When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
作者: Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, Huan Wang
分类: cs.CV
发布日期: 2025-07-27 (更新: 2025-08-28)
备注: For ongoing updates and to track the latest advances in this promising area, we maintain a public repository: https://github.com/cokeshao/Awesome-Multimodal-Token-Compression
💡 一句话要点
首个多模态长上下文Token压缩综述,涵盖图像、视频与音频
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 长上下文 Token压缩 图像压缩 视频压缩 音频压缩 大语言模型 自注意力机制
📋 核心要点
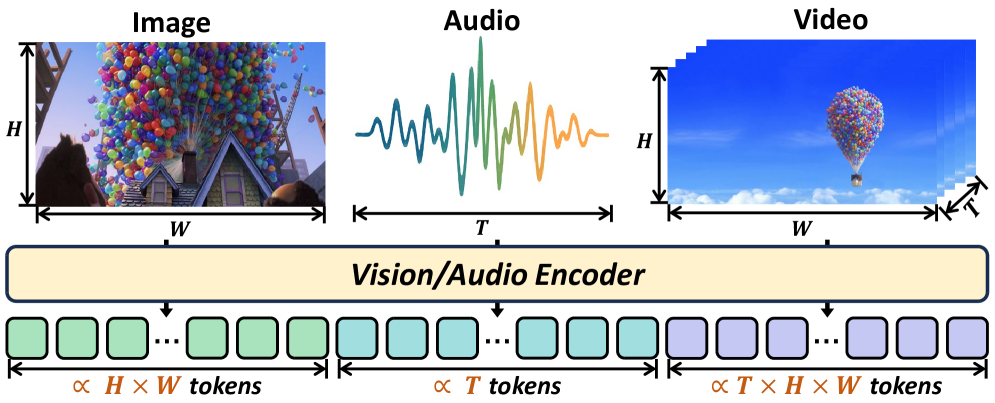
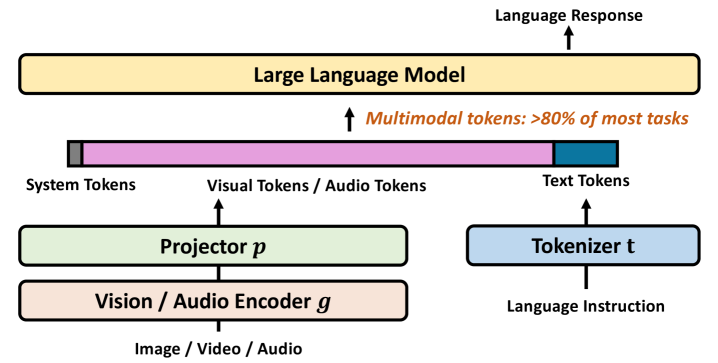
- 多模态大语言模型处理长上下文时,自注意力机制的计算复杂度呈平方级增长,成为性能瓶颈。
- 本文对多模态长上下文Token压缩方法进行了系统性综述,根据模态类型和压缩机制进行分类。
- 该综述旨在总结现有进展,识别关键挑战,并为该领域未来的研究方向提供参考,并维护公开仓库跟踪最新进展。
📝 摘要(中文)
多模态大型语言模型(MLLM)取得了显著进展,这主要归功于它们处理日益增长的复杂上下文的能力,例如高分辨率图像、扩展的视频序列和冗长的音频输入。虽然这种能力显著增强了MLLM的能力,但也带来了巨大的计算挑战,这主要是由于自注意力机制在大量输入token下的二次复杂度。为了缓解这些瓶颈,token压缩已成为一种有希望且至关重要的方法,可以有效地减少训练和推理期间的token数量。在本文中,我们首次对新兴的多模态长上下文token压缩领域进行了系统的综述和总结。我们认识到有效的压缩策略与每种模态的独特特征和冗余密切相关,因此我们根据其主要数据重点对现有方法进行分类,使研究人员能够快速访问和学习针对其特定兴趣领域量身定制的方法:(1)以图像为中心的压缩,解决视觉数据中的空间冗余;(2)以视频为中心的压缩,解决动态序列中的时空冗余;(3)以音频为中心的压缩,处理声学信号中的时间和频谱冗余。除了这种模态驱动的分类之外,我们还根据其底层机制剖析了这些方法,包括基于变换、基于相似性、基于注意力和基于查询的方法。通过提供全面而结构化的概述,本综述旨在巩固当前的进展,识别关键挑战,并激发这个快速发展领域未来的研究方向。我们还维护一个公共存储库,以不断跟踪和更新这个有希望的领域的最新进展。
🔬 方法详解
问题定义:多模态大语言模型在处理长上下文(如高分辨率图像、长视频、长音频)时,由于自注意力机制的计算复杂度是token数量的平方级别,导致计算成本显著增加,成为性能瓶颈。现有的方法缺乏对不同模态数据特性和冗余信息的有效压缩策略。
核心思路:本文的核心思路是对现有的多模态长上下文token压缩方法进行系统性的分类和总结,并从模态类型(图像、视频、音频)和压缩机制(基于变换、基于相似性、基于注意力、基于查询)两个维度进行分析。通过这种分类,研究人员可以更容易地找到适合特定模态和任务的压缩方法。
技术框架:本文的综述框架主要包含以下几个部分:首先,介绍多模态长上下文学习的背景和挑战;其次,根据数据模态类型将现有方法分为图像中心、视频中心和音频中心三类;然后,在每一类中,又根据压缩机制的不同,进一步细分方法;最后,总结了当前研究的进展、挑战和未来方向。同时,维护一个公开的资源库,持续更新最新的研究进展。
关键创新:本文最重要的创新点在于,它是第一个对多模态长上下文token压缩方法进行系统性综述的工作。它不仅对现有方法进行了全面的总结和分类,而且还从模态类型和压缩机制两个维度进行了深入的分析,为研究人员提供了一个清晰的路线图。
关键设计:本文的关键设计在于其分类体系。根据模态类型进行分类,是因为不同模态的数据具有不同的特性和冗余信息,需要采用不同的压缩策略。例如,图像数据主要存在空间冗余,视频数据存在时空冗余,而音频数据存在时间和频谱冗余。根据压缩机制进行分类,是因为不同的压缩机制具有不同的优缺点,适用于不同的场景。例如,基于变换的方法可以有效地去除高频噪声,基于相似性的方法可以有效地去除冗余信息,基于注意力的方法可以自适应地选择重要的token,而基于查询的方法可以快速地检索相关的token。
🖼️ 关键图片
📊 实验亮点
