Reconstructing 4D Spatial Intelligence: A Survey
作者: Yukang Cao, Jiahao Lu, Zhisheng Huang, Zhuowen Shen, Chengfeng Zhao, Fangzhou Hong, Zhaoxi Chen, Xin Li, Wenping Wang, Yuan Liu, Ziwei Liu
分类: cs.CV
发布日期: 2025-07-28 (更新: 2025-08-03)
备注: Project page: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence
🔗 代码/项目: GITHUB
💡 一句话要点
对4D空间智能重建进行综述,并按层级结构分析现有方法,展望未来方向。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 4D空间智能 场景重建 计算机视觉 深度学习 动态场景 交互建模 物理约束
📋 核心要点
- 现有4D空间智能重建综述缺乏对方法层级结构的全面分析,难以把握领域发展脉络。
- 论文提出一种新的视角,将现有方法组织成五个递进的4D空间智能层级,便于理解和比较。
- 论文总结了每个层级的关键挑战,并指出了未来发展的有希望的方向,为研究者提供指导。
📝 摘要(中文)
从视觉观测中重建4D空间智能一直是计算机视觉领域的核心挑战,具有广泛的实际应用,涵盖电影等娱乐领域(侧重于重建基本视觉元素)以及具身智能(强调交互建模和物理真实感)。受益于3D表示和深度学习架构的快速发展,该领域发展迅速,超越了以往综述的范围。此外,现有综述很少全面分析4D场景重建的层级结构。为了弥补这一差距,我们提出了一种新的视角,将现有方法组织成五个递进的4D空间智能层级:(1)第一级——重建低级3D属性(例如,深度、姿势和点云图);(2)第二级——重建3D场景组件(例如,对象、人类、结构);(3)第三级——重建4D动态场景;(4)第四级——建模场景组件之间的交互;(5)第五级——结合物理定律和约束。