Closing the Modality Gap for Mixed Modality Search
作者: Binxu Li, Yuhui Zhang, Xiaohan Wang, Weixin Liang, Ludwig Schmidt, Serena Yeung-Levy
分类: cs.CV, cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2025-07-25
备注: Project page: https://yuhui-zh15.github.io/MixedModalitySearch/
💡 一句话要点
提出GR-CLIP以消除CLIP在混合模态搜索中的模态差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合模态搜索 视觉-语言模型 CLIP 模态差异 后处理校准
📋 核心要点
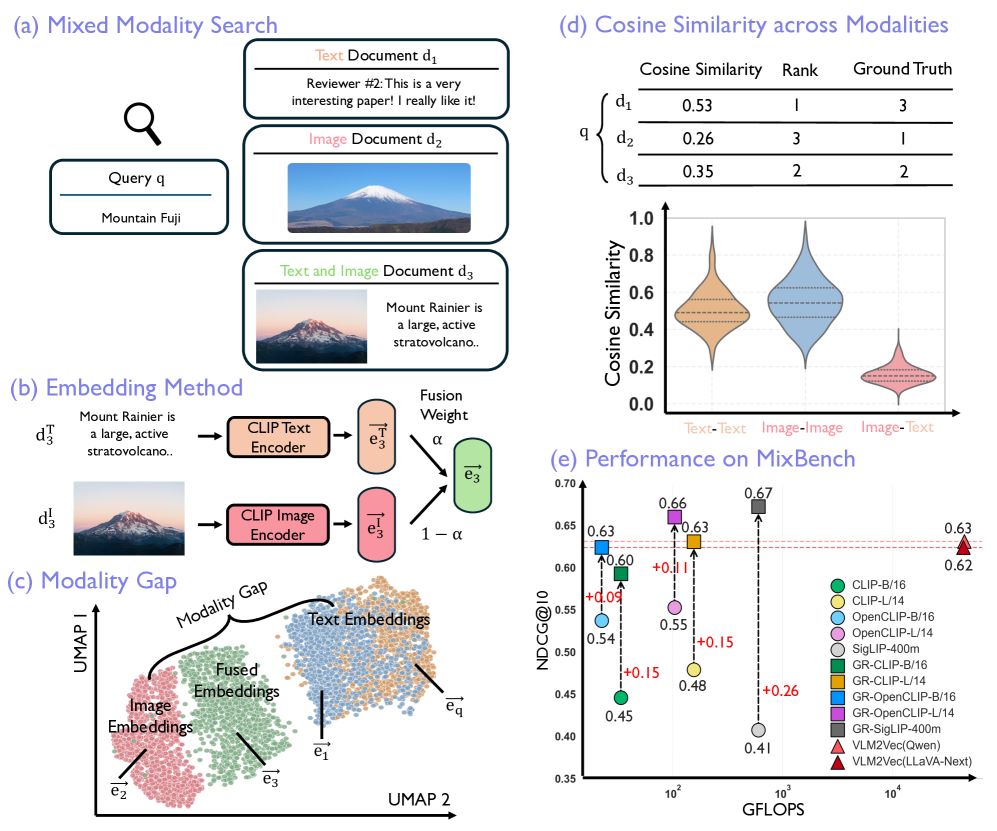
- 现有CLIP模型在混合模态搜索中表现出模态差异,导致图像和文本嵌入分离,影响检索性能。
- GR-CLIP是一种轻量级的后处理校准方法,旨在消除CLIP嵌入空间中的模态差异,提升跨模态检索效果。
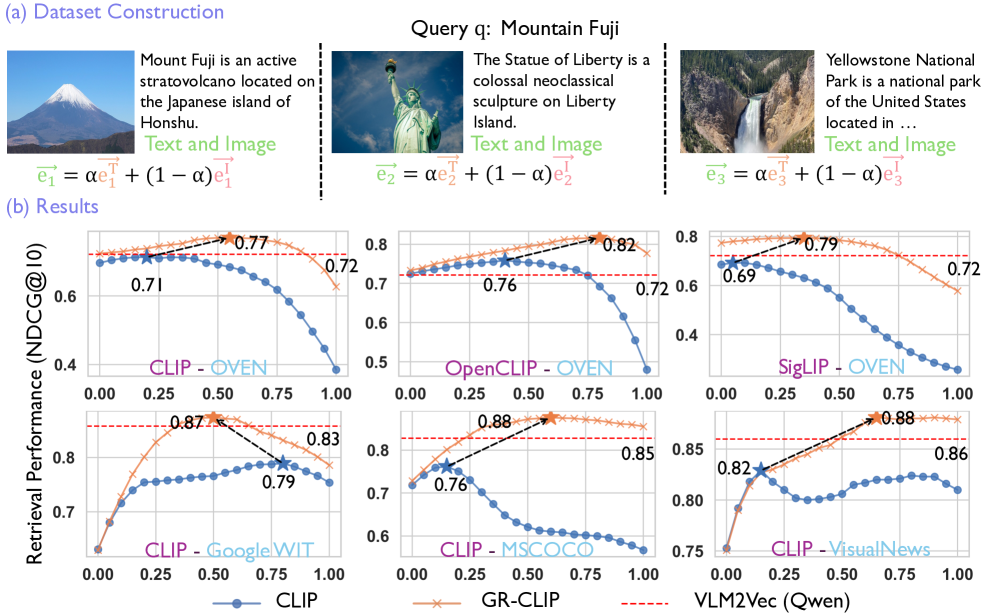
- 在MixBench基准测试中,GR-CLIP显著优于CLIP和其他视觉-语言模型,同时计算成本更低。
📝 摘要(中文)
混合模态搜索是一种重要的但未被充分探索的实际应用,它旨在检索由图像、文本和多模态文档组成的异构语料库中的信息。本文研究了对比视觉-语言模型(如CLIP)在混合模态搜索任务中的表现。分析表明,这些模型在嵌入空间中存在明显的模态差异,图像和文本嵌入形成不同的簇,导致模态内排序偏差和模态间融合失败。为了解决这个问题,我们提出了一种轻量级的后处理校准方法GR-CLIP,它可以消除CLIP嵌入空间中的模态差异。在MixBench(第一个专门为混合模态搜索设计的基准)上的评估表明,GR-CLIP相比CLIP,NDCG@10提高了高达26个百分点,超过了最近的视觉-语言生成嵌入模型4个百分点,同时计算量减少了75倍。
🔬 方法详解
问题定义:论文旨在解决混合模态搜索中,由于CLIP等视觉-语言模型存在模态差异,导致图像和文本嵌入在特征空间中分离,从而影响跨模态检索性能的问题。现有方法无法有效弥合这种模态差异,导致检索结果存在偏差。
核心思路:论文的核心思路是通过后处理校准的方式,对CLIP的嵌入空间进行调整,使得图像和文本的嵌入更加紧密地对齐,从而消除模态差异。这种方法无需重新训练模型,计算成本较低,且易于实现。
技术框架:GR-CLIP的技术框架主要包含以下几个步骤:1) 使用CLIP提取图像和文本的嵌入;2) 对嵌入进行归一化处理;3) 使用提出的校准方法对嵌入进行调整,消除模态差异;4) 使用调整后的嵌入进行混合模态搜索。整体流程简单高效,易于集成到现有系统中。
关键创新:GR-CLIP的关键创新在于提出了一种轻量级的后处理校准方法,能够有效地消除CLIP嵌入空间中的模态差异。该方法不需要额外的训练数据或计算资源,即可显著提升混合模态搜索的性能。与需要大量计算资源进行训练的生成式模型相比,GR-CLIP具有更高的效率。
