TeEFusion: Blending Text Embeddings to Distill Classifier-Free Guidance
作者: Minghao Fu, Guo-Hua Wang, Xiaohao Chen, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang
分类: cs.CV
发布日期: 2025-07-24 (更新: 2025-07-25)
备注: Accepted by ICCV 2025. The code is publicly available at https://github.com/AIDC-AI/TeEFusion
🔗 代码/项目: GITHUB
💡 一句话要点
TeEFusion:融合文本嵌入蒸馏无分类器引导,加速文本到图像生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 文本到图像生成 无分类器引导 知识蒸馏 文本嵌入融合 模型加速
📋 核心要点
- 无分类器引导(CFG)虽然能提升图像质量,但需要两次前向传播,显著增加了文本到图像生成模型的推理成本。
- TeEFusion通过融合条件和非条件文本嵌入,将引导信息直接融入文本嵌入中,无需额外参数即可实现知识蒸馏。
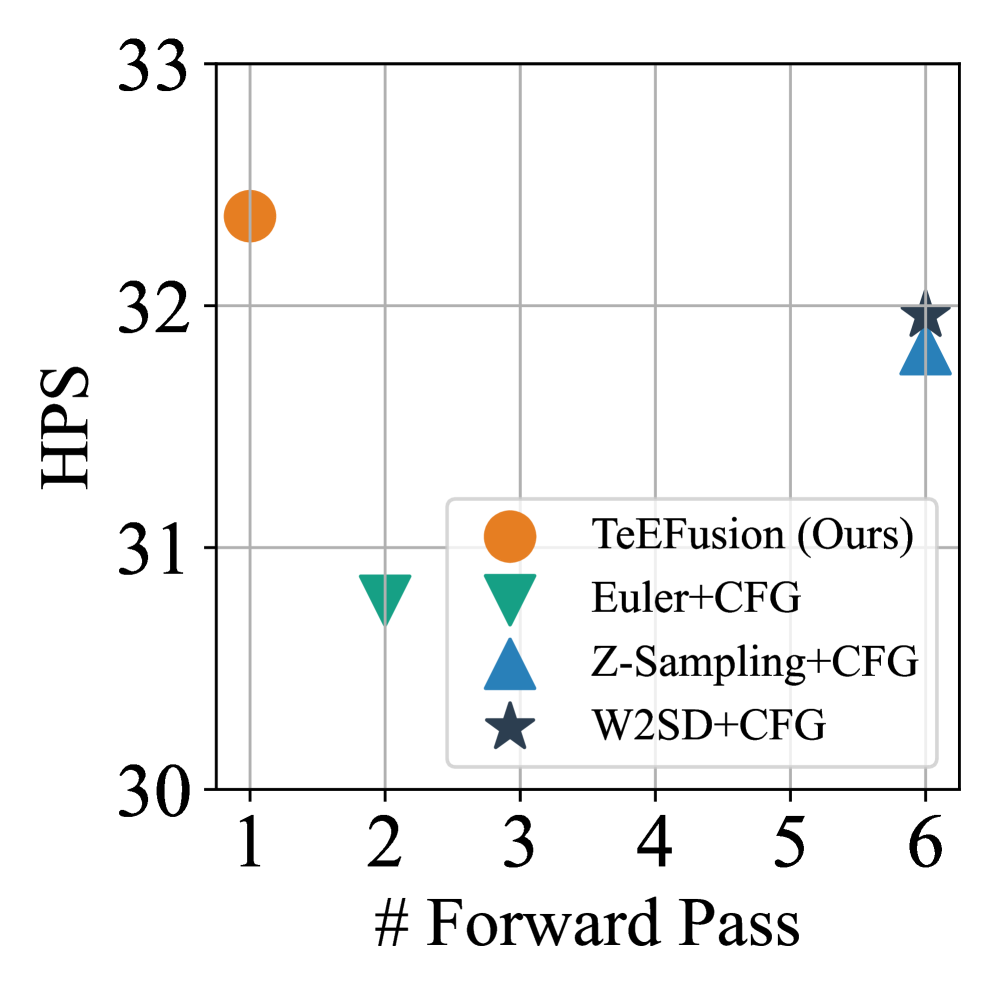
- 实验表明,TeEFusion能使学生模型在保持图像质量的同时,推理速度提升高达6倍,有效降低了计算成本。
📝 摘要(中文)
本文提出了一种新颖高效的蒸馏方法TeEFusion(文本嵌入融合),旨在解决文本到图像合成中,无分类器引导(CFG)因依赖两次前向传播而导致的推理成本过高的问题。TeEFusion直接将引导幅度融入文本嵌入中,并蒸馏教师模型的复杂采样策略。通过简单的线性运算融合条件和非条件文本嵌入,TeEFusion无需额外参数即可重建所需的引导,同时使学生模型能够学习教师模型通过其复杂采样方法产生的输出。在SD3等先进模型上的大量实验表明,我们的方法允许学生模型以更简单高效的采样策略,紧密模仿教师模型的性能。因此,学生模型实现了高达6倍于教师模型的推理速度,同时保持了与教师复杂采样方法相当的图像质量。代码已公开。
🔬 方法详解
问题定义:当前文本到图像生成模型依赖无分类器引导(CFG)来提升生成质量,但CFG需要分别计算条件和非条件文本嵌入,导致推理过程中需要两次前向传播,计算成本高昂,尤其是在结合复杂的采样策略时,这一问题更加突出。现有方法难以在保证生成质量的同时,显著降低推理时间。
核心思路:TeEFusion的核心思路是将教师模型中CFG的引导信息直接蒸馏到学生模型的文本嵌入中。通过融合条件和非条件文本嵌入,学生模型可以在一次前向传播中获得与教师模型使用CFG相似的生成效果,从而避免了两次前向传播带来的额外计算开销。这种方法旨在简化推理过程,提高效率。
技术框架:TeEFusion的整体框架包括以下几个步骤:首先,利用教师模型(例如Stable Diffusion 3)及其复杂的采样策略生成高质量的图像。然后,通过线性运算融合条件文本嵌入和非条件文本嵌入,得到融合后的文本嵌入。最后,使用融合后的文本嵌入训练学生模型,使其能够模仿教师模型的生成效果。学生模型使用更简单的采样策略。
关键创新:TeEFusion的关键创新在于提出了一种新的文本嵌入融合方法,能够将CFG的引导信息有效地蒸馏到文本嵌入中。与传统的知识蒸馏方法不同,TeEFusion不需要额外的参数或复杂的训练过程,而是通过简单的线性运算实现文本嵌入的融合,从而简化了推理过程,提高了效率。
