TransFlow: Motion Knowledge Transfer from Video Diffusion Models to Video Salient Object Detection
作者: Suhwan Cho, Minhyeok Lee, Jungho Lee, Sunghun Yang, Sangyoun Lee
分类: cs.CV
发布日期: 2025-07-26
备注: ICCVW 2025
💡 一句话要点
TransFlow:利用视频扩散模型迁移运动知识,提升视频显著性目标检测性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频显著性目标检测 运动知识迁移 视频扩散模型 光流生成 深度学习
📋 核心要点
- 视频SOD模型训练受限于高质量视频数据稀缺,现有方法生成的运动信息不真实,缺乏语义理解。
- TransFlow利用预训练视频扩散模型学习到的运动先验,从静态图像生成具有语义感知的光流。
- 实验结果表明,TransFlow能够有效提升视频SOD模型的性能,并在多个基准测试中取得显著改进。
📝 摘要(中文)
视频显著性目标检测(SOD)依赖于运动线索来区分显著目标与背景,但相比于丰富的图像数据集,用于训练此类模型的视频数据集非常稀缺。现有的利用空间变换从静态图像创建视频序列的方法,对于运动引导的任务而言是无效的,因为这些变换会产生不真实的、缺乏语义理解的光流。我们提出了TransFlow,它从预训练的视频扩散模型中迁移运动知识,为视频SOD生成真实的训练数据。视频扩散模型已经从大规模视频数据中学习到了丰富的语义运动先验,理解了不同对象在真实场景中如何自然地运动。TransFlow利用这些知识,从静态图像生成具有语义感知的光流,其中对象表现出自然的运动模式,同时保持空间边界和时间一致性。我们的方法在多个基准测试中实现了性能提升,证明了运动知识迁移的有效性。
🔬 方法详解
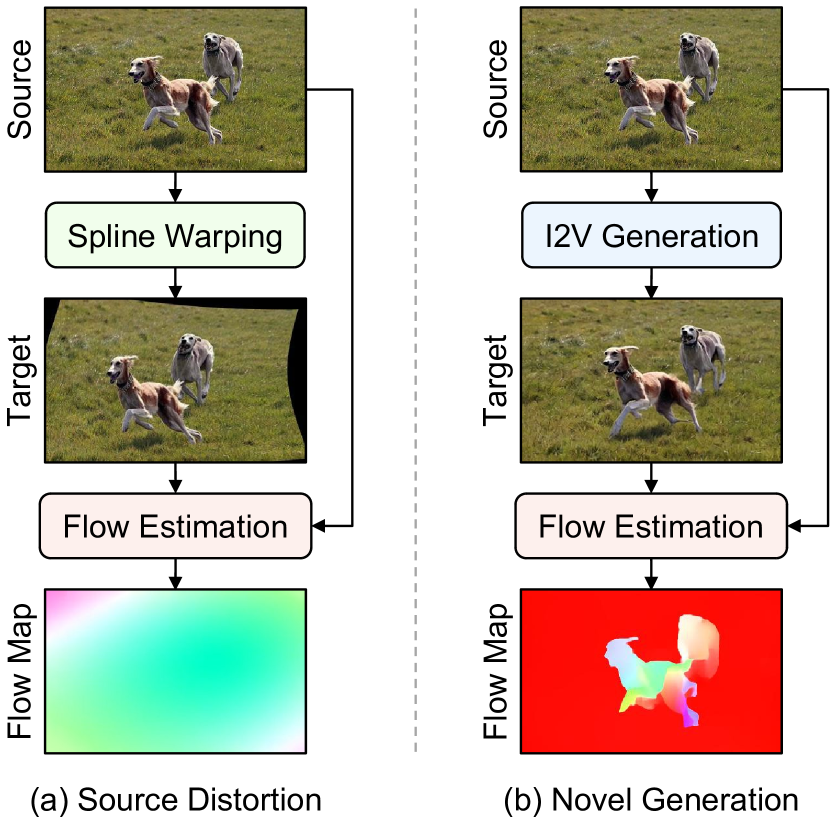
问题定义:视频显著性目标检测任务需要利用运动信息来区分前景和背景,但高质量的视频训练数据非常稀缺。现有的方法通常使用静态图像和空间变换来生成伪视频数据,然而这些方法生成的运动信息(例如光流)往往不真实,缺乏对场景语义的理解,导致训练出的模型泛化能力较差。
核心思路:TransFlow的核心思路是从预训练的视频扩散模型中迁移运动知识。视频扩散模型在大规模视频数据上训练,学习到了丰富的运动先验知识,能够理解不同物体在真实场景中的运动模式。TransFlow利用这些先验知识,将静态图像转化为包含真实运动信息的光流,从而为视频SOD模型提供更有效的训练数据。
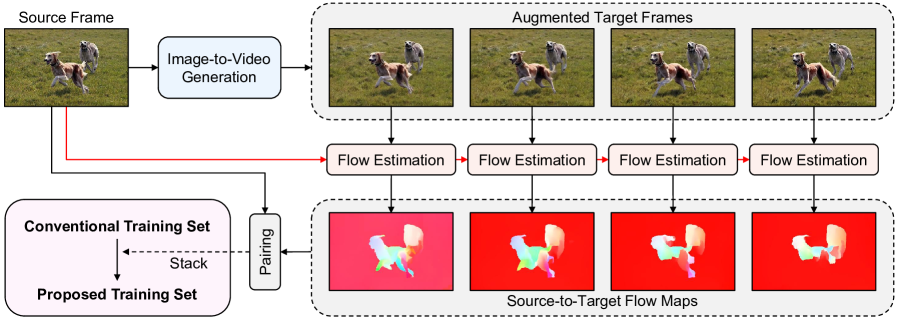
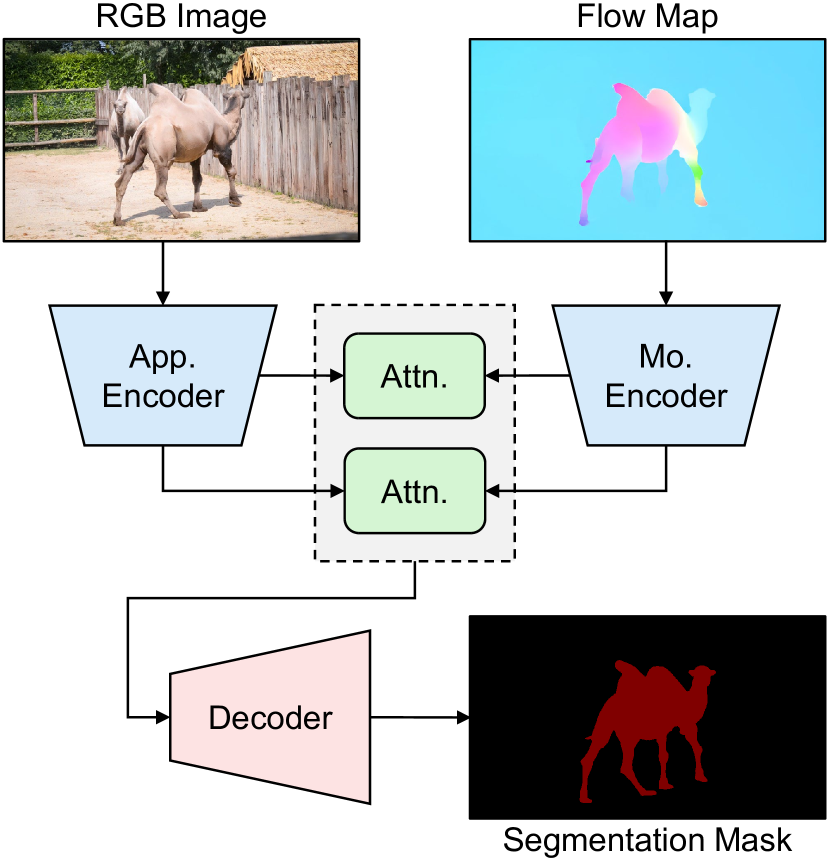
技术框架:TransFlow主要包含两个阶段:1) 利用预训练的视频扩散模型生成光流。给定一张静态图像,TransFlow首先将其输入到视频扩散模型中,利用模型生成与该图像对应的光流信息。2) 使用生成的光流和静态图像作为训练数据,训练视频SOD模型。整体流程简单有效,易于实现。
关键创新:TransFlow的关键创新在于利用视频扩散模型进行运动知识迁移。与以往使用简单空间变换生成伪视频数据的方法不同,TransFlow能够生成具有语义感知的光流,从而为视频SOD模型提供更真实的运动信息。这种方法能够有效提升模型的性能和泛化能力。
