模态任务,例如视频描述和视觉问答。
📄 摘要(原文)
Deep Neural Networks (DNNs) have made tremendous progress in multimodal tasks such as image captioning. However, explaining/interpreting how these models integrate visual information, language information and knowledge representation to generate meaningful captions remains a challenging problem. Standard metrics to measure performance typically rely on comparing generated captions with human-written ones that may not provide a user with a deep insights into this integration. In this work, we develop a novel explanation framework that is easily interpretable based on Hybrid Markov Logic Networks (HMLNs) - a language that can combine symbolic rules with real-valued functions - where we hypothesize how relevant examples from the training data could have influenced the generation of the observed caption. To do this, we learn a HMLN distribution over the training instances and infer the shift in distributions over these instances when we condition on the generated sample which allows us to quantify which examples may have been a source of richer information to generate the observed caption. Our experiments on captions generated for several state-of-the-art captioning models using Amazon Mechanical Turk illustrate the interpretability of our explanations, and allow us to compare these models along the dimension of explainability.