VESPA: Towards un(Human)supervised Open-World Pointcloud Labeling for Autonomous Driving
作者: Levente Tempfli, Esteban Rivera, Markus Lienkamp
分类: cs.CV
发布日期: 2025-07-27
💡 一句话要点
VESPA:面向自动驾驶的无监督开放世界点云标注方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 点云标注 多模态融合 视觉-语言模型 开放世界 无监督学习
📋 核心要点
- 现有基于激光雷达的自动标注方法受限于数据稀疏、遮挡等问题,且语义信息不足,难以进行细粒度的对象识别。
- VESPA融合激光雷达的几何精度和相机图像的语义信息,利用视觉-语言模型实现开放词汇的对象标注和检测质量提升。
- VESPA在Nuscenes数据集上取得了显著成果,对象发现AP达到52.95%,多类对象检测AP达到46.54%,无需人工标注或高清地图。
📝 摘要(中文)
自动驾驶的数据采集正在快速发展,但人工标注,特别是3D标注,由于其高成本和劳动密集性,仍然是一个主要的瓶颈。自动标注已成为一种可扩展的替代方案,允许以最少的人工干预为点云生成标签。虽然基于激光雷达的自动标注方法利用了几何信息,但它们受到激光雷达数据固有局限性的影响,如稀疏性、遮挡和不完整的物体观测。此外,这些方法通常以类无关的方式运行,提供的语义粒度有限。为了解决这些挑战,我们引入了VESPA,一种多模态自动标注流程,它融合了激光雷达的几何精度和相机图像的语义丰富性。我们的方法利用视觉-语言模型(VLM)来实现开放词汇对象标注,并直接在点云域中改进检测质量。VESPA支持发现新的类别,并生成高质量的3D伪标签,而无需ground-truth标注或高清地图。在Nuscenes数据集上,VESPA在对象发现方面实现了52.95%的AP,在多类对象检测方面实现了高达46.54%的AP,展示了在可扩展的3D场景理解方面的强大性能。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景下3D点云数据标注成本高昂的问题。现有的基于激光雷达的自动标注方法存在数据稀疏、遮挡严重、语义信息不足等痛点,难以实现高精度、细粒度的开放世界对象标注。
核心思路:论文的核心思路是融合激光雷达的几何信息和相机图像的语义信息,利用视觉-语言模型(VLM)的强大语义理解能力,实现开放词汇的对象标注,并直接在点云域中提升检测质量。通过多模态融合,克服单一模态的局限性。