最后,我们讨论了每个层级的关键挑战,并强调了朝着更丰富的4D空间智能发展的有希望的方向。为了跟踪正在进行的开发,我们维护了一个最新的项目页面:https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence。
🔬 方法详解
问题定义:论文旨在解决计算机视觉中从视觉观测重建4D空间智能这一核心问题。现有方法的痛点在于缺乏对4D场景重建的层级结构进行全面分析,使得研究者难以系统地理解和比较不同的方法,也难以把握领域的发展趋势。
核心思路:论文的核心思路是将现有的4D空间智能重建方法按照其复杂度和所能实现的功能,划分为五个递进的层级。这种层级结构能够帮助研究者更好地理解不同方法之间的关系,并识别每个层级所面临的关键挑战。
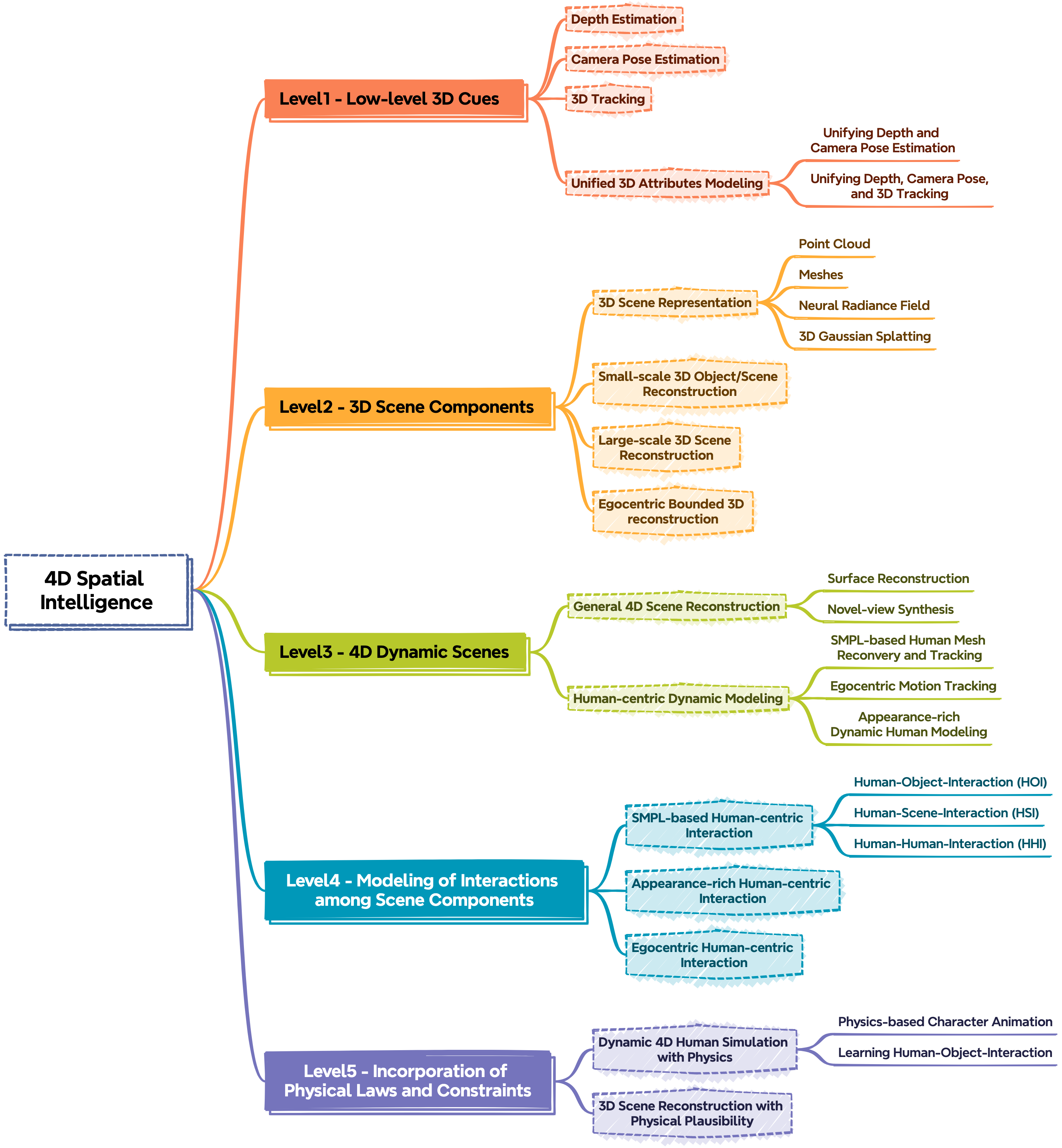
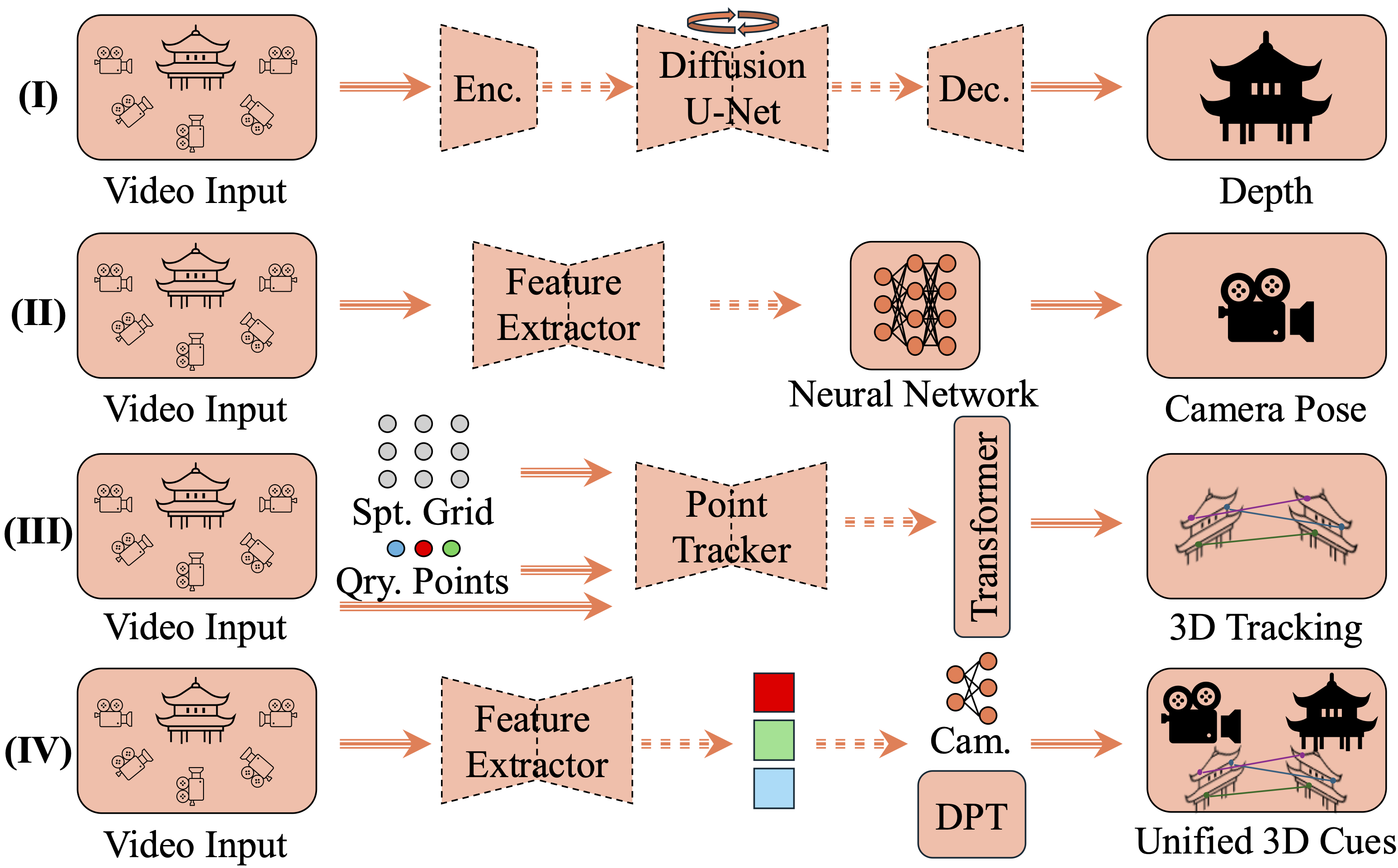
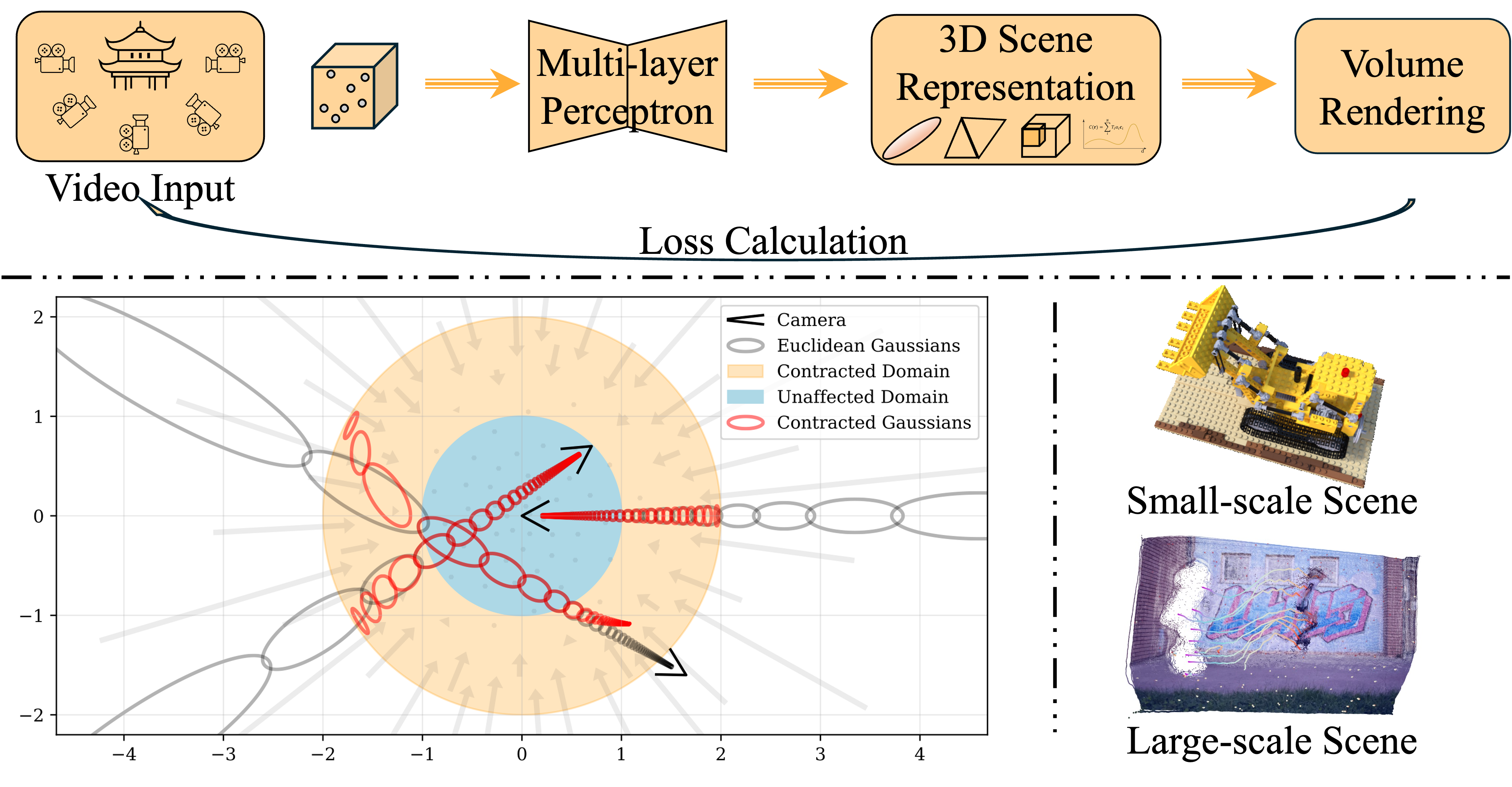
技术框架:论文并没有提出新的算法或模型,而是一个综述性的工作。其技术框架主要体现在对现有方法的分类和组织上。具体来说,论文将方法分为五个层级:第一级是重建低级3D属性,如深度、姿势和点云图;第二级是重建3D场景组件,如对象、人类和结构;第三级是重建4D动态场景;第四级是建模场景组件之间的交互;第五级是结合物理定律和约束。
关键创新:论文的关键创新在于提出了一个清晰的4D空间智能层级结构,这为理解和组织现有的方法提供了一个新的视角。与现有综述相比,该论文更加关注方法之间的层级关系,并对每个层级所面临的挑战进行了深入的分析。
关键设计:论文的关键设计在于如何定义和划分这五个层级。作者根据方法所能重建的场景复杂度和所能建模的交互关系,将方法划分到不同的层级中。这种划分方式既考虑了方法的底层技术,也考虑了方法的高层语义,使得整个层级结构具有较强的解释性和指导性。