关键设计:GR-CLIP的具体校准方法细节未知,摘要中未详细说明。但可以推测,可能涉及到对图像和文本嵌入进行线性变换或非线性映射,以使其在特征空间中更加接近。损失函数的设计可能考虑了图像和文本嵌入之间的距离,以及检索结果的排序质量。
🖼️ 关键图片

📊 实验亮点
GR-CLIP在MixBench基准测试中,相比CLIP,NDCG@10指标提升了高达26个百分点,显著优于CLIP。同时,GR-CLIP也超越了最近的视觉-语言生成嵌入模型4个百分点,而计算量却减少了75倍。这些实验结果表明,GR-CLIP是一种高效且有效的混合模态搜索解决方案。
🎯 应用场景
该研究成果可广泛应用于各种混合模态搜索场景,例如电商平台上的商品搜索、新闻聚合平台上的信息检索、以及多媒体数据库中的内容查找。通过提升跨模态检索的准确性和效率,可以改善用户体验,提高信息获取的效率,并为相关应用带来更大的商业价值。
📄 摘要(原文)
Mixed modality search -- retrieving information across a heterogeneous corpus composed of images, texts, and multimodal documents -- is an important yet underexplored real-world application. In this work, we investigate how contrastive vision-language models, such as CLIP, perform on the mixed modality search task. Our analysis reveals a critical limitation: these models exhibit a pronounced modality gap in the embedding space, where image and text embeddings form distinct clusters, leading to intra-modal ranking bias and inter-modal fusion failure. To address this issue, we propose GR-CLIP, a lightweight post-hoc calibration method that removes the modality gap in CLIP's embedding space. Evaluated on MixBench -- the first benchmark specifically designed for mixed modality search -- GR-CLIP improves NDCG@10 by up to 26 percentage points over CLIP, surpasses recent vision-language generative embedding models by 4 percentage points, while using 75x less compute.