RingMo-Agent: A Unified Remote Sensing Foundation Model for Multi-Platform and Multi-Modal Reasoning
作者: Huiyang Hu, Peijin Wang, Yingchao Feng, Kaiwen Wei, Wenxin Yin, Wenhui Diao, Mengyu Wang, Hanbo Bi, Kaiyue Kang, Tong Ling, Kun Fu, Xian Sun
分类: cs.CV
发布日期: 2025-07-28 (更新: 2026-01-05)
备注: 23 pages, 6 figures, 20 tables
💡 一句话要点
提出RingMo-Agent,用于多平台多模态遥感图像的统一推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像 多模态学习 视觉语言模型 统一框架 跨平台 遥感数据集 表征学习 任务建模
📋 核心要点
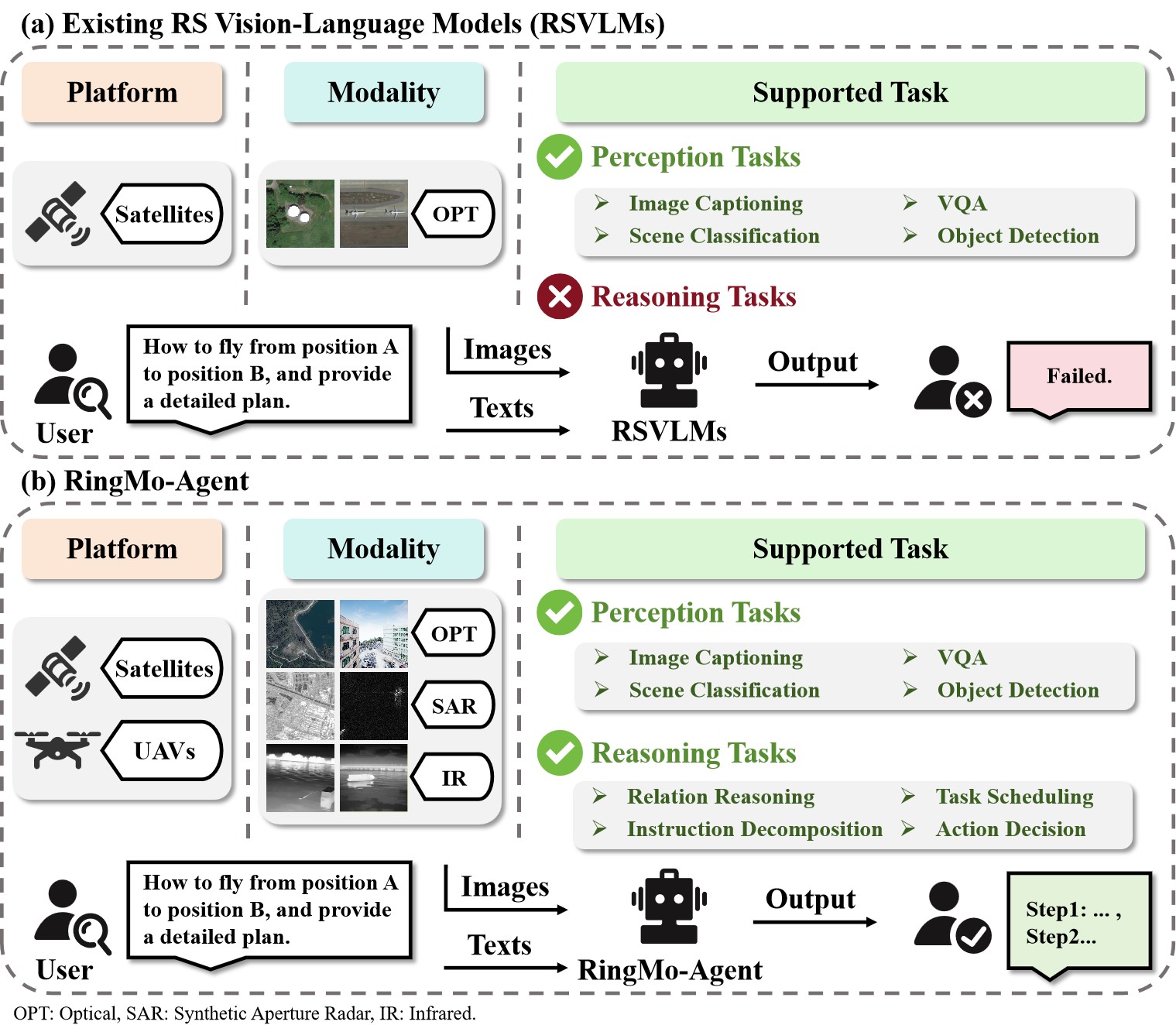
- 现有遥感视觉-语言研究依赖同质数据,且局限于分类或描述等传统任务,缺乏处理复杂场景的统一框架。
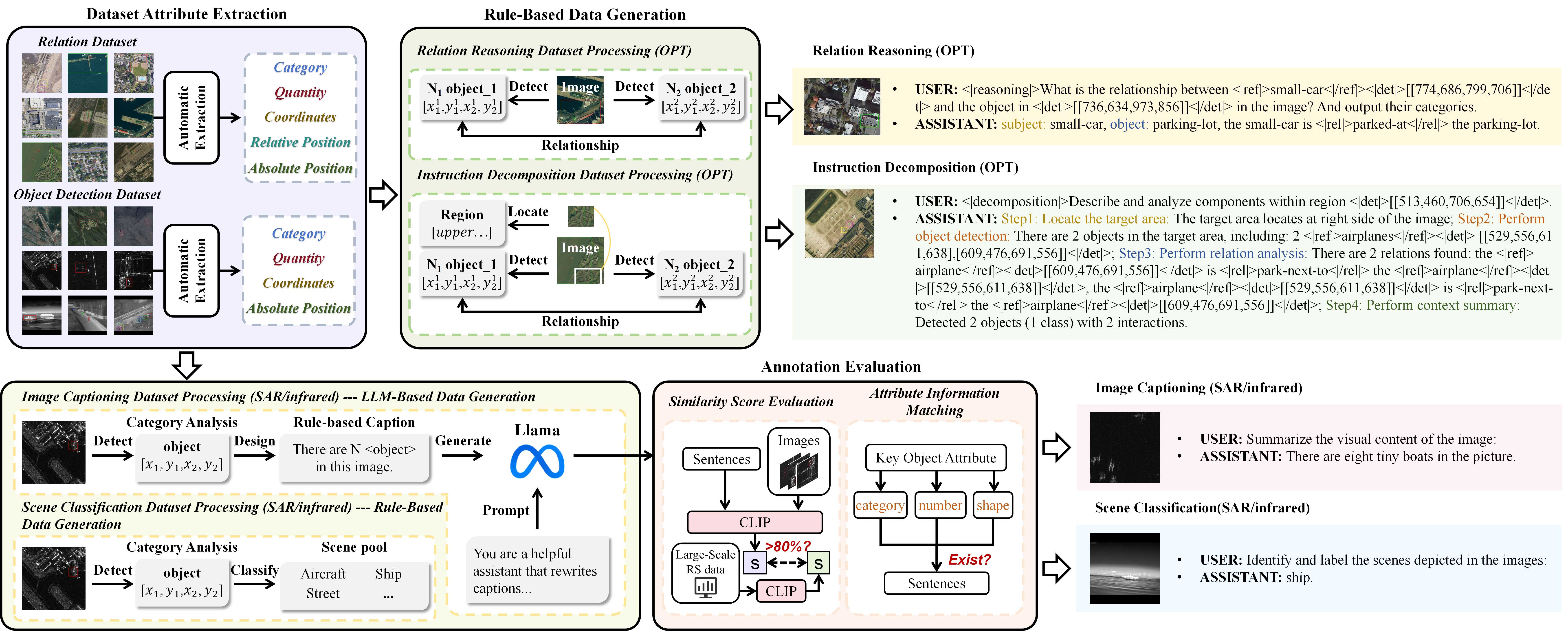
- RingMo-Agent通过大规模多模态数据集RS-VL3M,模态自适应表示学习,以及基于token的任务统一建模,实现复杂遥感场景的理解与推理。
- 实验证明RingMo-Agent在视觉理解和复杂分析任务中有效,并在不同平台和模态上表现出强大的泛化能力。
📝 摘要(中文)
本文提出了RingMo-Agent,一个旨在处理多模态和多平台遥感数据的模型,能够根据用户文本指令执行感知和推理任务。与现有模型相比,RingMo-Agent的优势在于:1) 拥有一个名为RS-VL3M的大规模视觉-语言数据集,包含超过300万个图像-文本对,涵盖来自卫星和无人机平台的光学、SAR和红外模态,覆盖感知和具有挑战性的推理任务;2) 通过结合分离的嵌入层来构建异构模态的独立特征并减少跨模态干扰,从而学习模态自适应表示;3) 通过引入特定于任务的token并采用基于token的高维隐藏状态解码机制来统一任务建模,该机制专为长时程空间任务而设计。在各种遥感视觉-语言任务上的大量实验表明,RingMo-Agent不仅在视觉理解和复杂的分析任务中有效,而且在不同的平台和传感模态中表现出很强的泛化能力。
🔬 方法详解
问题定义:现有遥感视觉-语言模型主要依赖于相对同质的数据源,并且局限于传统的视觉感知任务,如分类或图像描述。这些方法难以作为统一的框架,有效地处理来自不同来源的遥感图像,无法满足实际应用中复杂场景的需求。
核心思路:RingMo-Agent的核心思路是构建一个能够处理多模态、多平台遥感数据的统一模型,通过大规模数据集训练,学习模态自适应的表示,并采用统一的任务建模方法,从而实现对遥感图像的感知和推理。这样设计的目的是为了解决现有模型在数据异构性和任务多样性方面的局限性。
