RaGS: Unleashing 3D Gaussian Splatting from 4D Radar and Monocular Cues for 3D Object Detection
作者: Xiaokai Bai, Chenxu Zhou, Lianqing Zheng, Si-Yuan Cao, Jianan Liu, Xiaohan Zhang, Yiming Li, Zhengzhuang Zhang, Hui-liang Shen
分类: cs.CV, cs.AI
发布日期: 2025-07-26 (更新: 2025-11-08)
💡 一句话要点
RaGS:利用4D雷达和单目线索,通过3D高斯溅射实现3D目标检测
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D目标检测 高斯溅射 4D雷达 单目视觉 多模态融合
📋 核心要点
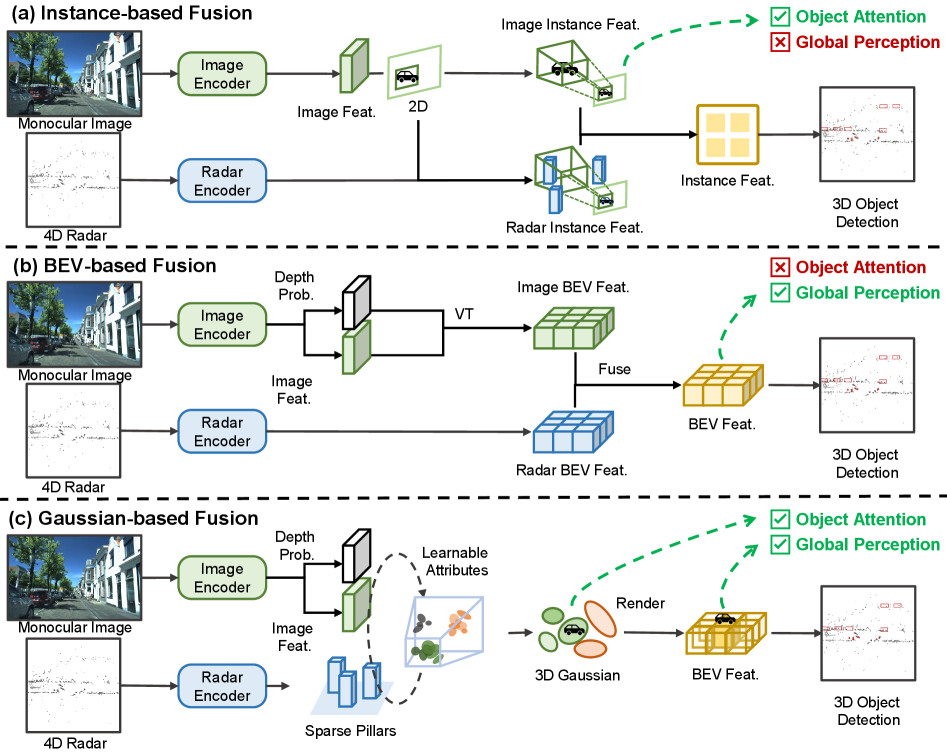
- 现有方法在融合4D雷达和单目图像进行3D目标检测时,缺乏全局上下文或受限于刚性结构,难以适应复杂场景。
- RaGS利用3D高斯溅射将场景建模为高斯连续场,动态分配资源给前景对象,并利用4D雷达速度信息细化高斯分布。
- 实验表明,RaGS在多个数据集上实现了最先进的性能,证明了其在3D目标检测方面的鲁棒性和有效性。
📝 摘要(中文)
本文提出RaGS,这是一个首个利用3D高斯溅射(GS)融合4D雷达和单目线索进行3D目标检测的框架。现有方法依赖缺乏全局上下文的实例提议或受限于刚性结构的密集BEV网格,缺乏对多样化场景的灵活和自适应表示。RaGS将场景建模为高斯连续场,能够动态分配资源给前景对象,同时保持灵活性和效率。4D雷达的速度维度提供运动线索,有助于锚定和细化高斯的空间分布。RaGS采用级联流程构建并逐步细化高斯场,首先通过基于视锥的定位初始化(FLI)反投影前景像素以初始化粗略的高斯中心,然后通过迭代多模态聚合(IMA)显式利用图像语义并隐式集成4D雷达速度几何来细化感兴趣区域内的高斯,最后通过多级高斯融合(MGF)将高斯场渲染为分层BEV特征用于3D目标检测。RaGS通过动态聚焦于稀疏且信息丰富的区域,实现了以对象为中心的精度和全面的场景感知。在View-of-Delft、TJ4DRadSet和OmniHD-Scenes上的大量实验证明了其鲁棒性和SOTA性能。
🔬 方法详解
问题定义:论文旨在解决利用4D毫米波雷达和单目图像进行3D目标检测的问题。现有方法,如基于实例提议的方法缺乏全局上下文,而基于BEV网格的方法则受限于刚性结构,无法灵活适应复杂多变的场景,导致检测精度和鲁棒性不足。
核心思路:论文的核心思路是利用3D高斯溅射(3D Gaussian Splatting, GS)将场景表示为一个连续的高斯场。这种表示方法允许动态地将计算资源分配给前景目标,从而提高检测精度,同时保持了场景表示的灵活性。此外,论文还利用4D雷达的速度信息来指导高斯分布的优化,进一步提升了检测性能。
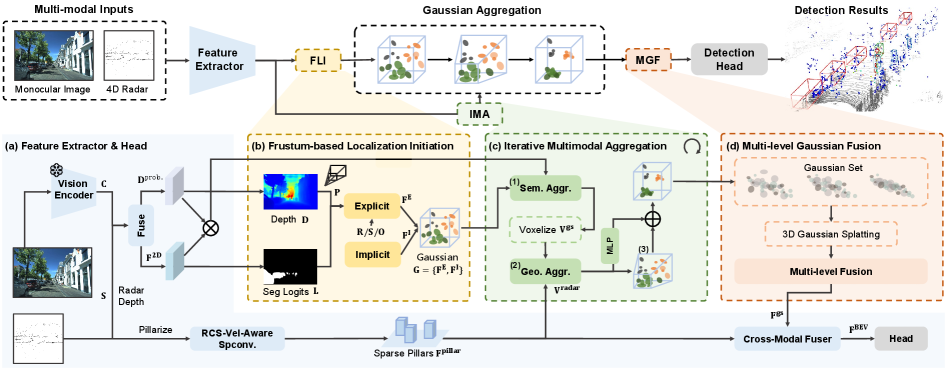
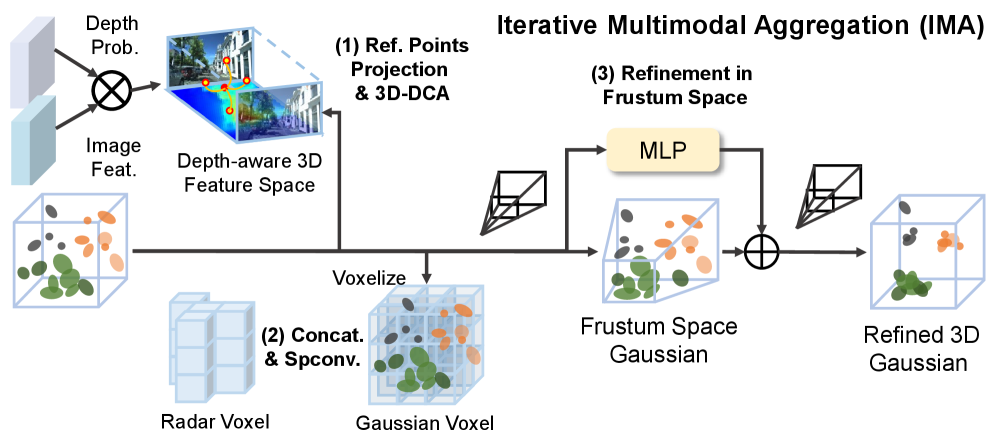
技术框架:RaGS框架采用级联流程,包含三个主要阶段:1) 基于视锥的定位初始化(Frustum-based Localization Initiation, FLI):利用单目图像的前景像素初始化粗略的高斯中心。2) 迭代多模态聚合(Iterative Multimodal Aggregation, IMA):显式地利用图像语义信息,并隐式地集成4D雷达的速度几何信息,迭代地细化高斯分布。3) 多级高斯融合(Multi-level Gaussian Fusion, MGF):将优化后的高斯场渲染为分层的BEV特征,用于最终的3D目标检测。
关键创新:该论文的关键创新在于首次将3D高斯溅射应用于4D雷达和单目图像融合的3D目标检测任务。与传统的基于体素或网格的方法相比,3D高斯溅射能够更灵活地表示场景,并动态地调整计算资源分配,从而提高检测精度和效率。此外,利用4D雷达的速度信息来指导高斯分布的优化也是一个重要的创新点。
