LLMControl: Grounded Control of Text-to-Image Diffusion-based Synthesis with Multimodal LLMs
作者: Jiaze Wang, Rui Chen, Haowang Cui
分类: cs.CV
发布日期: 2025-07-26
💡 一句话要点
LLMControl:利用多模态LLM实现文本到图像扩散模型的可控生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 扩散模型 多模态LLM 空间控制 可控生成
📋 核心要点
- 现有空间控制的T2I扩散模型在处理复杂空间组合和多对象提示时,难以精确遵循控制条件。
- LLMControl利用多模态LLM作为全局控制器,增强语义描述,安排空间布局,并绑定对象属性,从而提升生成质量。
- 实验结果表明,LLMControl在各种预训练T2I模型上实现了与SOTA方法相比具有竞争力的合成质量。
📝 摘要(中文)
本文提出了一种名为LLM_Control的框架,旨在解决文本到图像(T2I)扩散模型中空间控制方法难以精确遵循控制条件并生成对应图像的问题,尤其是在处理包含多个对象或复杂空间组成的文本提示时。LLM_Control通过增强基础能力来精确地调节预训练的扩散模型,其中视觉条件和文本提示以互补的方式影响结构和外观的生成。该方法利用多模态LLM作为全局控制器来安排空间布局、增强语义描述并绑定对象属性。获得的控制信号被注入到去噪网络中,以根据新的采样约束重新聚焦和增强注意力图。大量的定性和定量实验表明,与其他最先进的方法相比,LLM_Control在各种预训练的T2I模型上实现了具有竞争力的合成质量。值得注意的是,LLM_Control允许处理大多数现有方法难以应对的具有挑战性的输入条件。
