Face2VoiceSync: Lightweight Face-Voice Consistency for Text-Driven Talking Face Generation
作者: Fang Kang, Yin Cao, Haoyu Chen
分类: cs.SD, cs.CV, cs.MM, eess.AS
发布日期: 2025-07-25
💡 一句话要点
提出Face2VoiceSync,解决文本驱动下的轻量级人脸语音同步生成问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 说话人脸生成 文本驱动 语音合成 人脸动画 VAE 语音-人脸同步
📋 核心要点
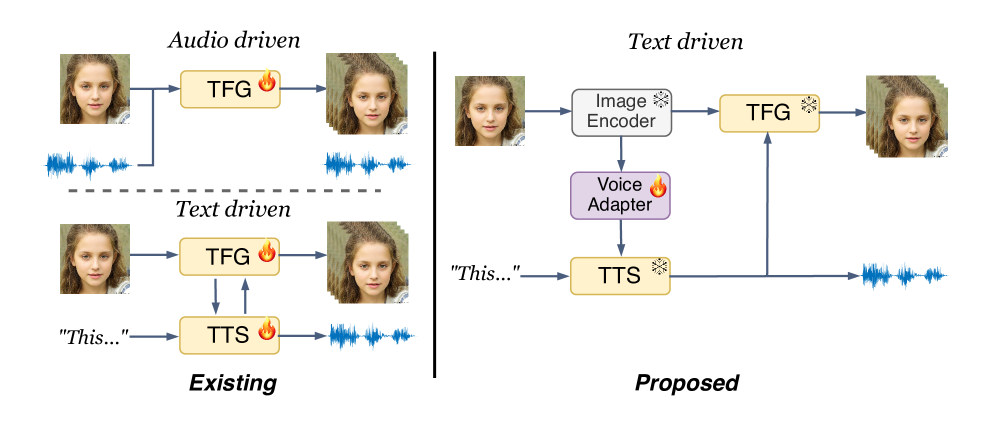
- 现有语音驱动的说话人脸生成方法依赖固定语音输入,限制了其应用范围,例如面部与语音不匹配。
- Face2VoiceSync通过语音-人脸对齐、多样性操控和高效训练,实现了文本驱动的说话人脸和对应语音的生成。
- 实验表明,Face2VoiceSync在视觉和音频质量上均达到了当前最佳水平,且训练资源需求较低。
📝 摘要(中文)
本文提出了一种新的文本驱动的说话人脸生成框架Face2VoiceSync,旨在解决语音驱动方法依赖固定语音输入的问题。该框架包含以下创新点:1) 语音-人脸对齐,确保生成的语音与面部外观匹配;2) 多样性与操控性,允许通过控制副语言特征空间来生成多样化的语音;3) 高效训练,使用轻量级VAE连接视觉和音频大型预训练模型,显著减少了可训练参数;4) 新的评估指标,公平地评估多样性和身份一致性。实验表明,Face2VoiceSync在单个40GB GPU上实现了视觉和音频方面的最先进性能。
🔬 方法详解
问题定义:现有说话人脸生成方法主要依赖于给定的语音信号驱动人脸动画,但缺乏对语音内容本身的控制。本文旨在解决文本驱动的说话人脸生成问题,即给定人脸图像和文本,生成对应的说话人脸动画和语音。现有方法的痛点在于难以保证生成语音和人脸外观的一致性,以及缺乏对生成语音多样性的有效控制。
核心思路:Face2VoiceSync的核心思路是通过一个轻量级的VAE模型,将视觉信息和文本信息编码到共享的隐空间中,从而实现语音和人脸的对齐。通过操控隐空间中的副语言特征,可以控制生成语音的多样性。同时,利用预训练的视觉和音频模型,可以减少训练参数,提高训练效率。
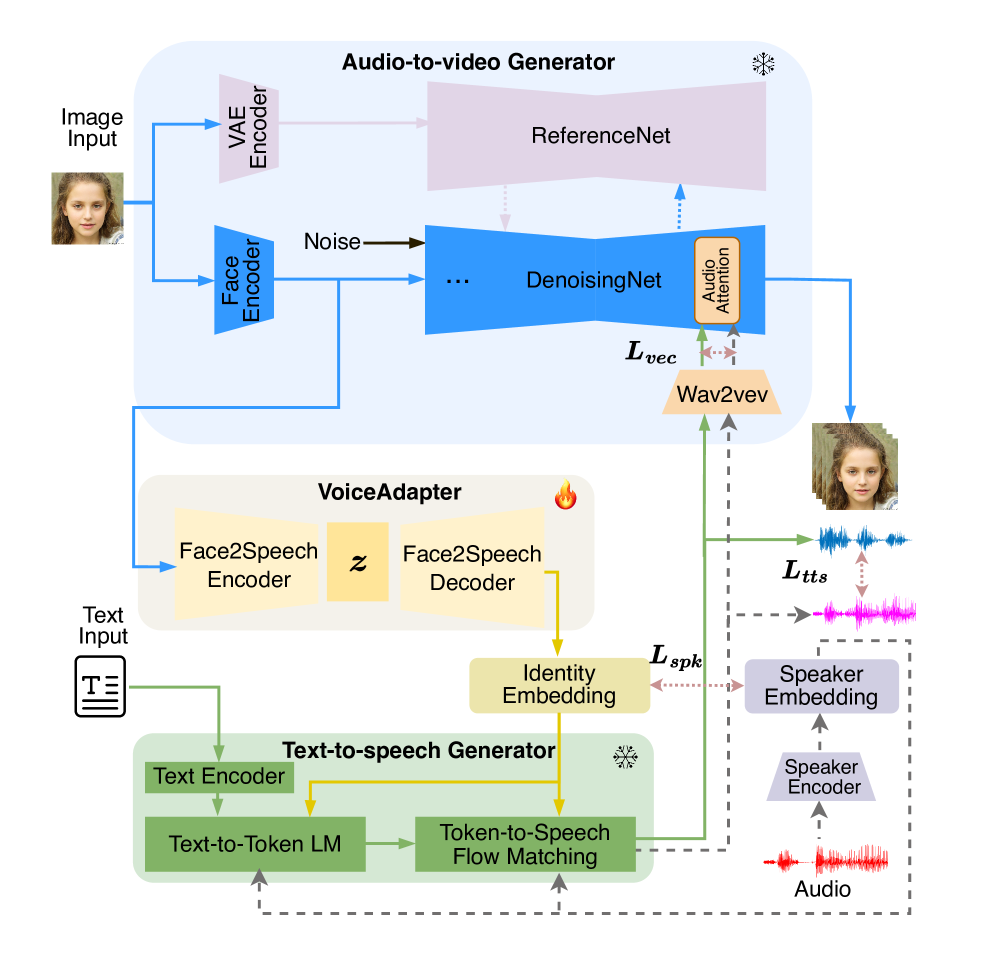
技术框架:Face2VoiceSync框架主要包含以下几个模块:1) 文本编码器:将输入的文本转换为文本特征向量。2) 人脸编码器:将输入的人脸图像转换为人脸特征向量。3) VAE:将文本特征向量和人脸特征向量编码到共享的隐空间中,并从中解码出语音特征和人脸动画参数。4) 语音解码器:将语音特征转换为语音信号。5) 人脸渲染器:将人脸动画参数渲染成最终的说话人脸视频。
关键创新:Face2VoiceSync的关键创新在于:1) 提出了语音-人脸对齐机制,通过共享隐空间保证生成语音和人脸外观的一致性。2) 实现了对生成语音多样性的有效控制,通过操控隐空间中的副语言特征,可以生成不同风格的语音。3) 采用了轻量级的VAE模型,显著减少了训练参数,提高了训练效率。4) 提出了新的评估指标,更公平地评估生成结果的多样性和身份一致性。