关键设计:TransFlow的关键设计在于如何有效地利用预训练的视频扩散模型生成光流。具体来说,TransFlow将静态图像作为条件输入到视频扩散模型中,并利用模型的生成能力,预测与该图像对应的光流信息。此外,TransFlow还可能采用了一些技巧来保证生成光流的空间边界和时间一致性,例如使用特定的损失函数或网络结构。
🖼️ 关键图片
📊 实验亮点
TransFlow在多个视频显著性目标检测基准数据集上取得了显著的性能提升。实验结果表明,TransFlow能够有效地迁移视频扩散模型中的运动知识,生成更真实的训练数据,从而提升视频SOD模型的性能。具体性能数据需要在论文中查找,但摘要表明该方法在多个benchmark上取得了提升。
🎯 应用场景
TransFlow技术可广泛应用于视频监控、自动驾驶、视频编辑、机器人导航等领域。通过提升视频显著性目标检测的准确性和鲁棒性,可以帮助机器更好地理解视频内容,从而实现更智能化的应用。例如,在自动驾驶中,可以利用该技术更准确地识别行人、车辆等显著目标,提高驾驶安全性。在视频编辑中,可以自动提取视频中的显著目标,方便用户进行编辑和处理。
📄 摘要(原文)
Video salient object detection (SOD) relies on motion cues to distinguish salient objects from backgrounds, but training such models is limited by scarce video datasets compared to abundant image datasets. Existing approaches that use spatial transformations to create video sequences from static images fail for motion-guided tasks, as these transformations produce unrealistic optical flows that lack semantic understanding of motion. We present TransFlow, which transfers motion knowledge from pre-trained video diffusion models to generate realistic training data for video SOD. Video diffusion models have learned rich semantic motion priors from large-scale video data, understanding how different objects naturally move in real scenes. TransFlow leverages this knowledge to generate semantically-aware optical flows from static images, where objects exhibit natural motion patterns while preserving spatial boundaries and temporal coherence. Our method achieves improved performance across multiple benchmarks, demonstrating effective motion knowledge transfer.