关键设计:在FLI阶段,论文使用单目图像的前景分割结果来确定初始高斯中心的位置。在IMA阶段,论文设计了一种迭代的优化策略,通过图像语义和雷达速度信息共同指导高斯参数的更新。MGF阶段则将不同层级的高斯特征融合,以获得更全面的场景表示。具体的损失函数和网络结构等技术细节在论文中进行了详细描述,但此处不便展开。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RaGS在View-of-Delft、TJ4DRadSet和OmniHD-Scenes等数据集上均取得了SOTA性能,验证了其有效性和鲁棒性。具体性能数据和对比基线在论文中进行了详细展示,证明了RaGS在3D目标检测任务上的显著优势。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能交通等领域。通过融合雷达和视觉信息,能够提高在复杂环境下的目标检测精度和鲁棒性,从而提升自动驾驶系统的安全性。此外,该方法还可以用于构建高精度的三维地图,为机器人导航提供更可靠的环境信息。
📄 摘要(原文)
4D millimeter-wave radar is a promising sensing modality for autonomous driving, yet effective 3D object detection from 4D radar and monocular images remains challenging. Existing fusion approaches either rely on instance proposals lacking global context or dense BEV grids constrained by rigid structures, lacking a flexible and adaptive representation for diverse scenes. To address this, we propose RaGS, the first framework that leverages 3D Gaussian Splatting (GS) to fuse 4D radar and monocular cues for 3D object detection. 3D GS models the scene as a continuous field of Gaussians, enabling dynamic resource allocation to foreground objects while maintaining flexibility and efficiency. Moreover, the velocity dimension of 4D radar provides motion cues that help anchor and refine the spatial distribution of Gaussians. Specifically, RaGS adopts a cascaded pipeline to construct and progressively refine the Gaussian field. It begins with Frustum-based Localization Initiation (FLI), which unprojects foreground pixels to initialize coarse Gaussian centers. Then, Iterative Multimodal Aggregation (IMA) explicitly exploits image semantics and implicitly integrates 4D radar velocity geometry to refine the Gaussians within regions of interest. Finally, Multi-level Gaussian Fusion (MGF) renders the Gaussian field into hierarchical BEV features for 3D object detection. By dynamically focusing on sparse and informative regions, RaGS achieves object-centric precision and comprehensive scene perception. Extensive experiments on View-of-Delft, TJ4DRadSet, and OmniHD-Scenes demonstrate its robustness and SOTA performance. Code will be released.