DepthFlow: Exploiting Depth-Flow Structural Correlations for Unsupervised Video Object Segmentation
作者: Suhwan Cho, Minhyeok Lee, Jungho Lee, Donghyeong Kim, Sangyoun Lee
分类: cs.CV
发布日期: 2025-07-26
备注: ICCVW 2025
💡 一句话要点
DepthFlow:利用深度-光流结构相关性进行无监督视频对象分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 无监督视频对象分割 数据合成 深度估计 光流 结构相关性
📋 核心要点
- 现有无监督视频对象分割方法受限于训练数据不足,难以充分学习光流中的结构信息。
- DepthFlow通过单张图像合成光流,利用深度信息生成具有结构相关性的光流数据,扩充训练集。
- 实验表明,使用合成数据训练的简单模型在多个VOS基准测试中达到了新的state-of-the-art性能。
📝 摘要(中文)
无监督视频对象分割(VOS)旨在检测视频中最突出的对象。最近,利用RGB图像和光流的双流方法受到了广泛关注,但它们的性能受到训练数据稀缺的根本限制。为了解决这个问题,我们提出DepthFlow,一种从单张图像合成光流的新型数据生成方法。我们的方法基于VOS模型更依赖于光流图中嵌入的结构信息而非几何精度,并且这种结构与深度高度相关的关键洞察。我们首先从源图像估计深度图,然后将其转换为保留基本结构线索的合成光流场。这个过程使得能够将大规模图像-掩码对转换为图像-光流-掩码训练对,从而极大地扩展了网络训练可用的数据。通过使用我们合成的数据训练一个简单的编码器-解码器架构,我们在所有公共VOS基准测试中实现了新的最先进的性能,展示了一个可扩展且有效的数据稀缺问题解决方案。
🔬 方法详解
问题定义:无监督视频对象分割旨在从视频中自动分割出最显著的前景对象,而无需人工标注。现有的方法,特别是基于光流的方法,受限于大规模标注数据的缺乏,难以充分训练模型,从而影响分割精度和泛化能力。
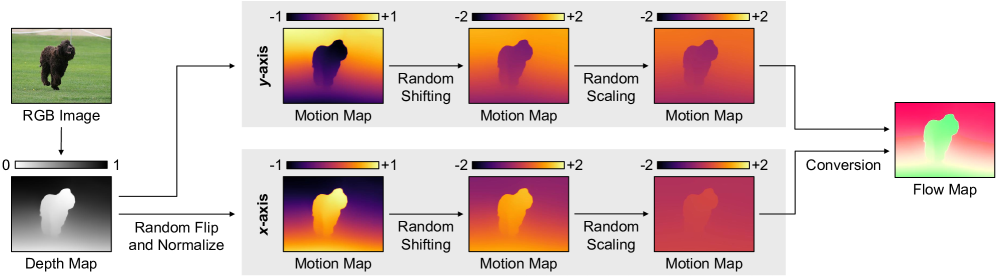
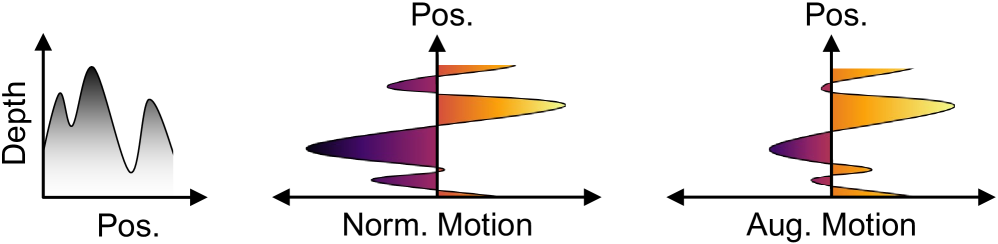
核心思路:论文的核心思路是利用单张图像的深度信息来合成光流,从而生成大量的训练数据。作者观察到VOS模型更关注光流中的结构信息而非精确的几何信息,而深度图能够很好地反映场景的结构。因此,通过将深度图转换为光流,可以有效地扩充训练数据,提升模型性能。
技术框架:DepthFlow方法主要包含以下几个阶段:1) 从单张RGB图像估计深度图;2) 将深度图转换为合成光流场,该光流场保留了图像的结构信息;3) 使用合成的图像-光流-掩码对训练一个编码器-解码器结构的分割模型。训练完成后,该模型可以用于无监督视频对象分割任务。
关键创新:该方法最重要的创新点在于提出了利用深度信息合成光流的数据生成方法。与直接使用真实光流相比,该方法可以从单张图像生成大量的训练数据,有效缓解了数据稀缺问题。此外,该方法强调了光流中的结构信息的重要性,并设计了一种能够保留结构信息的深度到光流转换方法。
关键设计:在深度估计方面,可以使用现成的深度估计模型。在深度到光流的转换方面,作者设计了一种基于深度梯度的转换方法,以确保合成的光流能够反映图像的结构信息。在网络结构方面,作者使用了一个简单的编码器-解码器结构,并使用交叉熵损失函数进行训练。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
DepthFlow在多个VOS基准测试中取得了state-of-the-art的性能。例如,在DAVIS 2016和DAVIS 2017数据集上,DepthFlow的性能显著优于现有的无监督VOS方法。实验结果表明,通过合成数据进行训练可以有效地提升模型的分割精度和泛化能力,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于智能视频监控、自动驾驶、视频编辑等领域。例如,在智能监控中,可以自动分割出视频中的可疑对象;在自动驾驶中,可以辅助识别车辆和行人;在视频编辑中,可以快速分割出视频中的前景对象,进行特效处理。该方法具有较强的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Unsupervised video object segmentation (VOS) aims to detect the most prominent object in a video. Recently, two-stream approaches that leverage both RGB images and optical flow have gained significant attention, but their performance is fundamentally constrained by the scarcity of training data. To address this, we propose DepthFlow, a novel data generation method that synthesizes optical flow from single images. Our approach is driven by the key insight that VOS models depend more on structural information embedded in flow maps than on their geometric accuracy, and that this structure is highly correlated with depth. We first estimate a depth map from a source image and then convert it into a synthetic flow field that preserves essential structural cues. This process enables the transformation of large-scale image-mask pairs into image-flow-mask training pairs, dramatically expanding the data available for network training. By training a simple encoder-decoder architecture with our synthesized data, we achieve new state-of-the-art performance on all public VOS benchmarks, demonstrating a scalable and effective solution to the data scarcity problem.