PRE-MAP: Personalized Reinforced Eye-tracking Multimodal LLM for High-Resolution Multi-Attribute Point Prediction
作者: Hanbing Wu, Ping Jiang, Anyang Su, Chenxu Zhao, Tianyu Fu, Minghui Wu, Beiping Tan, Huiying Li
分类: cs.CV
发布日期: 2025-07-25
🔗 代码/项目: GITHUB
💡 一句话要点
提出PRE-MAP模型,通过个性化强化学习眼动追踪多模态LLM,实现高分辨率多属性注视点预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 眼动追踪 多模态学习 强化学习 个性化推荐 视觉注意力 大型语言模型 显著性预测
📋 核心要点
- 现有显著性预测模型忽略了主观认知多样性对注视行为的影响,且低分辨率输入限制了个性化注意力模式的捕捉。
- PRE-MAP模型通过强化学习优化眼动追踪,并结合多属性用户配置文件,在MLLM基础上预测个性化注视点。
- 实验表明,PRE-MAP在SPA-ADV等数据集上表现出色,验证了其在个性化注视点预测方面的有效性。
📝 摘要(中文)
视觉选择性注意力受到个体偏好的驱动,通过连接主观认知机制与客观视觉元素来调节人类对视觉刺激的优先级排序,从而引导动态视觉场景的语义解释和分层处理。然而,现有的模型和数据集主要忽略了主观认知多样性对注视行为的影响。传统的显著性预测模型通常采用分割方法,依赖于低分辨率图像生成显著性热图,然后将其放大到原始分辨率,这限制了它们捕捉个性化注意力模式的能力。此外,多模态大型语言模型(MLLM)受到幻觉等因素的限制,使得在涉及多个点预测的任务中严格遵守预期格式的成本非常高昂,并且实现精确的点定位具有挑战性。为了解决这些限制,我们提出了SPA-ADV,一个大规模多模态数据集,捕捉了来自4500多名年龄和性别各异的参与者对486个视频的注视行为。此外,我们提出了一种新的眼动追踪显著性模型PRE-MAP,该模型通过强化学习优化的眼动追踪来表征个性化的视觉差异,该模型建立在MLLM之上,并由多属性用户配置文件引导来预测点。为了确保MLLM产生格式正确且空间准确的预测点,我们引入了Consistency Group Relative Policy Optimization (C-GRPO),其灵感来自眼动点和多属性配置文件的可变性。在SPA-ADV和其他基准上的大量实验证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决现有显著性预测模型无法有效捕捉个性化视觉注意力的难题。现有方法主要依赖低分辨率图像,忽略了用户主观认知差异,导致预测结果不够准确,且多模态大语言模型在多点预测任务中难以保证格式正确性和空间精确性。
核心思路:论文的核心思路是利用强化学习优化眼动追踪过程,并结合多属性用户画像,引导多模态大语言模型进行个性化注视点预测。通过强化学习,模型能够学习到更符合个体偏好的视觉注意力模式,从而提高预测的准确性。
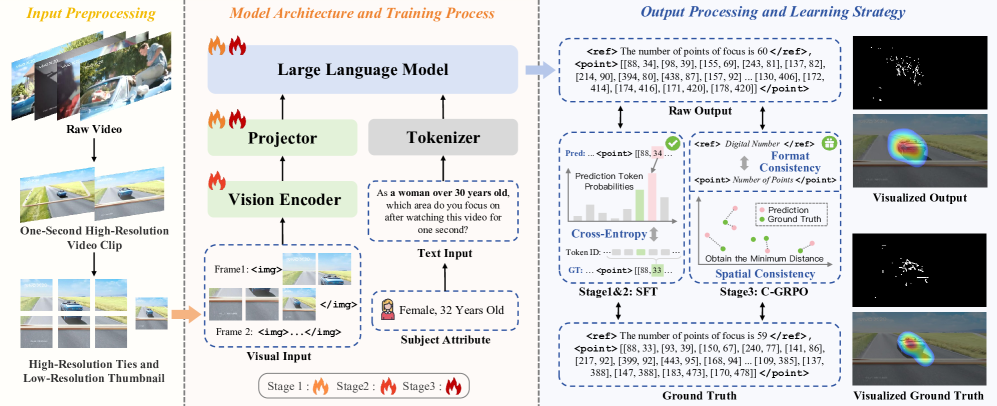
技术框架:PRE-MAP模型主要包含以下几个模块:1) 多模态大语言模型(MLLM):作为基础模型,负责处理视觉输入和用户属性信息。2) 强化学习模块:用于优化眼动追踪策略,学习个性化的视觉注意力模式。3) 多属性用户画像模块:提供用户的年龄、性别等属性信息,用于指导个性化预测。4) Consistency Group Relative Policy Optimization (C-GRPO):用于确保MLLM输出的预测点在格式和空间上的准确性。
关键创新:论文的关键创新在于:1) 提出了基于强化学习的个性化眼动追踪方法,能够有效捕捉个体差异。2) 引入了C-GRPO策略优化方法,解决了MLLM在多点预测任务中格式和空间准确性问题。3) 构建了大规模多模态数据集SPA-ADV,为个性化视觉注意力研究提供了数据支持。
关键设计:C-GRPO损失函数的设计是关键。它考虑了眼动点和多属性配置文件的可变性,通过相对策略优化,鼓励模型生成一致且准确的预测点。具体的参数设置和网络结构细节在论文中有详细描述,例如,强化学习中的奖励函数设计,以及MLLM的具体选择和配置。
🖼️ 关键图片


📊 实验亮点
PRE-MAP模型在SPA-ADV数据集上取得了显著的性能提升,相较于现有基线模型,在个性化注视点预测的准确性和效率方面均有明显优势。具体的数据指标和对比结果可在论文实验部分查阅。
🎯 应用场景
该研究成果可应用于广告推荐、人机交互、辅助驾驶等领域。通过预测用户的视觉注意力焦点,可以优化广告投放策略,提升用户体验,并为智能系统提供更准确的视觉信息。
📄 摘要(原文)
Visual selective attention, driven by individual preferences, regulates human prioritization of visual stimuli by bridging subjective cognitive mechanisms with objective visual elements, thereby steering the semantic interpretation and hierarchical processing of dynamic visual scenes. However, existing models and datasets predominantly neglect the influence of subjective cognitive diversity on fixation behavior. Conventional saliency prediction models, typically employing segmentation approaches, rely on low-resolution imagery to generate saliency heatmaps, subsequently upscaled to native resolutions, which limiting their capacity to capture personalized attention patterns. Furthermore, MLLMs are constrained by factors such as hallucinations, making it very costly to strictly adhere to the expected format in tasks involving multiple point predictions, and achieving precise point positioning is challenging. To address these limitations, we present Subjective Personalized Attention for Advertisement Videos, namely SPA-ADV, a large-scale multimodal dataset capturing gaze behaviors from over 4,500 participants varying in age and gender with 486 videos. Furthermore, we propose PRE-MAP, a novel eye-tracking saliency model that characterizes Personalized visual disparities through Reinforcement learning-optimized Eye-tracking, built upon MLLMs and guided by Multi-Attribute user profiles to predict Points. To ensure MLLMs produce prediction points that are both format-correct and spatially accurate, we introduce Consistency Group Relative Policy Optimization (C-GRPO), inspired by the variability in eye movement points and Multi-Attribute profiles. Extensive experiments on SPA-ADV and other benchmarks demonstrate the effectiveness of our approach. The code and dataset are available at \href{https://github.com/mininglamp-MLLM/PRE-MAP}{this URL}.