本文是首个针对多模态长上下文Token压缩的系统性综述,它全面梳理了图像、视频和音频三种模态下的Token压缩方法,并从数据模态和压缩机制两个维度进行了深入分析。该综述为研究人员提供了一个清晰的路线图,有助于他们快速了解该领域的研究进展,并找到适合自己研究方向的方法。
🎯 应用场景
该研究成果可广泛应用于需要处理长上下文多模态数据的场景,例如:视频理解、医学影像分析、语音识别、自动驾驶等。通过token压缩,可以显著降低计算成本,提高模型推理速度,使得多模态大语言模型能够更好地应用于实际问题中,并推动相关领域的发展。
📄 摘要(原文)
Multimodal large language models (MLLMs) have made remarkable strides, largely driven by their ability to process increasingly long and complex contexts, such as high-resolution images, extended video sequences, and lengthy audio input. While this ability significantly enhances MLLM capabilities, it introduces substantial computational challenges, primarily due to the quadratic complexity of self-attention mechanisms with numerous input tokens. To mitigate these bottlenecks, token compression has emerged as an auspicious and critical approach, efficiently reducing the number of tokens during both training and inference. In this paper, we present the first systematic survey and synthesis of the burgeoning field of multimodal long context token compression. Recognizing that effective compression strategies are deeply tied to the unique characteristics and redundancies of each modality, we categorize existing approaches by their primary data focus, enabling researchers to quickly access and learn methods tailored to their specific area of interest: (1) image-centric compression, which addresses spatial redundancy in visual data; (2) video-centric compression, which tackles spatio-temporal redundancy in dynamic sequences; and (3) audio-centric compression, which handles temporal and spectral redundancy in acoustic signals. Beyond this modality-driven categorization, we further dissect methods based on their underlying mechanisms, including transformation-based, similarity-based, attention-based, and query-based approaches. By providing a comprehensive and structured overview, this survey aims to consolidate current progress, identify key challenges, and inspire future research directions in this rapidly evolving domain. We also maintain a public repository to continuously track and update the latest advances in this promising area.