ATCTrack: Aligning Target-Context Cues with Dynamic Target States for Robust Vision-Language Tracking
作者: X. Feng, S. Hu, X. Li, D. Zhang, M. Wu, J. Zhang, X. Chen, K. Huang
分类: cs.CV
发布日期: 2025-07-26
备注: Accepted by ICCV2025 Highlight ~
🔗 代码/项目: GITHUB
💡 一句话要点
ATCTrack:通过对齐目标-上下文线索与动态目标状态,实现鲁棒的视觉-语言跟踪
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言跟踪 目标跟踪 上下文建模 时序建模 文本理解
📋 核心要点
- 现有视觉-语言跟踪器难以适应目标状态的动态变化,导致在复杂场景下跟踪性能下降。
- ATCTrack通过建模时序视觉目标-上下文信息和校准文本上下文词,实现与动态目标状态对齐的多模态线索。
- ATCTrack在主流基准测试中取得了新的SOTA性能,验证了其在复杂视觉-语言跟踪任务中的有效性。
📝 摘要(中文)
视觉-语言跟踪旨在利用初始帧中的模板块和语言描述来定位视频序列中的目标对象。为了实现鲁棒的跟踪,尤其是在MGIT强调的复杂长期场景中,不仅要描述目标特征,还要利用与目标相关的上下文特征至关重要。然而,从初始提示中获得的视觉和文本目标-上下文线索通常仅与初始目标状态对齐。由于目标状态的动态性,尤其是在复杂的长期序列中,这些线索难以持续指导视觉-语言跟踪器(VLT)。此外,对于具有多样化表达的文本提示,我们的实验表明,现有的VLT难以辨别哪些词与目标或上下文相关,从而使文本线索的利用变得复杂。在这项工作中,我们提出了一种名为ATCTrack的新型跟踪器,该跟踪器可以通过全面的目标-上下文特征建模获得与动态目标状态对齐的多模态线索,从而实现鲁棒的跟踪。具体来说,(1) 对于视觉模态,我们提出了一种有效的时序视觉目标-上下文建模方法,为跟踪器提供及时的视觉线索。(2) 对于文本模态,我们仅基于文本内容实现精确的目标词识别,并设计了一种创新的上下文词校准方法,以自适应地利用辅助上下文词。(3) 我们在主流基准上进行了广泛的实验,ATCTrack 实现了新的 SOTA 性能。代码和模型将在https://github.com/XiaokunFeng/ATCTrack发布。
🔬 方法详解
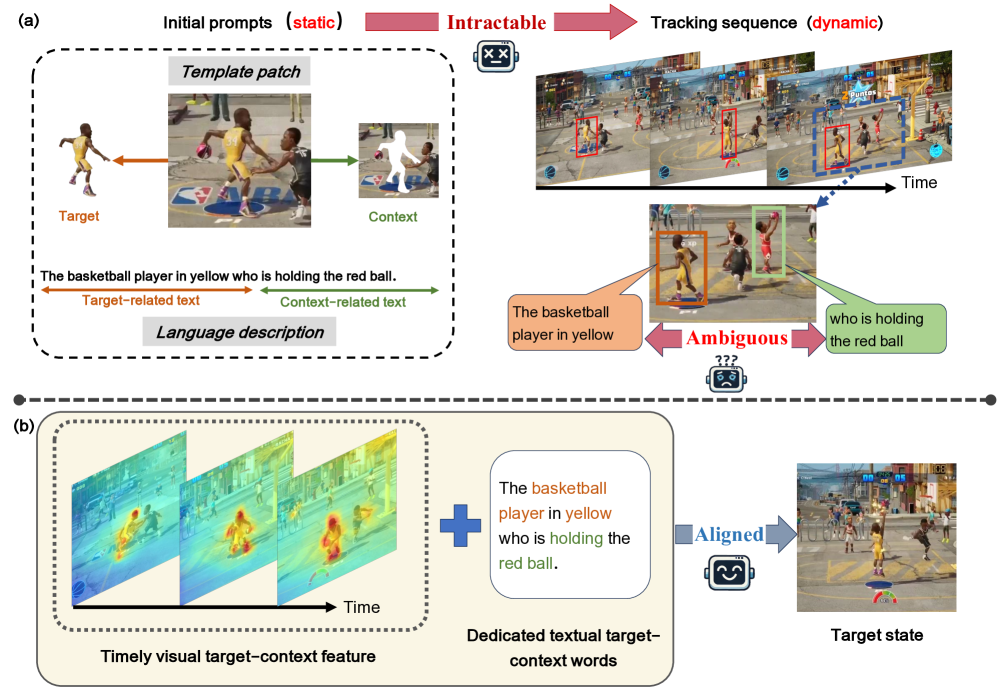
问题定义:视觉-语言跟踪任务旨在利用文本描述在视频中定位目标。现有方法的痛点在于,它们提取的视觉和文本特征通常只与初始帧的目标状态对齐,无法适应目标在视频中动态变化的状态,尤其是在长视频和复杂场景中,导致跟踪失败。此外,现有方法难以区分文本描述中哪些词语描述目标,哪些词语描述上下文,从而影响了上下文信息的有效利用。
核心思路:ATCTrack的核心思路是动态地对齐目标-上下文线索与目标状态。通过时序视觉建模,跟踪器可以及时获取目标的视觉上下文信息。同时,通过文本分析,精确识别目标词和校准上下文词,从而更好地利用文本信息。这种动态对齐策略使得跟踪器能够适应目标状态的变化,提高跟踪的鲁棒性。
技术框架:ATCTrack主要包含以下几个模块:1) 视觉目标-上下文建模模块,用于提取时序视觉特征;2) 文本目标词识别模块,用于识别文本描述中的目标词;3) 上下文词校准模块,用于自适应地利用上下文词;4) 跟踪模块,基于提取的视觉和文本特征进行目标定位。整体流程是,首先利用视觉目标-上下文建模模块提取视觉特征,然后利用文本目标词识别模块和上下文词校准模块提取文本特征,最后将视觉和文本特征融合,进行目标跟踪。
关键创新:ATCTrack的关键创新在于:1) 提出了时序视觉目标-上下文建模方法,能够动态地捕捉目标的视觉上下文信息;2) 提出了文本目标词识别和上下文词校准方法,能够更精确地利用文本信息。这些创新使得ATCTrack能够更好地适应目标状态的变化,提高跟踪的鲁棒性。
关键设计:在视觉目标-上下文建模模块中,使用了Transformer网络来建模时序信息。在文本目标词识别模块中,使用了注意力机制来识别目标词。在上下文词校准模块中,设计了一种自适应的权重机制,用于调整上下文词的贡献。损失函数包括跟踪损失和对比学习损失,用于提高跟踪的准确性和鲁棒性。
🖼️ 关键图片


📊 实验亮点
