TransPrune: Token Transition Pruning for Efficient Large Vision-Language Model
作者: Ao Li, Yuxiang Duan, Jinghui Zhang, Congbo Ma, Yutong Xie, Gustavo Carneiro, Mohammad Yaqub, Hu Wang
分类: cs.CV, cs.AI
发布日期: 2025-07-28 (更新: 2025-11-17)
🔗 代码/项目: GITHUB
💡 一句话要点
TransPrune:面向高效大型视觉-语言模型的Token转移剪枝方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 Token剪枝 模型压缩 推理加速 Token转移变异 指令引导注意力 多模态学习
📋 核心要点
- 现有基于注意力的token剪枝方法存在位置偏差等局限性,难以准确评估token的重要性。
- TransPrune通过分析token表示的转移变化,结合Token转移变异(TTV)和指令引导注意力(IGA)来判断token重要性。
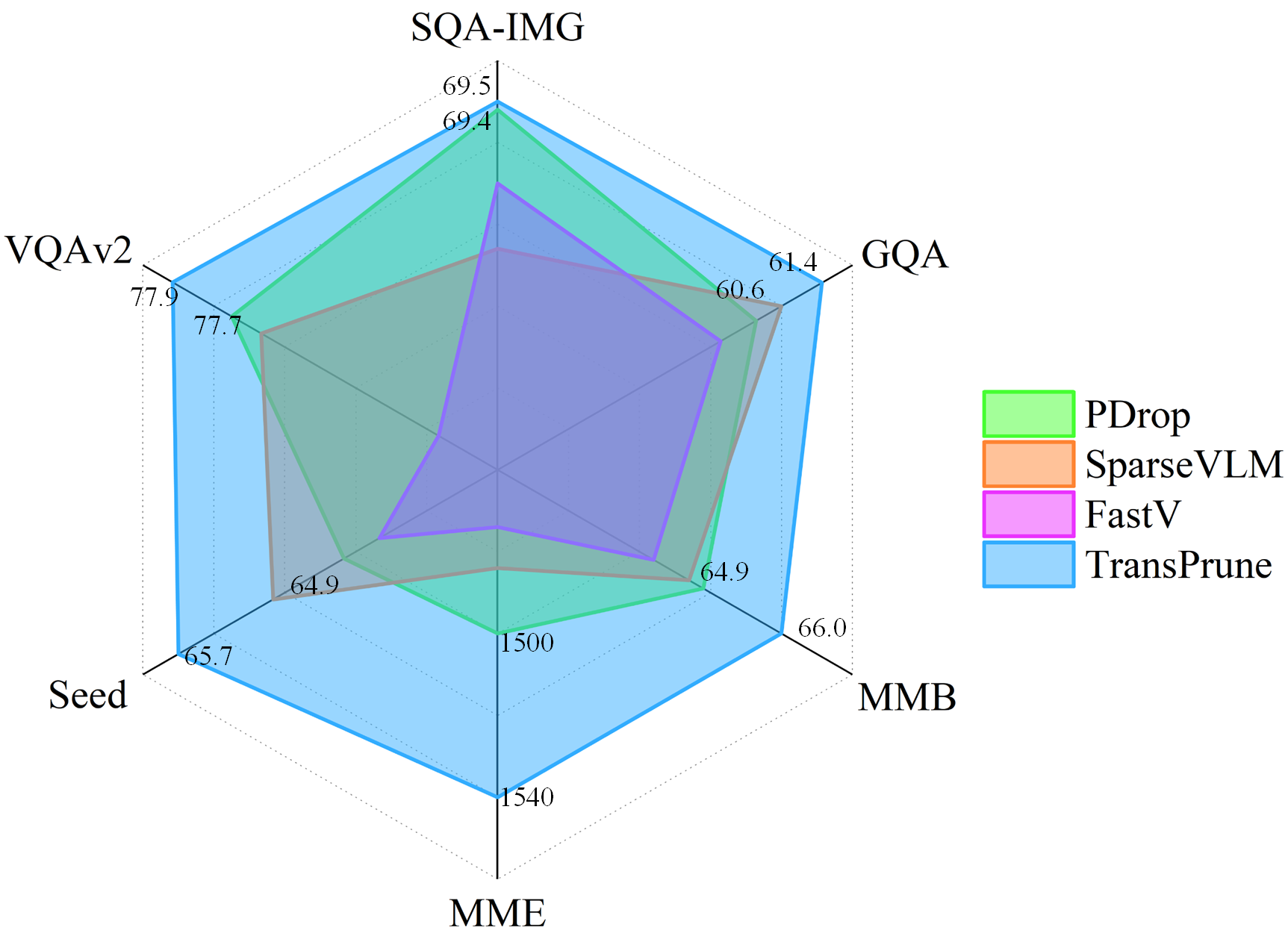
- 实验表明,TransPrune在保持性能的同时,显著降低了推理计算量,且TTV可独立作为有效剪枝标准。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)在多模态学习方面取得了显著进展,但由于视觉token数量庞大,计算成本很高,因此需要进行token剪枝以提高推理效率。关键挑战在于识别哪些token真正重要。现有方法大多依赖于基于注意力的标准来估计token的重要性,但它们固有地存在一些局限性,例如位置偏差。本文从LVLMs中token转移的新视角探索token的重要性。我们观察到token表示的转移提供了语义信息的有意义的信号。基于此,我们提出TransPrune,一种无需训练且高效的token剪枝方法。具体而言,TransPrune通过结合Token转移变异(TTV)——衡量token表示的大小和方向的变化——和指令引导注意力(IGA)——衡量指令通过注意力对图像token的关注程度——来评估token的重要性,从而逐步剪枝token。大量实验表明,TransPrune在八个基准测试中实现了与原始LVLMs(如LLaVA-v1.5和LLaVA-Next)相当的多模态性能,同时将推理TFLOPs降低了一半以上。此外,仅TTV就可以作为一种有效的标准,无需依赖注意力,即可实现与基于注意力的方法相当的性能。代码将在论文被接收后公开。
🔬 方法详解
问题定义:大型视觉-语言模型(LVLMs)由于其庞大的视觉token数量,在推理时面临着巨大的计算负担。现有的token剪枝方法,尤其是那些依赖于注意力的,往往存在位置偏差等问题,导致无法准确地识别和去除不重要的token,从而影响模型的性能和效率。
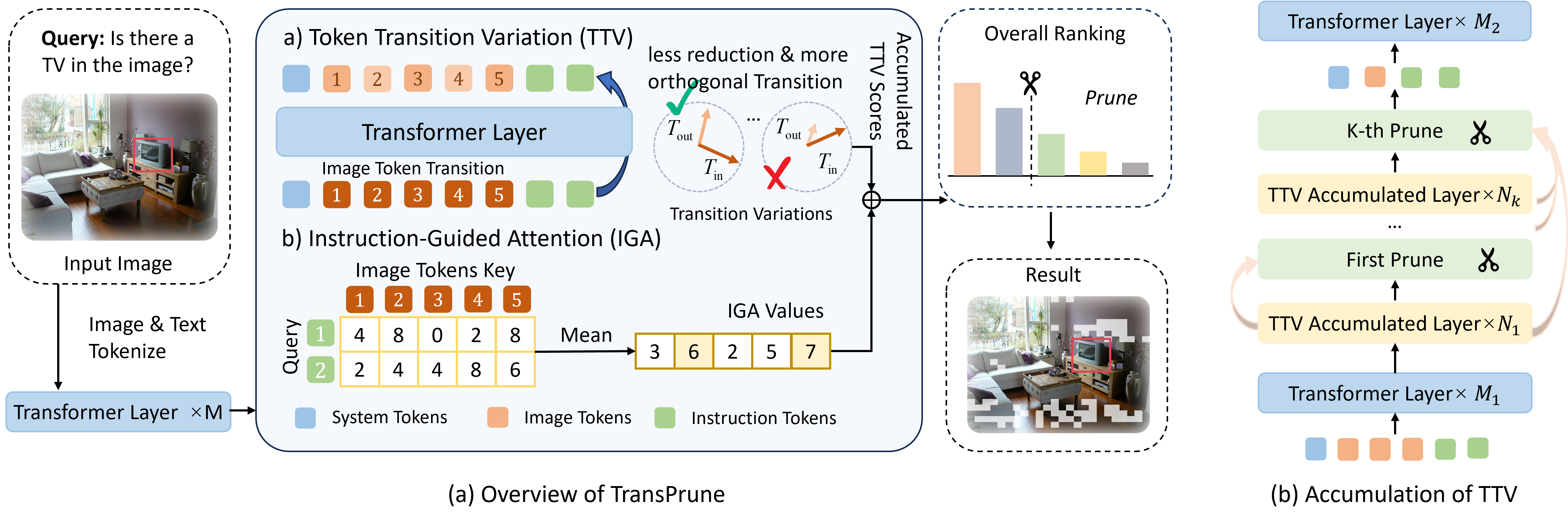
