HumanSAM: Classifying Human-centric Forgery Videos in Human Spatial, Appearance, and Motion Anomaly
作者: Chang Liu, Yunfan Ye, Fan Zhang, Qingyang Zhou, Yuchuan Luo, Zhiping Cai
分类: cs.CV
发布日期: 2025-07-26 (更新: 2025-08-01)
备注: ICCV 2025. Project page: https://dejian-lc.github.io/humansam/
💡 一句话要点
HumanSAM:通过空间、外观和运动异常分类以人为中心的伪造视频
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 伪造视频检测 细粒度分类 空间异常 外观异常 运动异常 视频理解 深度学习 HFV数据集
📋 核心要点
- 现有伪造视频检测方法缺乏对伪造类型的细粒度理解,导致可靠性和可解释性不足。
- HumanSAM通过融合视频理解和空间深度信息,将伪造分为空间、外观和运动三种异常类型。
- 论文构建了HFV数据集,并通过实验验证了HumanSAM在二元和多类伪造分类上的有效性。
📝 摘要(中文)
来自生成模型的合成视频,特别是模拟真实人类行为的以人为中心的视频,对人类信息安全和真实性构成重大威胁。虽然在二元伪造视频检测方面已经取得进展,但缺乏对伪造类型的细粒度理解,这引发了对可靠性和可解释性的担忧,而这对于实际应用至关重要。为了解决这个局限性,我们提出了HumanSAM,一个新的框架,它建立在视频生成模型的基本挑战之上。具体来说,HumanSAM旨在将以人为中心的伪造品分为三种在生成内容中常见的不同类型的伪影:空间异常、外观异常和运动异常。为了更好地捕捉几何、语义和时空一致性的特征,我们建议通过融合视频理解和空间深度的两个分支来生成人类伪造表示。我们还在训练过程中采用基于排序的置信度增强策略,通过引入三个先验分数来学习更鲁棒的表示。为了训练和评估,我们构建了第一个公共基准,即以人为中心的伪造视频(HFV)数据集,所有类型的伪造品都经过仔细的半自动标注。在我们的实验中,与最先进的方法相比,HumanSAM在二元和多类伪造分类中都取得了有希望的结果。
🔬 方法详解
问题定义:论文旨在解决现有伪造视频检测方法无法细粒度区分伪造类型的问题。现有方法主要关注二元分类(真/假),缺乏对伪造成因的理解,限制了其在实际应用中的可靠性和可解释性。例如,无法区分是空间扭曲、外观不一致还是运动异常导致的伪造。
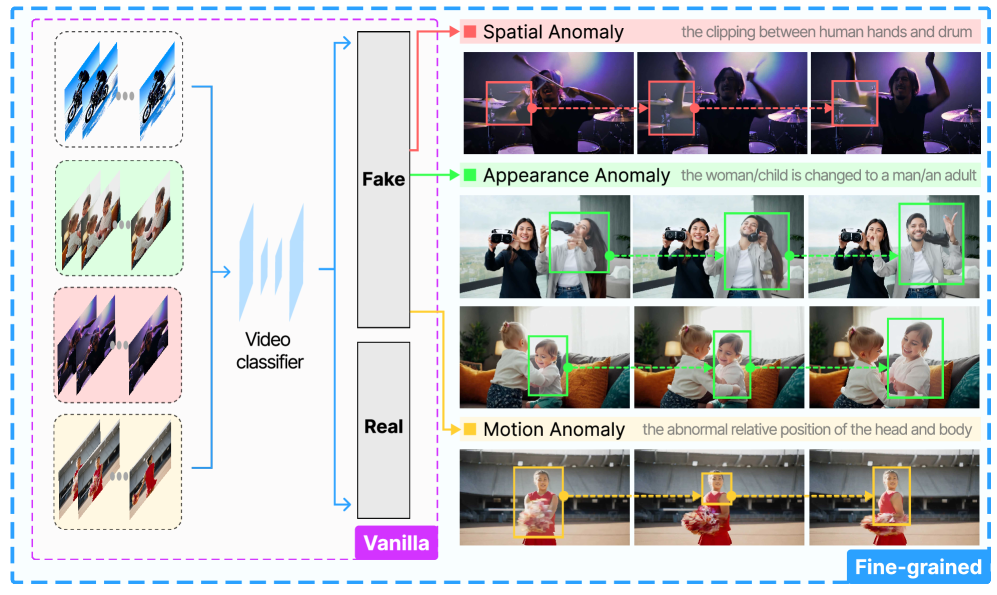
核心思路:论文的核心思路是将伪造视频分类为三种不同类型的异常:空间异常、外观异常和运动异常。通过这种细粒度的分类,可以更好地理解伪造视频的成因,从而提高检测的可靠性和可解释性。论文认为,视频生成模型在生成人类行为时,容易在空间、外观和运动方面产生不一致性。
技术框架:HumanSAM框架主要包含两个分支:视频理解分支和空间深度分支。视频理解分支用于提取视频的语义和时空信息,空间深度分支用于提取视频的几何信息。这两个分支的特征被融合在一起,形成人类伪造表示。此外,论文还采用了基于排序的置信度增强策略,通过引入三个先验分数来学习更鲁棒的表示。整体流程包括特征提取、特征融合、分类和置信度增强。
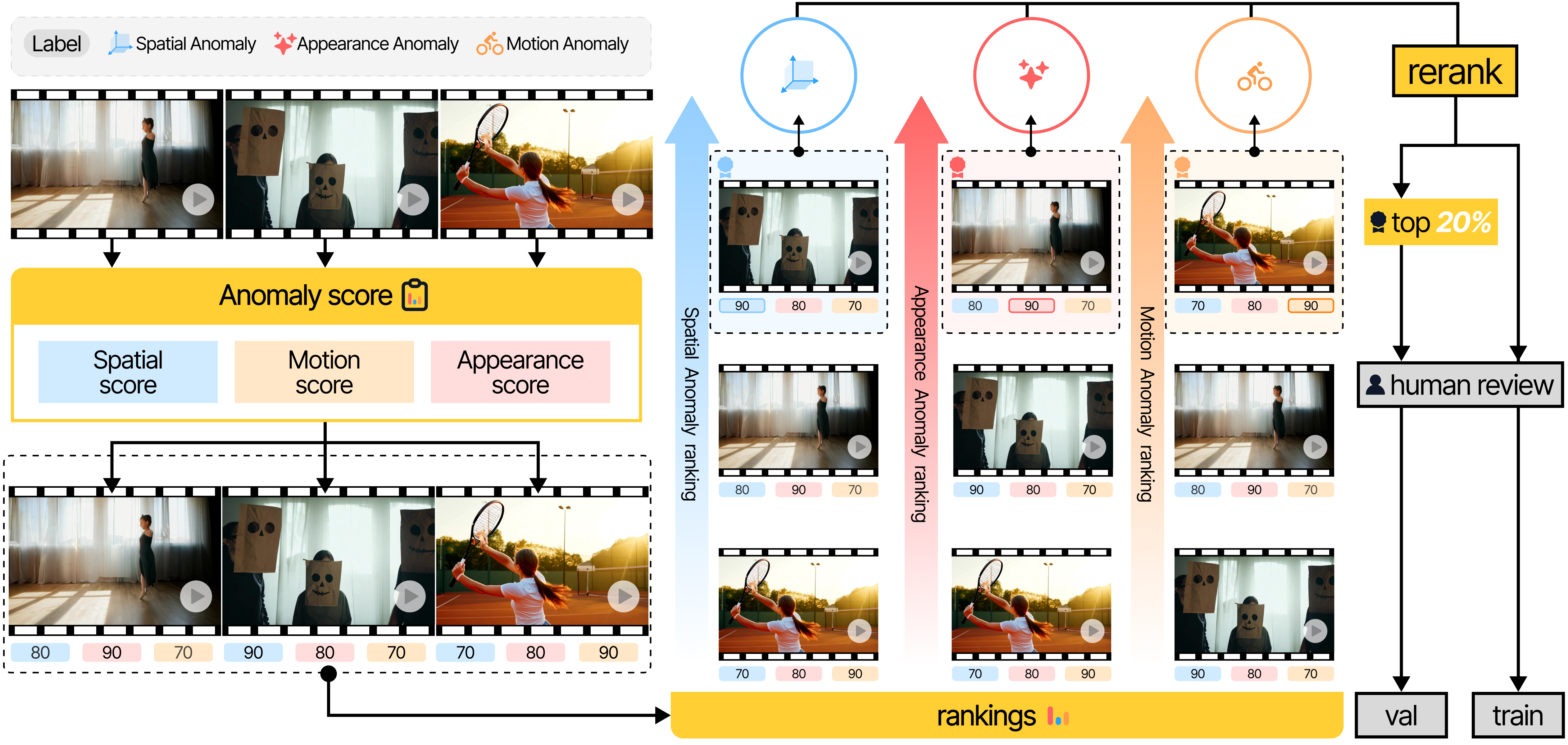
关键创新:论文的关键创新在于提出了细粒度的伪造类型分类方法,并设计了融合视频理解和空间深度的特征表示方法。与现有方法相比,HumanSAM不仅可以检测伪造视频,还可以识别伪造的类型。此外,基于排序的置信度增强策略也是一个创新点,可以提高模型的鲁棒性。
关键设计:在网络结构方面,论文具体使用的视频理解和空间深度分支的网络结构未知,但强调了特征融合的重要性。在损失函数方面,论文采用了分类损失函数,用于区分不同的伪造类型。基于排序的置信度增强策略的具体实现细节未知,但提到引入了三个先验分数。