关键设计:Face2VoiceSync的关键设计包括:1) 使用预训练的BERT模型作为文本编码器,提取文本的语义信息。2) 使用预训练的ResNet模型作为人脸编码器,提取人脸的视觉特征。3) VAE采用β-VAE结构,通过调整β参数来控制隐空间的 disentanglement。4) 损失函数包括语音重建损失、人脸动画重建损失、对抗损失和身份保持损失等,以保证生成结果的质量和一致性。
🖼️ 关键图片
📊 实验亮点
Face2VoiceSync在多个数据集上取得了最先进的性能。与现有方法相比,Face2VoiceSync在语音质量、人脸动画质量和身份一致性方面均有显著提升。此外,Face2VoiceSync仅需在单个40GB GPU上进行训练,表明其具有较高的训练效率和可扩展性。
🎯 应用场景
Face2VoiceSync具有广泛的应用前景,例如虚拟助手、数字人、游戏角色、电影制作等。它可以用于创建逼真且个性化的虚拟形象,并根据文本内容生成相应的语音和面部动画。该技术还有助于改善人机交互体验,并为内容创作提供新的可能性。
📄 摘要(原文)
Recent studies in speech-driven talking face generation achieve promising results, but their reliance on fixed-driven speech limits further applications (e.g., face-voice mismatch). Thus, we extend the task to a more challenging setting: given a face image and text to speak, generating both talking face animation and its corresponding speeches. Accordingly, we propose a novel framework, Face2VoiceSync, with several novel contributions: 1) Voice-Face Alignment, ensuring generated voices match facial appearance; 2) Diversity \& Manipulation, enabling generated voice control over paralinguistic features space; 3) Efficient Training, using a lightweight VAE to bridge visual and audio large-pretrained models, with significantly fewer trainable parameters than existing methods; 4) New Evaluation Metric, fairly assessing the diversity and identity consistency. Experiments show Face2VoiceSync achieves both visual and audio state-of-the-art performances on a single 40GB GPU.