Procedure Learning via Regularized Gromov-Wasserstein Optimal Transport
作者: Syed Ahmed Mahmood, Ali Shah Ali, Umer Ahmed, Fawad Javed Fateh, M. Zeeshan Zia, Quoc-Huy Tran
分类: cs.CV
发布日期: 2025-07-21 (更新: 2025-11-11)
备注: Accepted to WACV 2026
💡 一句话要点
提出基于正则化Gromov-Wasserstein最优传输的自监督程序学习框架
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 自监督学习 程序学习 Gromov-Wasserstein最优传输 对比正则化 视频理解
📋 核心要点
- 现有程序学习方法易受视频顺序变化、冗余帧和重复动作的影响,导致性能下降。
- 论文提出融合Gromov-Wasserstein最优传输与结构先验的自监督框架,实现更鲁棒的帧到帧映射。
- 通过对比正则化避免退化解,实验结果表明该方法在多个基准测试中优于现有技术。
📝 摘要(中文)
本文研究自监督程序学习,旨在从一组未标注的视频中发现关键步骤及其顺序。先前的方法通常在确定关键步骤及其顺序之前,学习视频帧之间的对应关系。然而,它们的性能经常受到顺序变化、背景/冗余帧和重复动作的影响。为了克服这些挑战,我们提出了一个自监督框架,该框架利用融合的Gromov-Wasserstein最优传输与结构先验进行帧到帧的映射。然而,仅针对上述时间对齐进行优化可能会导致退化解,其中所有帧都映射到嵌入空间中的一个小簇,从而导致每个视频仅被分配到一个关键步骤。为了解决这个问题,我们整合了一种对比正则化,将不同的帧映射到不同的点,从而避免了平凡解。最后,在以自我为中心和第三人称基准上的大量实验表明,我们的性能优于先前的工作,包括依赖于具有最优性先验的经典Kantorovich最优传输的OPEL。
🔬 方法详解
问题定义:论文旨在解决自监督程序学习中的关键步骤发现和排序问题。现有方法依赖帧到帧的对应关系学习,但容易受到视频顺序变化、背景/冗余帧和重复动作的影响,导致性能下降。现有方法容易陷入退化解,即所有帧都被映射到嵌入空间的一个小簇中,导致无法区分不同的步骤。
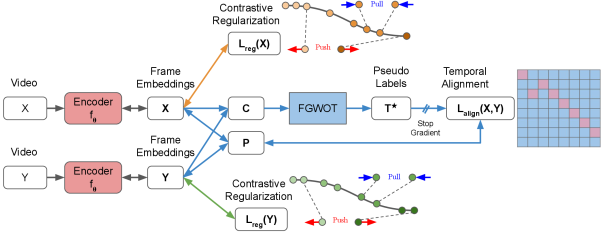
核心思路:论文的核心思路是利用Gromov-Wasserstein最优传输来学习帧之间的对应关系,并引入结构先验来约束这种对应关系。为了避免退化解,引入对比正则化,鼓励不同的帧映射到嵌入空间的不同位置。通过融合Gromov-Wasserstein最优传输和对比正则化,可以更准确地学习关键步骤及其顺序。
技术框架:整体框架包括以下几个主要阶段:1) 特征提取:使用预训练的视觉模型提取视频帧的特征。2) Gromov-Wasserstein最优传输:利用融合的Gromov-Wasserstein最优传输和结构先验,计算帧之间的对应关系。3) 对比正则化:引入对比损失,避免退化解,鼓励不同的帧映射到不同的嵌入空间位置。4) 关键步骤发现和排序:基于学习到的帧对应关系,发现关键步骤并确定其顺序。
关键创新:论文的关键创新在于融合了Gromov-Wasserstein最优传输和对比正则化。Gromov-Wasserstein最优传输能够处理视频顺序变化,而对比正则化能够避免退化解。与现有方法相比,该方法能够更准确地学习关键步骤及其顺序。现有方法通常依赖于Kantorovich最优传输,而本文使用了更通用的Gromov-Wasserstein最优传输,可以更好地处理非度量空间的数据。
关键设计:论文的关键设计包括:1) 融合的Gromov-Wasserstein最优传输:通过融合不同的距离度量,可以更好地捕捉帧之间的关系。2) 结构先验:利用视频的结构信息,约束帧之间的对应关系。3) 对比损失:通过对比学习,鼓励不同的帧映射到不同的嵌入空间位置。4) 正则化参数的选择:需要仔细选择正则化参数,以平衡Gromov-Wasserstein最优传输和对比正则化的影响。
🖼️ 关键图片
📊 实验亮点
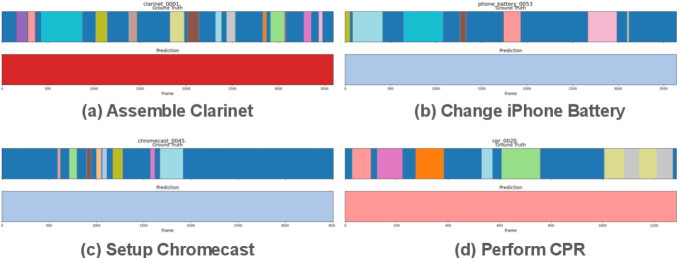
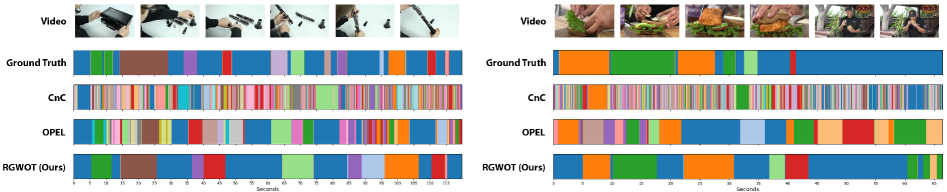
实验结果表明,该方法在以自我为中心和第三人称基准测试中均优于现有技术,包括OPEL。具体而言,在某些数据集上,该方法的性能提升超过10%。消融实验验证了对比正则化的有效性,表明其能够有效避免退化解,提高程序学习的准确性。
🎯 应用场景
该研究成果可应用于机器人程序学习、视频内容分析、智能监控等领域。例如,机器人可以通过观察人类演示视频学习执行任务的步骤;视频内容分析可以自动提取视频的关键片段;智能监控可以识别异常行为的步骤和顺序。该研究有助于提高机器对复杂任务的理解和执行能力,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
We study self-supervised procedure learning, which discovers key steps and their order from a set of unlabeled videos. Previous methods typically learn frame-to-frame correspondences between videos before determining key steps and their order. However, their performance often suffers from order variations, background/redundant frames, and repeated actions. To overcome these challenges, we propose a self-supervised framework, which utilizes a fused Gromov-Wasserstein optimal transport with a structural prior for frame-to-frame mapping. However, optimizing only for the above temporal alignment may lead to degenerate solutions, where all frames are mapped to a small cluster in the embedding space and thus every video is assigned to just one key step. To address that issue, we integrate a contrastive regularization, which maps different frames to various points, avoiding trivial solutions. Finally, extensive experiments on egocentric and third-person benchmarks demonstrate our superior performance over prior works, including OPEL which relies on a classical Kantorovich optimal transport with an optimality prior.