🖼️ 关键图片

📊 实验亮点
HumanSAM在HFV数据集上取得了显著的性能提升,在二元和多类伪造分类任务中均优于现有方法。具体性能数据未知,但论文强调了其在细粒度伪造类型分类方面的优势。HFV数据集的构建也为该领域的研究提供了新的基准。
🎯 应用场景
该研究成果可应用于信息安全领域,例如检测和识别社交媒体上的伪造视频,防止虚假信息传播。此外,该技术还可以用于身份验证、视频监控等领域,提高系统的安全性和可靠性。未来,该研究可以扩展到更广泛的视频伪造检测领域,并与其他安全技术相结合,构建更强大的安全防护体系。
📄 摘要(原文)
Numerous synthesized videos from generative models, especially human-centric ones that simulate realistic human actions, pose significant threats to human information security and authenticity. While progress has been made in binary forgery video detection, the lack of fine-grained understanding of forgery types raises concerns regarding both reliability and interpretability, which are critical for real-world applications. To address this limitation, we propose HumanSAM, a new framework that builds upon the fundamental challenges of video generation models. Specifically, HumanSAM aims to classify human-centric forgeries into three distinct types of artifacts commonly observed in generated content: spatial, appearance, and motion anomaly. To better capture the features of geometry, semantics and spatiotemporal consistency, we propose to generate the human forgery representation by fusing two branches of video understanding and spatial depth. We also adopt a rank-based confidence enhancement strategy during the training process to learn more robust representation by introducing three prior scores. For training and evaluation, we construct the first public benchmark, the Human-centric Forgery Video (HFV) dataset, with all types of forgeries carefully annotated semi-automatically. In our experiments, HumanSAM yields promising results in comparison with state-of-the-art methods, both in binary and multi-class forgery classification.