🔬 方法详解
问题定义:现有文本到图像扩散模型的空间控制方法在处理复杂场景(如多对象、复杂空间关系)时,无法精确地按照控制条件生成图像。这些方法难以准确理解和执行文本提示中蕴含的细粒度空间信息,导致生成图像与预期不符。
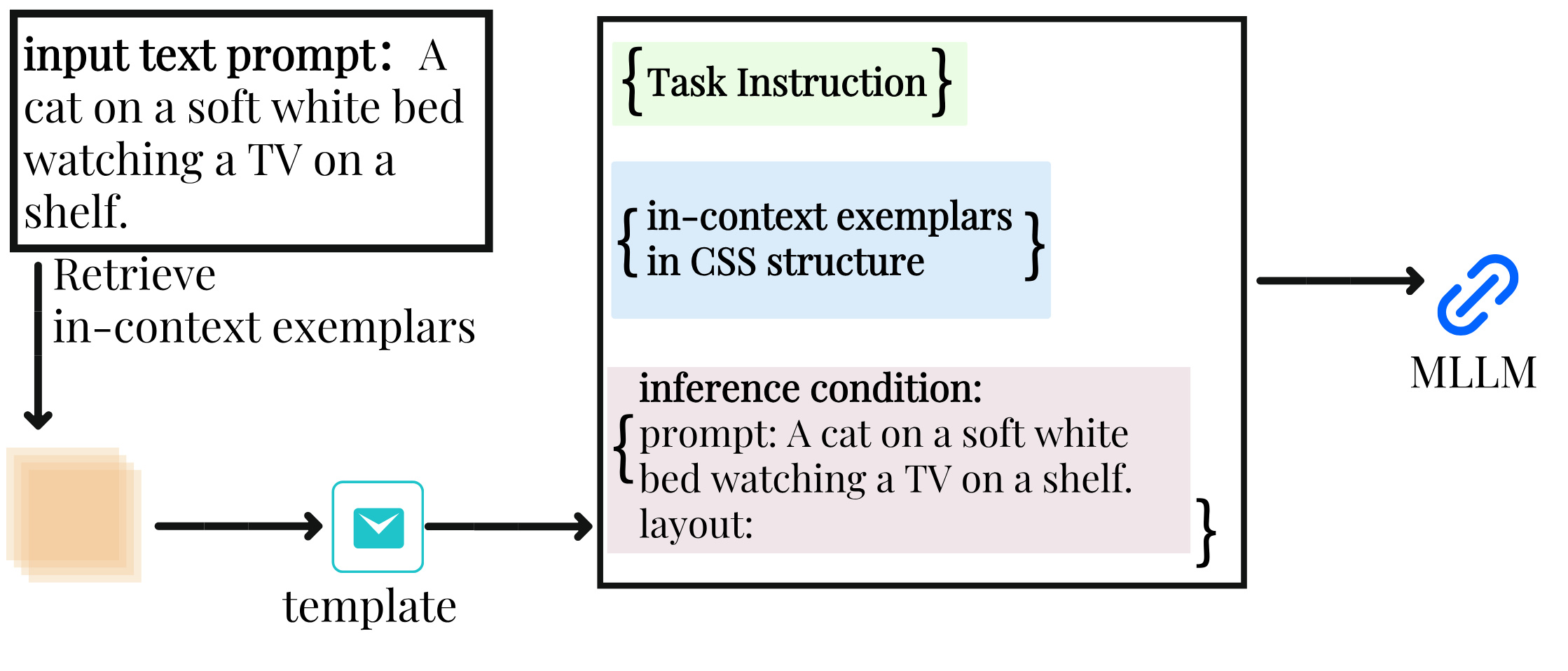
核心思路:利用多模态大型语言模型(LLM)强大的语义理解和推理能力,将其作为全局控制器,指导扩散模型的生成过程。LLM负责解析文本提示,提取关键对象及其属性、空间关系等信息,并将其转化为可控的控制信号,从而精确控制图像的生成。
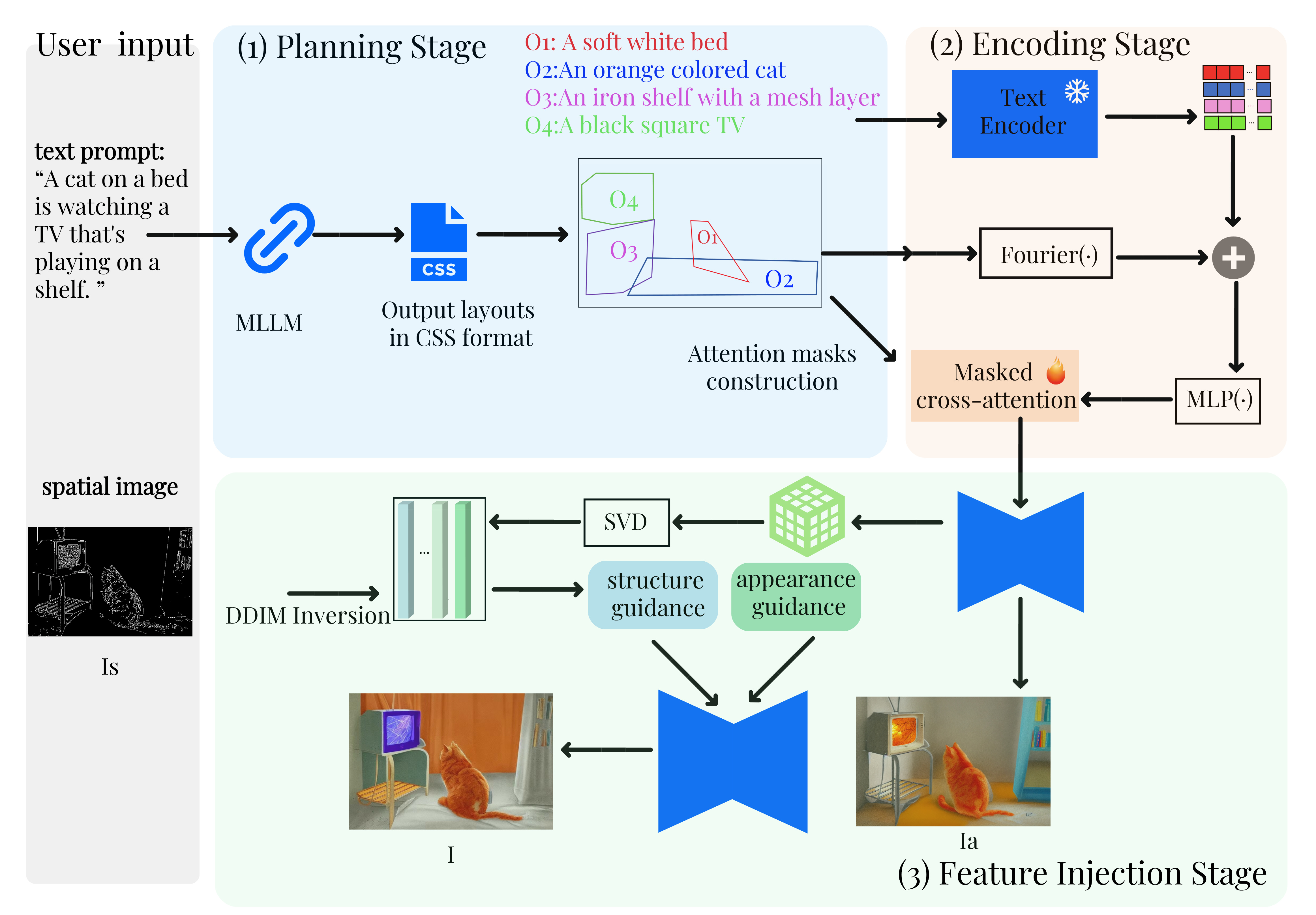
技术框架:LLMControl框架包含以下主要模块:1) 多模态LLM:负责解析文本提示和视觉条件,生成空间布局、语义描述和对象属性绑定信息。2) 控制信号注入模块:将LLM生成的控制信号注入到扩散模型的去噪网络中,用于调整注意力图,从而影响图像的生成过程。3) 扩散模型:使用预训练的文本到图像扩散模型作为图像生成器。整个流程是,首先输入文本提示和视觉条件,LLM解析这些信息并生成控制信号,然后控制信号被注入到扩散模型中,最终生成符合要求的图像。
关键创新:该方法的核心创新在于利用多模态LLM作为全局控制器,将文本提示中的复杂语义信息转化为可控的控制信号,从而实现对扩散模型生成过程的精确控制。与现有方法相比,LLMControl能够更好地理解和执行文本提示中的空间信息,从而生成更符合要求的图像。
关键设计:LLM被用于增强语义描述,安排空间布局,并绑定对象属性。控制信号通过调整去噪网络的注意力图来影响图像生成。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
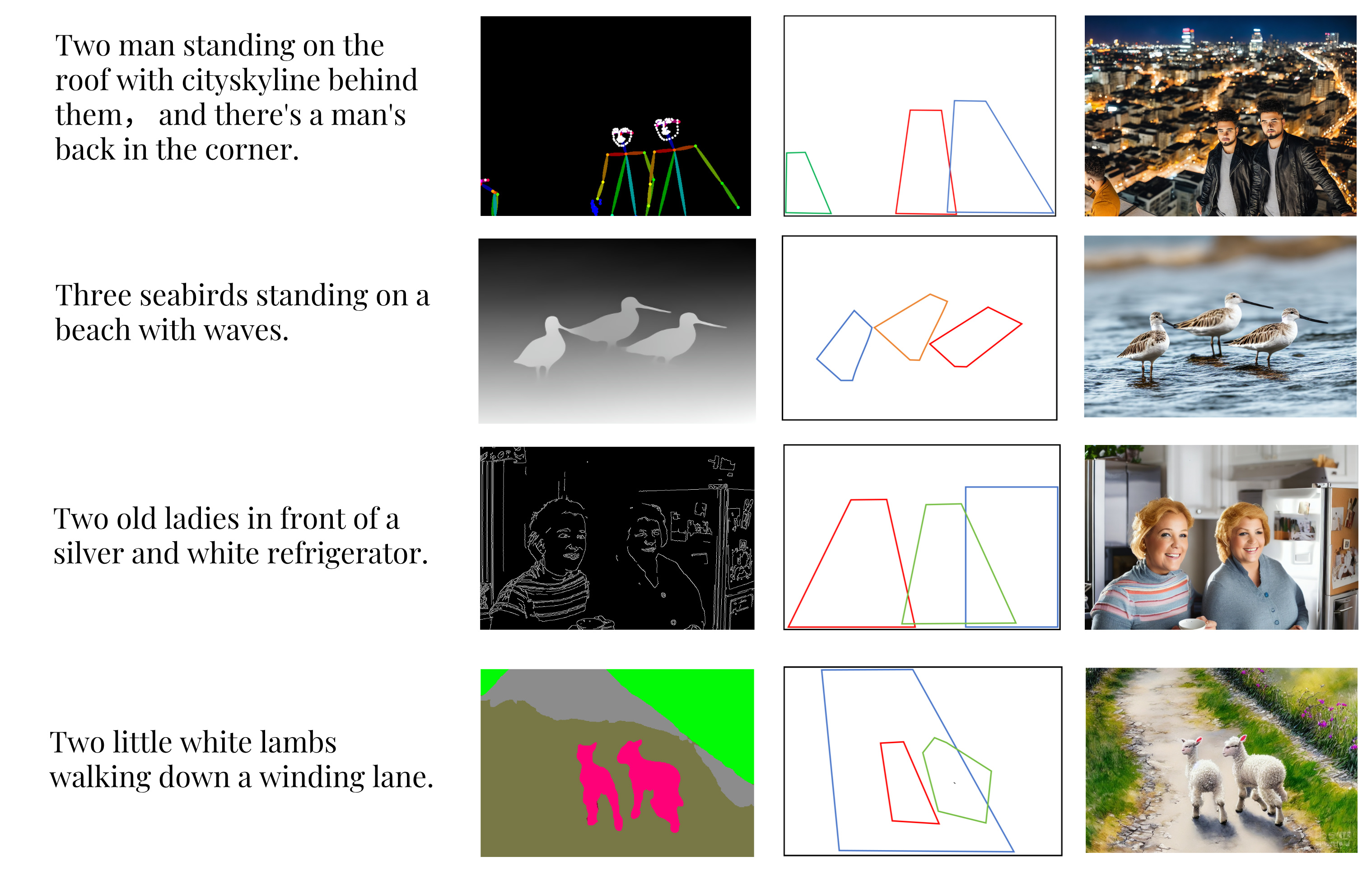
