C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
作者: Xiuwei Chen, Wentao Hu, Hanhui Li, Jun Zhou, Zisheng Chen, Meng Cao, Yihan Zeng, Kui Zhang, Yu-Jie Yuan, Jianhua Han, Hang Xu, Xiaodan Liang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-07-22 (更新: 2025-07-29)
💡 一句话要点
C2-Evo:协同进化多模态数据与模型,实现自我提升的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 自我提升 协同进化 数学推理 数据增强
📋 核心要点
- 现有MLLM提升受限于高质量视觉-语言数据集的获取,成本高昂且难以扩展。
- C2-Evo通过跨模态数据和数据-模型协同进化,自动生成训练数据并提升模型能力。
- 实验表明,C2-Evo在多个数学推理基准测试中持续获得显著的性能提升。
📝 摘要(中文)
多模态大型语言模型(MLLM)在推理能力方面取得了显著进展。然而,进一步提升现有MLLM需要高质量的视觉-语言数据集,这些数据集需要精心策划的任务复杂性,而这既昂贵又难以扩展。虽然最近的自我提升模型通过迭代改进自身提供了一个可行的解决方案,但它们仍然面临两个核心挑战:(i)大多数现有方法分别增强视觉或文本数据,导致数据复杂性不一致(例如,过于简化的图表与冗余的文本描述配对);(ii)数据和模型的演化也是分离的,导致模型暴露于难度不匹配的任务中。为了解决这些问题,我们提出了C2-Evo,一个自动的、闭环的自我提升框架,它共同进化训练数据和模型能力。具体来说,给定一个基础数据集和一个基础模型,C2-Evo通过跨模态数据进化循环和数据-模型进化循环来增强它们。前者通过生成复杂的、结合了结构化文本子问题和迭代指定的几何图的多模态问题来扩展基础数据集,而后者根据基础模型的性能自适应地选择生成的问题,以交替地进行监督微调和强化学习。因此,我们的方法不断改进其模型和训练数据,并在多个数学推理基准测试中持续获得可观的性能提升。我们的代码、模型和数据集将会发布。
🔬 方法详解
问题定义:现有方法在增强MLLM时,通常独立地增强视觉或文本数据,导致模态间数据复杂性不匹配。此外,数据和模型的演化是分离的,模型可能暴露于难度不匹配的任务中,影响训练效果。因此,需要一种能够协同进化数据和模型的方法,以更有效地提升MLLM的推理能力。
