LISA: A Layer-wise Integration and Suppression Approach for Hallucination Mitigation in Multimodal Large Language Models
作者: Zhihui Guo, Xin Man, Hui Xu, Jie Shao, Zhiguo Jiang, Xianchao Zhang, Heng Tao Shen
分类: cs.CV
发布日期: 2025-07-25 (更新: 2025-11-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LISA,通过层级集成与抑制缓解多模态大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉缓解 层级集成 注意力机制 视觉语言理解
📋 核心要点
- 多模态大语言模型存在对象幻觉问题,即描述图像中不存在的对象,影响了模型的可靠性。
- LISA通过层级谱调制抑制深层激活,并使用基于锚点的路由融合不同层的token logits,实现自适应集成。
- 实验表明,LISA显著降低了幻觉率,并在多个基准测试中提升了性能,具有良好的泛化能力。
📝 摘要(中文)
多模态大语言模型(MLLMs)在图像描述等视觉-语言任务中表现出色,但仍然容易产生对象幻觉,即描述图像中不存在的对象。为了缓解这个问题,我们提出了LISA,一种层级集成与抑制方法。LISA利用MLLM中各层的功能角色:浅层提供视觉基础,中间层编码语义,深层倾向于放大虚假信号。首先,层级谱调制通过抑制深层中过度放大的激活来稳定注意力,同时保留早期层中的对齐线索。其次,来自选定层的token级logits通过基于锚点的路由进行融合,token级的锚点选择和软logit融合实现了在解码期间的自适应集成。LISA是完全即插即用的,可以无缝集成到现有的MLLM中,包括Qwen2.5-VL。在多个基准测试上的实验表明,LISA在$ ext{CHAIR}_ ext{I}$上最多可减少53.6%的幻觉,并在POPE F1上最多可提高5.1%,证明了跨模型和任务的强大泛化能力。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,但容易产生对象幻觉,即模型会描述图像中不存在的对象。现有的方法通常难以区分真实对象和幻觉,导致模型生成不准确的描述。这种幻觉问题严重影响了MLLM在实际应用中的可靠性。
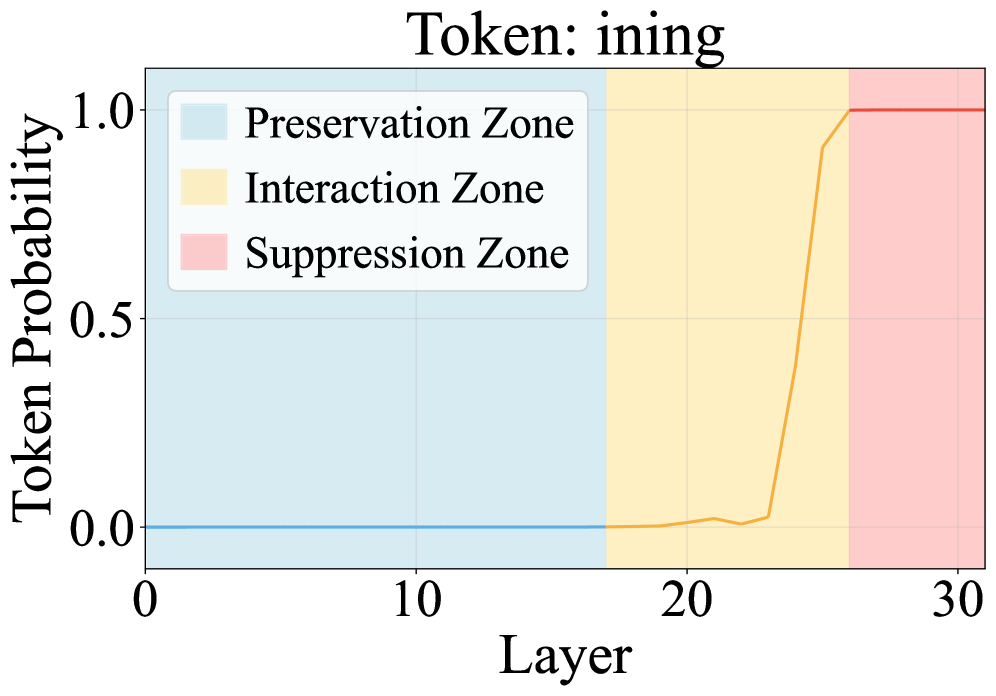
核心思路:LISA的核心思路是利用MLLM不同层的功能特性来缓解幻觉。浅层主要负责视觉信息的提取和对齐,中间层负责语义信息的编码,而深层则容易放大噪声和虚假信号,导致幻觉。因此,LISA通过抑制深层激活并融合浅层和中间层的信息,从而减少幻觉的产生。
技术框架:LISA包含两个主要模块:层级谱调制(Layer-wise Spectral Modulation)和基于锚点的路由融合(Anchor-based Routing Fusion)。层级谱调制通过调整不同层的激活谱来抑制深层激活,保留浅层对齐信息。基于锚点的路由融合则选择不同层的token logits,并使用锚点机制进行加权融合,最终生成模型的输出。整个框架是即插即用的,可以方便地集成到现有的MLLM中。
关键创新:LISA的关键创新在于其层级的处理方式。它不是简单地对所有层进行统一处理,而是根据不同层的功能特性进行差异化处理。层级谱调制针对深层激活进行抑制,而基于锚点的路由融合则自适应地选择和融合不同层的token logits。这种层级处理方式能够更有效地缓解幻觉问题。