📊 实验亮点
LLMControl在各种预训练的T2I模型上实现了具有竞争力的合成质量。定性和定量实验表明,该方法能够处理大多数现有方法难以应对的具有挑战性的输入条件。具体的性能数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
LLMControl可应用于图像编辑、内容创作、虚拟现实等领域。例如,用户可以通过自然语言描述场景,并结合视觉条件,生成符合要求的图像。该技术可以提高图像生成效率和质量,降低创作门槛,并为虚拟现实等应用提供更逼真的内容。
📄 摘要(原文)
Recent spatial control methods for text-to-image (T2I) diffusion models have shown compelling results. However, these methods still fail to precisely follow the control conditions and generate the corresponding images, especially when encountering the textual prompts that contain multiple objects or have complex spatial compositions. In this work, we present a LLM-guided framework called LLM_Control to address the challenges of the controllable T2I generation task. By improving grounding capabilities, LLM_Control is introduced to accurately modulate the pre-trained diffusion models, where visual conditions and textual prompts influence the structures and appearance generation in a complementary way. We utilize the multimodal LLM as a global controller to arrange spatial layouts, augment semantic descriptions and bind object attributes. The obtained control signals are injected into the denoising network to refocus and enhance attention maps according to novel sampling constraints. Extensive qualitative and quantitative experiments have demonstrated that LLM_Control achieves competitive synthesis quality compared to other state-of-the-art methods across various pre-trained T2I models. It is noteworthy that LLM_Control allows the challenging input conditions on which most of the existing methods