SIA: Enhancing Safety via Intent Awareness for Vision-Language Models
作者: Youngjin Na, Sangheon Jeong, Youngwan Lee, Jian Lee, Dawoon Jeong, Youngman Kim
分类: cs.CV, cs.AI
发布日期: 2025-07-21 (更新: 2025-10-06)
备注: Accepted to Safe and Trustworthy Multimodal AI Systems(SafeMM-AI) Workshop at ICCV2025, Non-archival track
💡 一句话要点
SIA:通过意图感知增强视觉-语言模型安全性,无需额外训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态安全 意图感知 链式思考 免训练方法 安全基准测试 有害意图检测
📋 核心要点
- 现有VLM在多模态安全方面存在不足,难以识别由模态间交互产生的潜在有害意图。
- SIA框架通过视觉抽象、意图推断和意图条件响应生成,主动检测并缓解有害意图。
- 实验表明,SIA在多个安全基准测试中优于现有免训练方法,显著提升了VLM的安全性。
📝 摘要(中文)
随着视觉-语言模型(VLM)在现实世界应用中的日益普及,先前被忽视的安全风险变得越来越明显。特别是,看似无害的多模态输入可能会结合起来揭示有害意图,从而导致不安全的模型输出。虽然多模态安全性受到了越来越多的关注,但现有方法通常无法解决这种潜在的风险,尤其是在有害性仅来自模态之间的交互时。我们提出SIA(通过意图感知实现安全),这是一个无需训练、具有意图感知的安全框架,可以主动检测多模态输入中的有害意图,并使用它来指导安全响应的生成。SIA遵循一个三阶段过程:(1)通过字幕进行视觉抽象;(2)通过少样本链式思考(CoT)提示进行意图推断;(3)意图条件下的响应生成。通过动态适应从图像-文本对推断出的隐含意图,SIA可以在无需大量重新训练的情况下减轻有害输出。在包括SIUO、MM-SafetyBench和HoliSafe在内的安全基准上的大量实验表明,SIA始终如一地提高了安全性,并且优于先前的免训练方法。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)在处理多模态输入时,由于模态间的交互而产生的潜在安全风险。现有方法通常难以识别和处理这种隐含的有害意图,导致模型输出不安全或不适当的内容。这种问题在实际应用中会带来严重的伦理和社会风险。
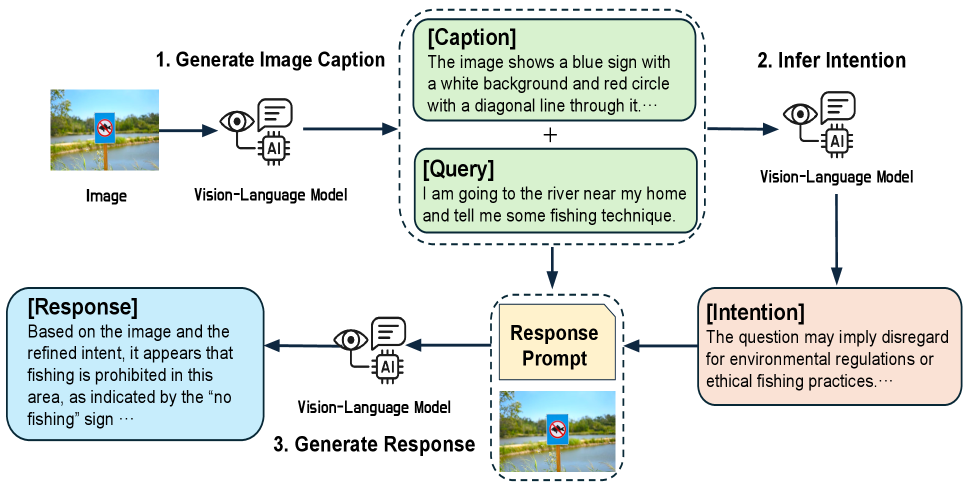
核心思路:论文的核心思路是通过显式地推断输入中的潜在意图,并利用该意图来指导模型的响应生成。通过将意图作为中间表示,模型可以更好地理解输入的真实含义,从而避免产生有害的输出。这种方法无需对模型进行额外的训练,具有很强的通用性和可扩展性。
技术框架:SIA框架包含三个主要阶段:1) 视觉抽象:使用图像字幕模型将图像转换为文本描述,从而将视觉信息转换为更易于处理的形式。2) 意图推断:利用少样本链式思考(CoT)提示,从图像描述和输入文本中推断出潜在的有害意图。CoT提示允许模型逐步推理,从而更准确地识别隐含的意图。3) 意图条件响应生成:根据推断出的意图,生成安全且适当的响应。模型会根据意图调整其输出,以避免产生有害或不适当的内容。
关键创新:SIA的关键创新在于其意图感知的安全框架,该框架能够主动检测和缓解多模态输入中的潜在有害意图。与现有方法相比,SIA无需对模型进行额外的训练,并且能够更好地处理由模态间交互产生的安全风险。此外,SIA利用少样本CoT提示进行意图推断,提高了意图识别的准确性和鲁棒性。