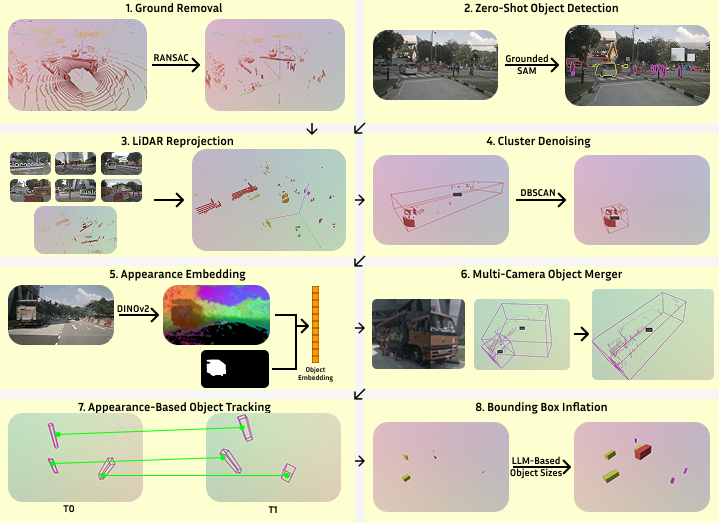
技术框架:VESPA的整体框架是一个多模态自动标注流程,主要包含以下几个阶段:1) 数据采集:利用激光雷达和相机同步采集数据。2) 视觉-语言模型推理:使用VLM对相机图像进行分析,提取场景中的对象信息和语义描述。3) 点云投影与融合:将相机图像的语义信息投影到点云空间,并将激光雷达的几何信息与图像的语义信息进行融合。4) 伪标签生成与优化:基于融合后的信息,生成3D伪标签,并利用点云信息对伪标签进行优化,提高标注质量。
关键创新:VESPA的关键创新在于:1) 提出了一种多模态融合的自动标注框架,有效结合了激光雷达的几何精度和相机图像的语义信息。2) 利用视觉-语言模型实现了开放词汇的对象标注,突破了传统方法的类别限制。3) 提出了一种直接在点云域中优化检测质量的方法,提高了标注的准确性和鲁棒性。
关键设计:论文中关于VLM的选择、多模态融合的具体方法、伪标签优化策略等关键设计细节未详细描述,属于未知信息。但可以推测,VLM的选择会影响最终的标注效果,多模态融合需要考虑不同模态数据之间的对齐问题,伪标签优化需要设计合适的损失函数和优化算法。
🖼️ 关键图片
📊 实验亮点
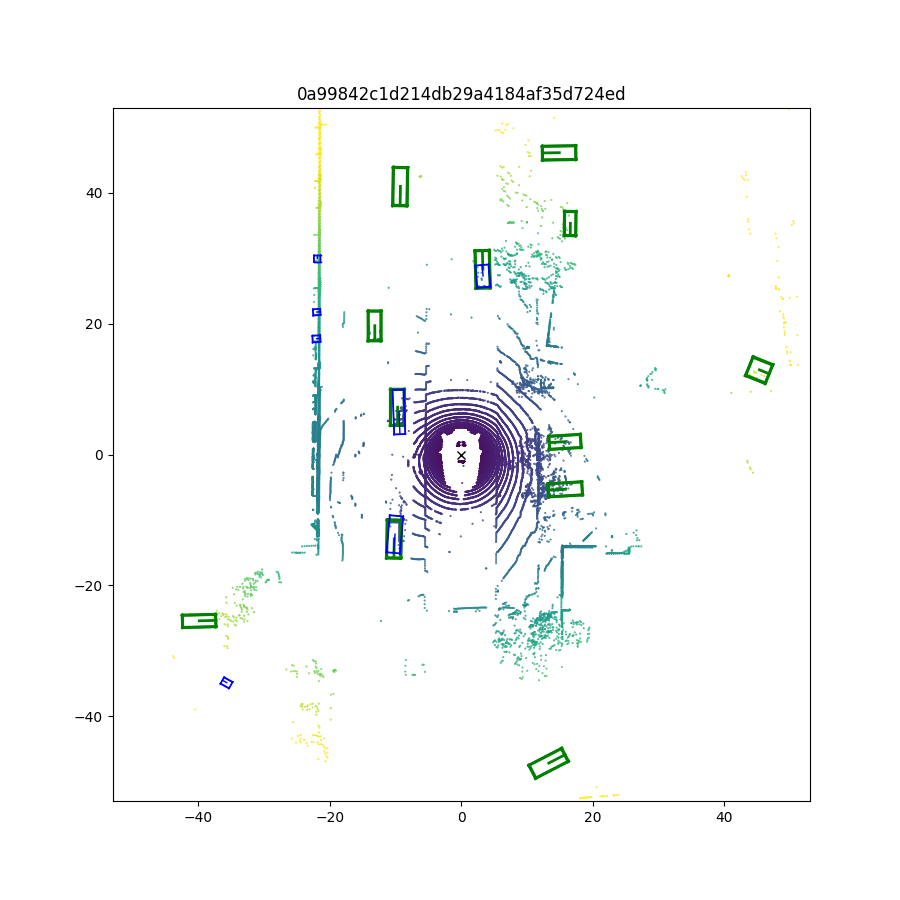
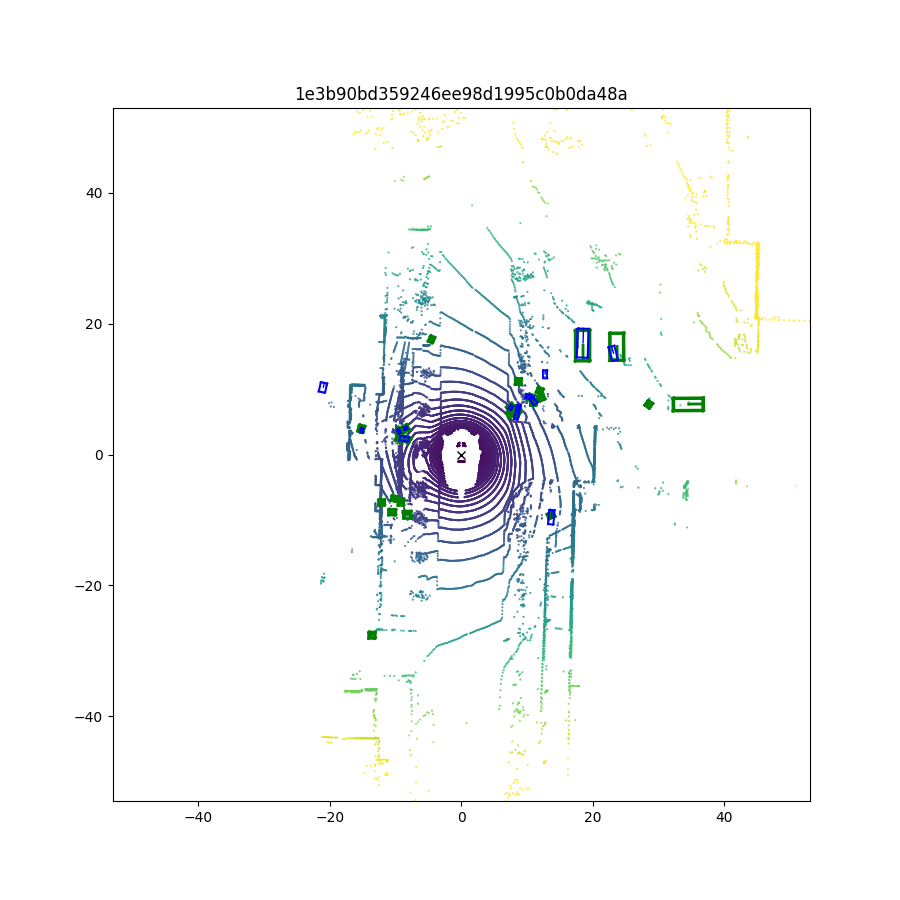
VESPA在Nuscenes数据集上取得了显著的实验结果。在对象发现任务中,VESPA实现了52.95%的AP,表明其具有强大的开放世界对象识别能力。在多类对象检测任务中,VESPA实现了高达46.54%的AP,证明了其在3D场景理解方面的优越性能。这些结果表明,VESPA在无需人工标注或高清地图的情况下,能够生成高质量的3D伪标签。
🎯 应用场景
VESPA可应用于自动驾驶、机器人导航、智能交通等领域,降低3D数据标注成本,加速相关技术的研发和部署。通过开放词汇的对象标注能力,可以提升系统对复杂环境的感知能力,增强系统的适应性和鲁棒性。未来,该技术有望应用于更广泛的场景,例如智慧城市、虚拟现实等。
📄 摘要(原文)
Data collection for autonomous driving is rapidly accelerating, but manual annotation, especially for 3D labels, remains a major bottleneck due to its high cost and labor intensity. Autolabeling has emerged as a scalable alternative, allowing the generation of labels for point clouds with minimal human intervention. While LiDAR-based autolabeling methods leverage geometric information, they struggle with inherent limitations of lidar data, such as sparsity, occlusions, and incomplete object observations. Furthermore, these methods typically operate in a class-agnostic manner, offering limited semantic granularity. To address these challenges, we introduce VESPA, a multimodal autolabeling pipeline that fuses the geometric precision of LiDAR with the semantic richness of camera images. Our approach leverages vision-language models (VLMs) to enable open-vocabulary object labeling and to refine detection quality directly in the point cloud domain. VESPA supports the discovery of novel categories and produces high-quality 3D pseudolabels without requiring ground-truth annotations or HD maps. On Nuscenes dataset, VESPA achieves an AP of 52.95% for object discovery and up to 46.54% for multiclass object detection, demonstrating strong performance in scalable 3D scene understanding. Code will be available upon acceptance.