关键设计:TeEFusion的关键设计包括:1) 线性融合操作:使用线性加权的方式融合条件和非条件文本嵌入,权重系数决定了引导的强度。2) 损失函数:使用合适的损失函数(具体损失函数类型未知)来训练学生模型,使其能够模仿教师模型的生成效果。3) 学生模型的网络结构:学生模型的网络结构可以与教师模型相同或简化,具体取决于对推理速度和生成质量的权衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TeEFusion能够使学生模型在保持与教师模型相当的图像质量的前提下,推理速度提升高达6倍。例如,在SD3模型上,学生模型通过TeEFusion学习后,能够以更简单的采样策略达到与教师模型使用复杂采样策略相似的生成效果,显著降低了计算成本。
🎯 应用场景
TeEFusion可应用于各种文本到图像生成场景,尤其适用于对推理速度有较高要求的应用,如移动端图像生成、实时图像编辑、以及需要快速迭代设计的场景。该方法能够降低计算成本,使更多用户能够体验到高质量的文本到图像生成服务,并加速相关产品的开发和部署。
📄 摘要(原文)
Recent advances in text-to-image synthesis largely benefit from sophisticated sampling strategies and classifier-free guidance (CFG) to ensure high-quality generation. However, CFG's reliance on two forward passes, especially when combined with intricate sampling algorithms, results in prohibitively high inference costs. To address this, we introduce TeEFusion (Text Embeddings Fusion), a novel and efficient distillation method that directly incorporates the guidance magnitude into the text embeddings and distills the teacher model's complex sampling strategy. By simply fusing conditional and unconditional text embeddings using linear operations, TeEFusion reconstructs the desired guidance without adding extra parameters, simultaneously enabling the student model to learn from the teacher's output produced via its sophisticated sampling approach. Extensive experiments on state-of-the-art models such as SD3 demonstrate that our method allows the student to closely mimic the teacher's performance with a far simpler and more efficient sampling strategy. Consequently, the student model achieves inference speeds up to 6$\times$ faster than the teacher model, while maintaining image quality at levels comparable to those obtained through the teacher's complex sampling approach. The code is publicly available at https://github.com/AIDC-AI/TeEFusion.