关键设计:层级谱调制通过计算每一层的激活谱,并根据谱的分布来调整激活值。具体来说,它会抑制激活谱中能量较高的部分,从而减少深层激活的放大效应。基于锚点的路由融合则使用token级的锚点选择机制,根据每个token的重要性来选择不同层的logits。软logit融合则使用加权平均的方式将不同层的logits进行融合,权重由锚点值决定。
🖼️ 关键图片


📊 实验亮点
LISA在多个基准测试中取得了显著的性能提升。在$ ext{CHAIR}_ ext{I}$数据集上,LISA最多可减少53.6%的幻觉。在POPE数据集上,LISA的F1值最多可提高5.1%。这些结果表明,LISA能够有效地缓解多模态大语言模型中的幻觉问题,并且具有良好的泛化能力,可以应用于不同的模型和任务。
🎯 应用场景
LISA可应用于各种需要可靠视觉-语言理解的场景,例如智能客服、自动驾驶、医疗诊断等。通过减少多模态大语言模型中的幻觉,LISA可以提高这些应用的安全性和准确性,从而提升用户体验和决策质量。未来,LISA的思路可以推广到其他多模态任务和模型中,进一步提升多模态人工智能的可靠性。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) excel in vision-language tasks such as image captioning but remain prone to object hallucinations, where they describe objects that do not appear in the image. To mitigate this, we propose LISA, a Layer-wise Integration and Suppression Approach. LISA leverages the layer-wise functional roles in MLLMs: shallow layers provide visual grounding, middle layers encode semantics, and deep layers tend to amplify spurious signals. First, layer-wise spectral modulation stabilizes attention by suppressing over-amplified activations in deeper layers while preserving alignment cues in earlier layers. Second, token-level logits from selected layers are fused via anchor-based routing, with token-wise anchor selection and soft logit fusion enabling adaptive integration during decoding. LISA is fully plug-and-play and can be seamlessly integrated into existing MLLMs, including Qwen2.5-VL. Experiments on multiple benchmarks show that LISA reduces hallucinations by up to 53.6% in $\text{CHAIR}_\text{I}$ and improves POPE F1 by up to 5.1%, demonstrating strong generalization across models and tasks. Our code is available at https://github.com/zhlisa1010-eng/LISA.