BokehDiff: Neural Lens Blur with One-Step Diffusion
作者: Chengxuan Zhu, Qingnan Fan, Qi Zhang, Jinwei Chen, Huaqi Zhang, Chao Xu, Boxin Shi
分类: cs.CV
发布日期: 2025-07-24 (更新: 2025-10-20)
备注: Accepted by ICCV 2025
💡 一句话要点
BokehDiff:利用单步扩散模型实现逼真神经镜头模糊渲染
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 镜头模糊 扩散模型 神经渲染 图像生成 自注意力机制
📋 核心要点
- 现有镜头模糊方法依赖深度估计,在深度不连续处易产生伪影,影响渲染质量。
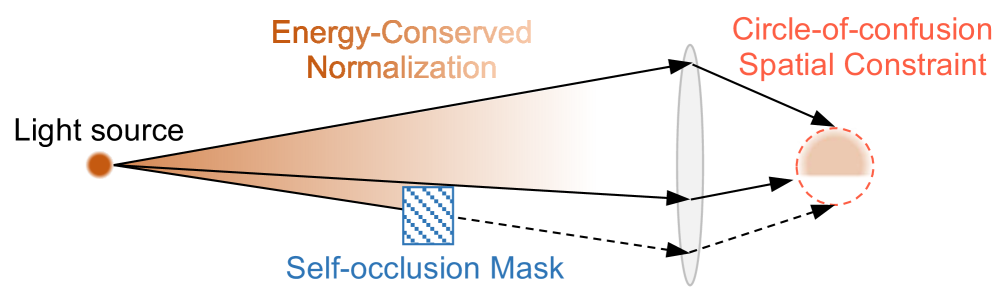
- BokehDiff利用物理启发的自注意力模块,结合深度信息和自遮挡效应,模拟真实镜头模糊。
- 该方法采用单步扩散模型进行快速高质量渲染,并使用扩散模型合成训练数据,提升模型泛化性。
📝 摘要(中文)
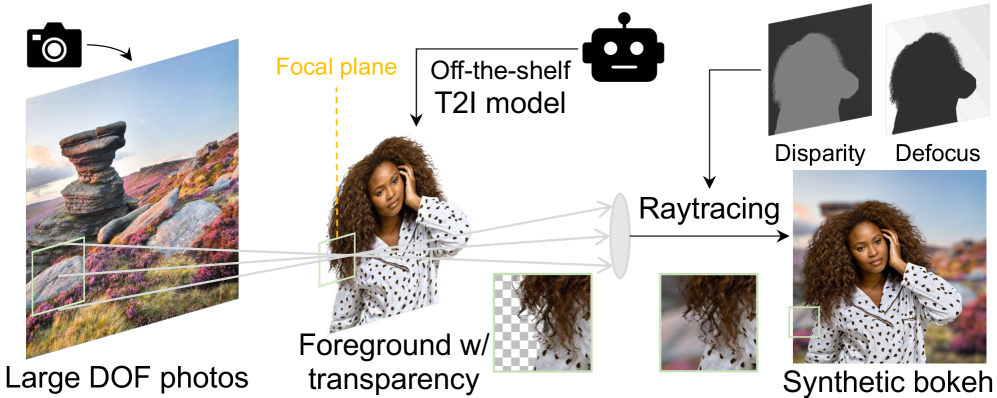
本文提出了一种新的镜头模糊渲染方法BokehDiff,它借助生成扩散先验,实现了物理上精确且视觉上吸引人的效果。以往的方法受到深度估计精度的限制,在深度不连续处会产生伪影。我们的方法采用了一种受物理启发的自注意力模块,该模块与图像形成过程对齐,结合了深度相关的模糊圈约束和自遮挡效应。我们调整了扩散模型,使其适应单步推理方案,无需引入额外的噪声,并获得了高质量和高保真的结果。为了解决缺乏可扩展的配对数据的问题,我们提出使用扩散模型合成具有透明度的逼真前景,从而平衡真实性和场景多样性。
🔬 方法详解
问题定义:论文旨在解决现有镜头模糊渲染方法对深度估计精度依赖过高的问题。传统方法在深度不连续区域容易产生伪影,影响渲染效果的真实性和视觉质量。此外,缺乏大规模高质量的配对训练数据也是一个挑战。
核心思路:论文的核心思路是利用扩散模型的生成能力,结合物理成像原理,直接从单张图像生成高质量的镜头模糊效果。通过物理启发的自注意力机制,模拟光圈形状和自遮挡效应,从而更准确地模拟真实相机的成像过程。
技术框架:BokehDiff的整体框架包含以下几个主要部分:1) 物理启发的自注意力模块,用于模拟镜头模糊效果,该模块考虑了深度相关的模糊圈和自遮挡;2) 单步扩散模型,用于快速生成高质量的模糊图像,避免了传统扩散模型的多步迭代;3) 数据合成模块,使用扩散模型生成带有透明度的逼真前景,用于扩充训练数据集。
关键创新:该方法最重要的创新点在于将物理成像原理与扩散模型相结合,提出了一种新的镜头模糊渲染框架。与传统方法相比,该方法不再依赖于精确的深度估计,而是直接从图像中学习模糊效果,从而避免了深度估计误差带来的伪影。此外,单步扩散模型的应用大大提高了渲染速度。
关键设计:物理启发的自注意力模块是关键设计之一,它通过引入深度相关的模糊圈约束和自遮挡效应,模拟了真实相机的成像过程。单步扩散模型的设计也至关重要,它需要在保证渲染质量的同时,尽可能地减少计算量。此外,数据合成模块的设计也需要保证生成图像的真实性和多样性,以提高模型的泛化能力。具体的损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
论文提出的BokehDiff方法在镜头模糊渲染任务上取得了显著的成果。通过与现有方法的对比实验表明,BokehDiff能够生成更高质量、更逼真的模糊效果,尤其是在深度不连续区域,能够有效避免伪影的产生。单步扩散模型的应用也使得渲染速度得到了显著提升(具体数据未知)。
🎯 应用场景
BokehDiff具有广泛的应用前景,例如照片编辑、电影特效、虚拟现实和增强现实等领域。它可以用于快速生成高质量的镜头模糊效果,提升图像和视频的视觉质量。此外,该方法还可以应用于图像修复和图像增强等任务,例如去除图像中的噪声和伪影,提高图像的清晰度。
📄 摘要(原文)
We introduce BokehDiff, a novel lens blur rendering method that achieves physically accurate and visually appealing outcomes, with the help of generative diffusion prior. Previous methods are bounded by the accuracy of depth estimation, generating artifacts in depth discontinuities. Our method employs a physics-inspired self-attention module that aligns with the image formation process, incorporating depth-dependent circle of confusion constraint and self-occlusion effects. We adapt the diffusion model to the one-step inference scheme without introducing additional noise, and achieve results of high quality and fidelity. To address the lack of scalable paired data, we propose to synthesize photorealistic foregrounds with transparency with diffusion models, balancing authenticity and scene diversity.