🖼️ 关键图片
📊 实验亮点
该综述论文的主要亮点在于对现有4D空间智能重建方法进行了系统性的分类和组织,提出了一个由五个层级构成的框架,清晰地展示了该领域的发展脉络和未来方向。该框架能够帮助研究人员更好地理解不同方法之间的关系,并识别每个层级所面临的关键挑战,从而促进该领域的发展。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发等娱乐领域,提升视觉效果和真实感。在机器人、自动驾驶等具身智能领域,能够帮助智能体更好地理解和交互周围环境,实现更高级别的智能行为。此外,该综述对相关研究人员具有重要的参考价值,能够帮助他们快速了解领域现状和发展趋势。
📄 摘要(原文)
Reconstructing 4D spatial intelligence from visual observations has long been a central yet challenging task in computer vision, with broad real-world applications. These range from entertainment domains like movies, where the focus is often on reconstructing fundamental visual elements, to embodied AI, which emphasizes interaction modeling and physical realism. Fueled by rapid advances in 3D representations and deep learning architectures, the field has evolved quickly, outpacing the scope of previous surveys. Additionally, existing surveys rarely offer a comprehensive analysis of the hierarchical structure of 4D scene reconstruction. To address this gap, we present a new perspective that organizes existing methods into five progressive levels of 4D spatial intelligence: (1) Level 1 -- reconstruction of low-level 3D attributes (e.g., depth, pose, and point maps); (2) Level 2 -- reconstruction of 3D scene components (e.g., objects, humans, structures); (3) Level 3 -- reconstruction of 4D dynamic scenes; (4) Level 4 -- modeling of interactions among scene components; and (5) Level 5 -- incorporation of physical laws and constraints. We conclude the survey by discussing the key challenges at each level and highlighting promising directions for advancing toward even richer levels of 4D spatial intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence.