Predicting Brain Responses To Natural Movies With Multimodal LLMs
作者: Cesar Kadir Torrico Villanueva, Jiaxin Cindy Tu, Mihir Tripathy, Connor Lane, Rishab Iyer, Paul S. Scotti
分类: cs.CV, cs.AI, q-bio.NC
发布日期: 2025-07-26
备注: Code available at https://github.com/MedARC-AI/algonauts2025
💡 一句话要点
利用多模态LLM预测自然电影刺激下的大脑反应,在Algonauts 2025挑战赛中排名第四。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 大脑反应预测 自然电影 深度学习 fMRI 预训练模型 Algonauts挑战赛
📋 核心要点
- 现有方法难以有效利用多模态信息预测大脑对自然电影的反应,泛化能力受限。
- 论文提出一种多模态融合框架,结合视频、语音、文本等多种模态的预训练模型特征。
- 实验结果表明,该方法在预测大脑反应方面具有良好的泛化能力,并在Algonauts 2025挑战赛中取得第四名。
📝 摘要(中文)
本文介绍了MedARC团队在Algonauts 2025挑战赛中的解决方案。该方案利用了来自多个先进预训练模型的多模态表征,包括视频(V-JEPA2)、语音(Whisper)、文本(Llama 3.2)、视觉-文本(InternVL3)和视觉-文本-音频(Qwen2.5-Omni)。从这些模型中提取的特征被线性投影到一个潜在空间,在时间上与fMRI时间序列对齐,最后通过一个轻量级编码器映射到皮层区域,该编码器包含一个共享组头和特定于受试者的残差头。作者在不同的超参数设置下训练了数百个模型变体,在保留的电影上进行了验证,并组装了针对每个受试者每个区域的集成模型。最终提交在未见过的分布外电影测试集上实现了0.2085的平均皮尔逊相关系数,使团队在该比赛中获得第四名。文章还讨论了一个本可以提升到第二名的最后一刻优化。结果表明,结合来自不同模态训练的模型特征,使用包含共享受试者和个体受试者组件的简单架构,以及进行全面的模型选择和集成,可以提高编码模型对新电影刺激的泛化能力。所有代码均可在GitHub上找到。
🔬 方法详解
问题定义:该论文旨在解决如何利用多模态信息更准确地预测大脑对自然电影刺激的反应。现有方法通常只关注单一模态的信息,或者简单地将多模态信息进行拼接,无法充分利用不同模态之间的互补性,导致预测精度和泛化能力不足。
核心思路:论文的核心思路是利用多个预训练好的大型语言模型(LLM)提取不同模态(视频、语音、文本等)的特征,并将这些特征融合到一个统一的潜在空间中。通过这种方式,模型可以学习到不同模态之间的关联,从而更准确地预测大脑的反应。
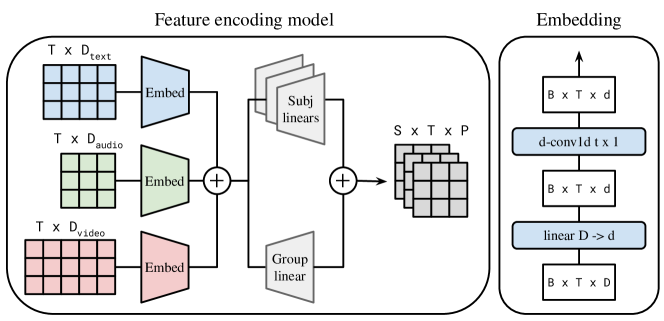
技术框架:整体框架包括以下几个主要步骤:1) 特征提取:使用V-JEPA2 (视频), Whisper (语音), Llama 3.2 (文本), InternVL3 (视觉-文本), 和 Qwen2.5-Omni (视觉-文本-音频) 等预训练模型提取多模态特征。2) 特征投影:将提取的特征线性投影到一个共享的潜在空间。3) 时间对齐:将特征与fMRI时间序列进行时间对齐。4) 编码器:使用一个轻量级的编码器将特征映射到皮层区域。该编码器包含一个共享组头(shared group head)和特定于受试者的残差头(subject-specific residual heads)。
关键创新:该论文的关键创新在于:1) 多模态特征融合:有效地融合了来自不同模态的预训练模型特征,充分利用了不同模态之间的互补性。2) 轻量级编码器:使用了一个包含共享组头和特定于受试者的残差头的轻量级编码器,提高了模型的泛化能力。3) 模型集成:通过训练数百个模型变体并进行集成,进一步提高了预测精度。