ATCTrack在多个主流视觉-语言跟踪基准测试中取得了显著的性能提升,达到了新的SOTA水平。具体而言,在MGIT基准测试中,ATCTrack的跟踪成功率和精确度均超过了现有最佳方法,证明了其在复杂长期跟踪场景中的优越性。实验结果表明,ATCTrack能够有效地利用视觉和文本上下文信息,提高跟踪的鲁棒性和准确性。
🎯 应用场景
ATCTrack在视频监控、自动驾驶、人机交互等领域具有广泛的应用前景。例如,在视频监控中,可以利用ATCTrack跟踪特定人物或车辆;在自动驾驶中,可以利用ATCTrack跟踪行人、车辆等目标,提高驾驶安全性;在人机交互中,可以利用ATCTrack跟踪用户的手势或面部表情,实现更自然的人机交互。
📄 摘要(原文)
Vision-language tracking aims to locate the target object in the video sequence using a template patch and a language description provided in the initial frame. To achieve robust tracking, especially in complex long-term scenarios that reflect real-world conditions as recently highlighted by MGIT, it is essential not only to characterize the target features but also to utilize the context features related to the target. However, the visual and textual target-context cues derived from the initial prompts generally align only with the initial target state. Due to their dynamic nature, target states are constantly changing, particularly in complex long-term sequences. It is intractable for these cues to continuously guide Vision-Language Trackers (VLTs). Furthermore, for the text prompts with diverse expressions, our experiments reveal that existing VLTs struggle to discern which words pertain to the target or the context, complicating the utilization of textual cues. In this work, we present a novel tracker named ATCTrack, which can obtain multimodal cues Aligned with the dynamic target states through comprehensive Target-Context feature modeling, thereby achieving robust tracking. Specifically, (1) for the visual modality, we propose an effective temporal visual target-context modeling approach that provides the tracker with timely visual cues. (2) For the textual modality, we achieve precise target words identification solely based on textual content, and design an innovative context words calibration method to adaptively utilize auxiliary context words. (3) We conduct extensive experiments on mainstream benchmarks and ATCTrack achieves a new SOTA performance. The code and models will be released at: https://github.com/XiaokunFeng/ATCTrack.