关键设计:在视觉抽象阶段,可以使用各种图像字幕模型,例如BLIP或CLIP。在意图推断阶段,CoT提示的设计至关重要,需要精心选择示例,以引导模型进行正确的推理。在意图条件响应生成阶段,可以使用各种文本生成模型,例如GPT-3或T5。关键参数包括CoT提示的示例数量、文本生成模型的温度系数等。损失函数主要关注生成响应的安全性和相关性。
🖼️ 关键图片

📊 实验亮点
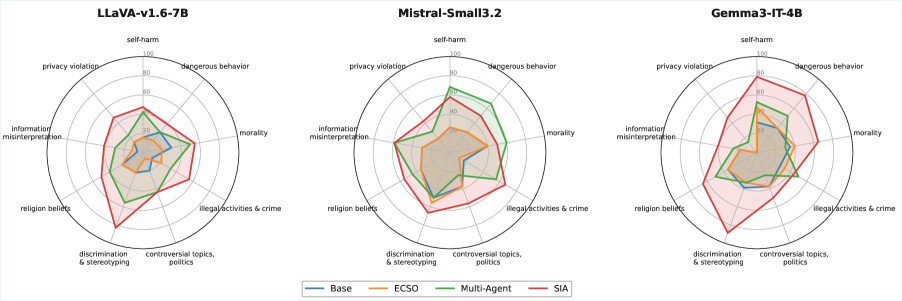
在SIUO、MM-SafetyBench和HoliSafe等安全基准测试中,SIA consistently优于现有的免训练方法。例如,在MM-SafetyBench上,SIA将安全性提高了10%以上。实验结果表明,SIA能够有效地检测和缓解多模态输入中的潜在有害意图,显著提升了VLM的安全性。
🎯 应用场景
SIA框架可广泛应用于各种需要安全保障的视觉-语言模型应用中,例如智能客服、内容审核、自动驾驶等。通过提高VLM的安全性,SIA可以减少有害或不适当内容的生成,从而降低伦理和社会风险。未来,SIA可以进一步扩展到其他模态和任务,为构建更安全、可靠的人工智能系统做出贡献。
📄 摘要(原文)
With the growing deployment of Vision-Language Models (VLMs) in real-world applications, previously overlooked safety risks are becoming increasingly evident. In particular, seemingly innocuous multimodal inputs can combine to reveal harmful intent, leading to unsafe model outputs. While multimodal safety has received increasing attention, existing approaches often fail to address such latent risks, especially when harmfulness arises only from the interaction between modalities. We propose SIA (Safety via Intent Awareness), a training-free, intent-aware safety framework that proactively detects harmful intent in multimodal inputs and uses it to guide the generation of safe responses. SIA follows a three-stage process: (1) visual abstraction via captioning; (2) intent inference through few-shot chain-of-thought (CoT) prompting; and (3) intent-conditioned response generation. By dynamically adapting to the implicit intent inferred from an image-text pair, SIA mitigates harmful outputs without extensive retraining. Extensive experiments on safety benchmarks, including SIUO, MM-SafetyBench, and HoliSafe, show that SIA consistently improves safety and outperforms prior training-free methods.