关键设计:编码器采用共享组头加个体残差头的结构,旨在学习跨个体共享的脑区响应模式,同时捕捉个体差异。模型训练过程中,作者探索了多种超参数设置,并通过交叉验证选择最优模型。损失函数未知,但目标是最小化预测的fMRI信号与实际fMRI信号之间的差异。
🖼️ 关键图片
📊 实验亮点
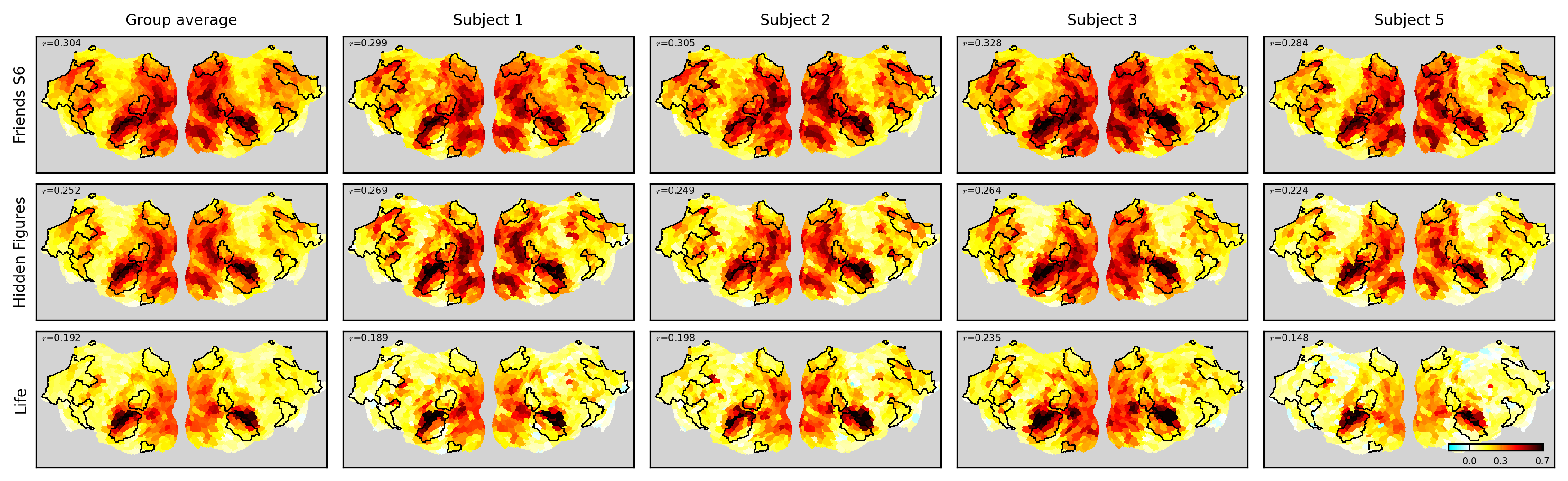
该方法在Algonauts 2025挑战赛中取得了第四名的成绩,平均皮尔逊相关系数为0.2085。作者还提到,如果采用最后一刻的优化方案,本可以提升到第二名。实验结果表明,该方法在预测大脑对自然电影刺激的反应方面具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于神经科学领域,帮助研究人员更深入地理解大脑如何处理多模态信息,以及不同脑区之间的相互作用。此外,该方法还可以用于开发更有效的脑机接口,例如,通过分析大脑对不同刺激的反应,实现对患者意图的解码和控制。
📄 摘要(原文)
We present MedARC's team solution to the Algonauts 2025 challenge. Our pipeline leveraged rich multimodal representations from various state-of-the-art pretrained models across video (V-JEPA2), speech (Whisper), text (Llama 3.2), vision-text (InternVL3), and vision-text-audio (Qwen2.5-Omni). These features extracted from the models were linearly projected to a latent space, temporally aligned to the fMRI time series, and finally mapped to cortical parcels through a lightweight encoder comprising a shared group head plus subject-specific residual heads. We trained hundreds of model variants across hyperparameter settings, validated them on held-out movies and assembled ensembles targeted to each parcel in each subject. Our final submission achieved a mean Pearson's correlation of 0.2085 on the test split of withheld out-of-distribution movies, placing our team in fourth place for the competition. We further discuss a last-minute optimization that would have raised us to second place. Our results highlight how combining features from models trained in different modalities, using a simple architecture consisting of shared-subject and single-subject components, and conducting comprehensive model selection and ensembling improves generalization of encoding models to novel movie stimuli. All code is available on GitHub.