技术框架:RingMo-Agent的整体框架包括以下几个主要模块:1) 大规模多模态遥感数据集RS-VL3M,用于模型训练;2) 模态自适应表示学习模块,通过分离的嵌入层处理不同模态的数据;3) 任务统一建模模块,引入任务特定的token,并采用基于token的高维隐藏状态解码机制。整个流程是,首先将多模态遥感数据输入到模态自适应表示学习模块,然后将学习到的表示输入到任务统一建模模块,最后根据用户指令输出结果。
关键创新:RingMo-Agent的关键创新点在于:1) 构建了大规模多模态遥感数据集RS-VL3M,为模型训练提供了丰富的数据;2) 提出了模态自适应表示学习方法,能够有效处理不同模态的数据;3) 采用了基于token的任务统一建模方法,能够处理多种遥感任务。与现有方法相比,RingMo-Agent能够更好地处理多模态、多平台的遥感数据,并能够执行更复杂的推理任务。
关键设计:在模态自适应表示学习中,使用了分离的嵌入层来处理不同模态的数据,以减少跨模态干扰。在任务统一建模中,引入了任务特定的token,并采用了基于token的高维隐藏状态解码机制,以实现对长时程空间任务的有效处理。具体的损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文构建了包含超过300万图像-文本对的大规模遥感数据集RS-VL3M。实验结果表明,RingMo-Agent在多种遥感视觉-语言任务上表现出色,证明了其在视觉理解和复杂分析任务中的有效性,以及在不同平台和模态上的强大泛化能力。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
RingMo-Agent可应用于灾害监测、城市规划、农业估产、环境监测等领域。通过统一处理多源遥感数据,能够更全面、准确地理解地表信息,为决策提供支持,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Remote sensing (RS) images from multiple modalities and platforms exhibit diverse details due to differences in sensor characteristics and imaging perspectives. Existing vision-language research in RS largely relies on relatively homogeneous data sources. Moreover, they still remain limited to conventional visual perception tasks such as classification or captioning. As a result, these methods fail to serve as a unified and standalone framework capable of effectively handling RS imagery from diverse sources in real-world applications. To address these issues, we propose RingMo-Agent, a model designed to handle multi-modal and multi-platform data that performs perception and reasoning tasks based on user textual instructions. Compared with existing models, RingMo-Agent 1) is supported by a large-scale vision-language dataset named RS-VL3M, comprising over 3 million image-text pairs, spanning optical, SAR, and infrared (IR) modalities collected from both satellite and UAV platforms, covering perception and challenging reasoning tasks; 2) learns modality adaptive representations by incorporating separated embedding layers to construct isolated features for heterogeneous modalities and reduce cross-modal interference; 3) unifies task modeling by introducing task-specific tokens and employing a token-based high-dimensional hidden state decoding mechanism designed for long-horizon spatial tasks. Extensive experiments on various RS vision-language tasks demonstrate that RingMo-Agent not only proves effective in both visual understanding and sophisticated analytical tasks, but also exhibits strong generalizability across different platforms and sensing modalities.