核心思路:TransPrune的核心思路是利用token表示在模型中的转移变化来衡量token的重要性。作者观察到,token表示的转移包含了丰富的语义信息,因此可以通过分析token表示的大小和方向变化来判断哪些token对于模型的理解和推理至关重要。此外,结合指令引导注意力(IGA)可以进一步提高剪枝的准确性。
技术框架:TransPrune是一个训练无关的token剪枝方法,其主要流程如下:1)输入图像和指令;2)通过LVLM提取视觉token表示;3)计算Token转移变异(TTV),衡量token表示在不同层之间的变化;4)计算指令引导注意力(IGA),衡量指令对图像token的关注程度;5)结合TTV和IGA,计算每个token的重要性得分;6)根据重要性得分,逐步剪枝不重要的token。
关键创新:TransPrune的关键创新在于提出了Token转移变异(TTV)这一概念,并将其作为token重要性的衡量标准。与传统的基于注意力的方法不同,TTV关注的是token表示在模型内部的动态变化,从而能够更准确地捕捉token的语义信息。此外,TransPrune是一种无需训练的方法,避免了额外的训练成本和数据依赖。
关键设计:TransPrune的关键设计包括:1)Token转移变异(TTV)的计算方式,通过计算token表示在相邻层之间的欧几里得距离和方向余弦的加权和来衡量token的变化;2)指令引导注意力(IGA)的计算方式,通过平均指令对图像token的注意力权重来衡量指令对token的关注程度;3)重要性得分的计算方式,通过加权平均TTV和IGA来得到最终的token重要性得分;4)剪枝策略,逐步剪枝重要性得分低的token,并根据实际情况调整剪枝比例。
🖼️ 关键图片

📊 实验亮点
TransPrune在多个基准测试中取得了与原始LLaVA-v1.5和LLaVA-Next相当的性能,同时将推理TFLOPs降低了一半以上。更重要的是,实验证明仅使用TTV作为剪枝标准,也能达到与基于注意力的方法相媲美的性能,这突显了TTV的有效性和通用性。
🎯 应用场景
TransPrune可应用于各种需要高效推理的大型视觉-语言模型,例如移动设备上的智能助手、自动驾驶系统中的视觉理解模块、以及需要快速响应的实时图像分析应用。通过降低计算成本,TransPrune可以使这些模型在资源受限的环境中更有效地运行,并加速其在实际场景中的部署。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) have advanced multimodal learning but face high computational costs due to the large number of visual tokens, motivating token pruning to improve inference efficiency. The key challenge lies in identifying which tokens are truly important. Most existing approaches rely on attention-based criteria to estimate token importance. However, they inherently suffer from certain limitations, such as positional bias. In this work, we explore a new perspective on token importance based on token transitions in LVLMs. We observe that the transition of token representations provides a meaningful signal of semantic information. Based on this insight, we propose TransPrune, a training-free and efficient token pruning method. Specifically, TransPrune progressively prunes tokens by assessing their importance through a combination of Token Transition Variation (TTV)-which measures changes in both the magnitude and direction of token representations-and Instruction-Guided Attention (IGA), which measures how strongly the instruction attends to image tokens via attention. Extensive experiments demonstrate that TransPrune achieves comparable multimodal performance to original LVLMs, such as LLaVA-v1.5 and LLaVA-Next, across eight benchmarks, while reducing inference TFLOPs by more than half. Moreover, TTV alone can serve as an effective criterion without relying on attention, achieving performance comparable to attention-based methods. The code will be made publicly available upon acceptance of the paper at https://github.com/liaolea/TransPrune.