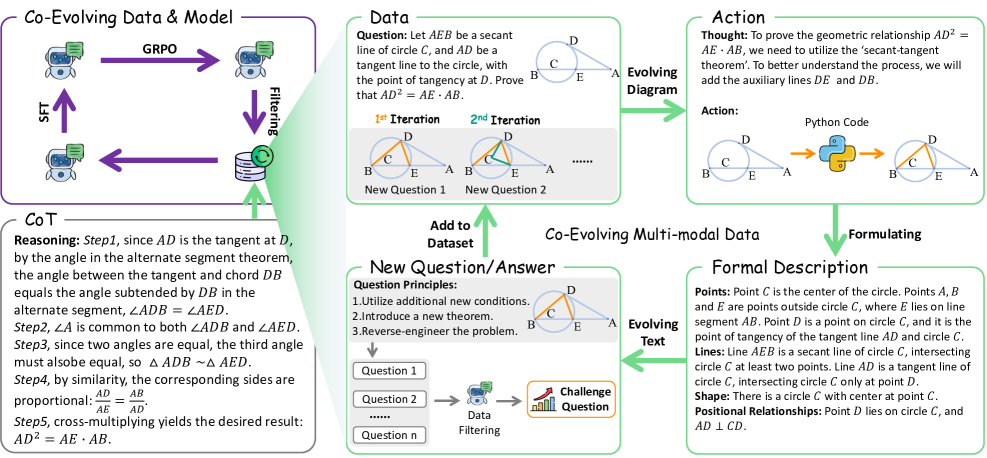
核心思路:C2-Evo的核心思路是构建一个闭环的自我提升框架,通过跨模态数据进化和数据-模型进化两个循环,协同地生成更具挑战性的训练数据,并根据模型在这些数据上的表现自适应地调整训练策略。这种协同进化确保了数据复杂性和模型能力之间的匹配,从而更有效地提升模型性能。
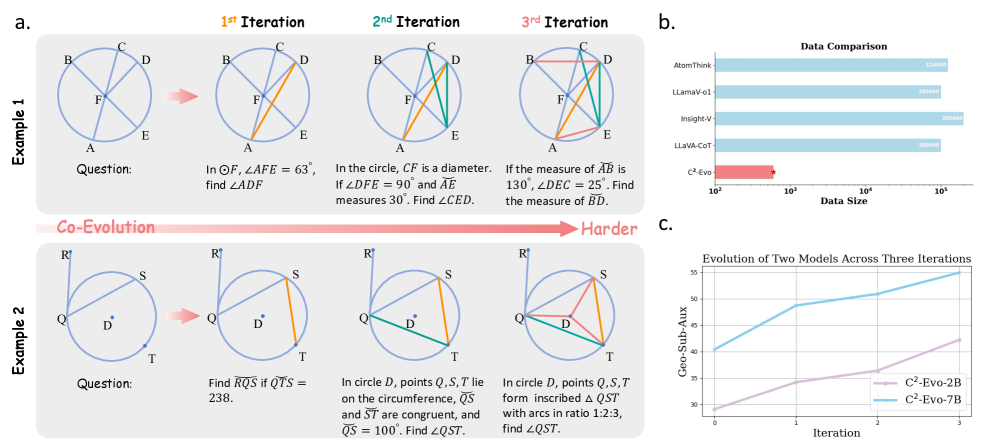
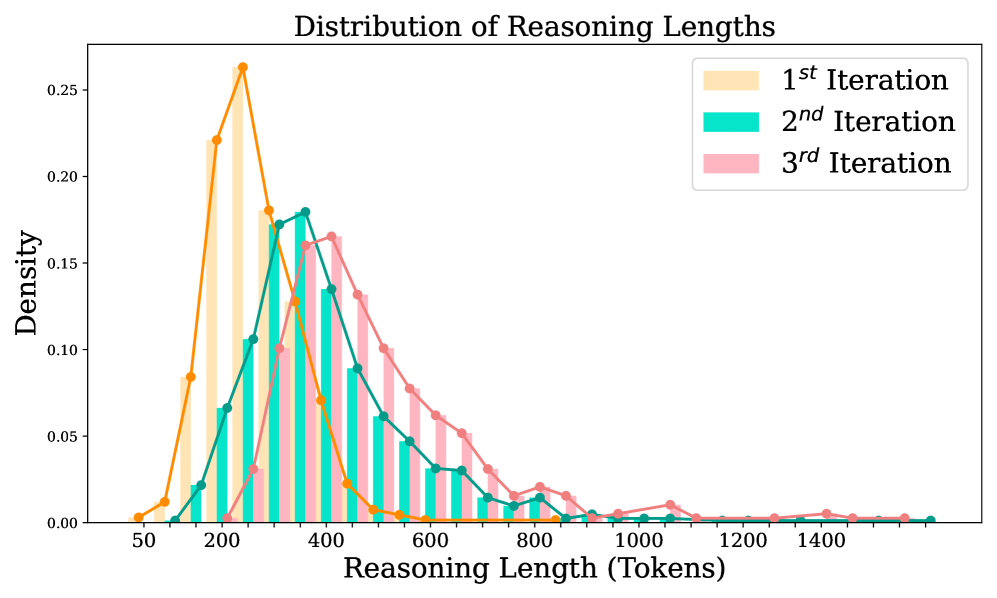
技术框架:C2-Evo包含两个主要循环:跨模态数据进化循环和数据-模型进化循环。跨模态数据进化循环负责生成新的训练数据,它结合了结构化的文本子问题和迭代指定的几何图,生成更复杂的数学推理问题。数据-模型进化循环则根据当前模型的性能,自适应地选择生成的问题进行训练,交替使用监督微调和强化学习来提升模型能力。
关键创新:C2-Evo的关键创新在于其协同进化数据和模型的能力。与以往独立增强数据或模型的方法不同,C2-Evo通过两个循环将数据生成和模型训练紧密结合,实现了数据复杂性和模型能力的动态匹配。这种协同进化能够更有效地利用数据,并引导模型向更强的推理能力发展。
关键设计:在跨模态数据进化循环中,如何生成既具有挑战性又与模型能力相匹配的训练数据是关键。论文可能采用了某种策略来控制生成问题的难度,例如通过调整文本子问题的复杂度和几何图的迭代次数。在数据-模型进化循环中,如何根据模型性能选择训练数据,以及如何平衡监督微调和强化学习,也是重要的设计考虑。具体的损失函数和网络结构细节未知,需要查阅论文原文。
🖼️ 关键图片
📊 实验亮点
C2-Evo在多个数学推理基准测试中取得了显著的性能提升,证明了其协同进化数据和模型策略的有效性。具体的性能数据和对比基线需要在论文原文中查找,但摘要中明确指出获得了“可观的性能提升”。
🎯 应用场景
C2-Evo框架可应用于提升各种多模态大型语言模型的推理能力,尤其是在需要复杂视觉-语言理解和推理的场景,如数学问题求解、科学图表理解、机器人导航等。该方法能够自动生成高质量的训练数据,降低了人工标注成本,并有望推动多模态人工智能的进一步发展。
📄 摘要(原文)
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.