Language Integration in Fine-Tuning Multimodal Large Language Models for Image-Based Regression
作者: Roy H. Jennings, Genady Paikin, Roy Shaul, Evgeny Soloveichik
分类: cs.CV, cs.LG
发布日期: 2025-07-20 (更新: 2025-12-08)
备注: WACV 2026
💡 一句话要点
提出RvTC框架,结合数据特定提示,提升多模态大模型在图像回归任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 图像回归 跨模态理解 语义提示 Transformer分类
📋 核心要点
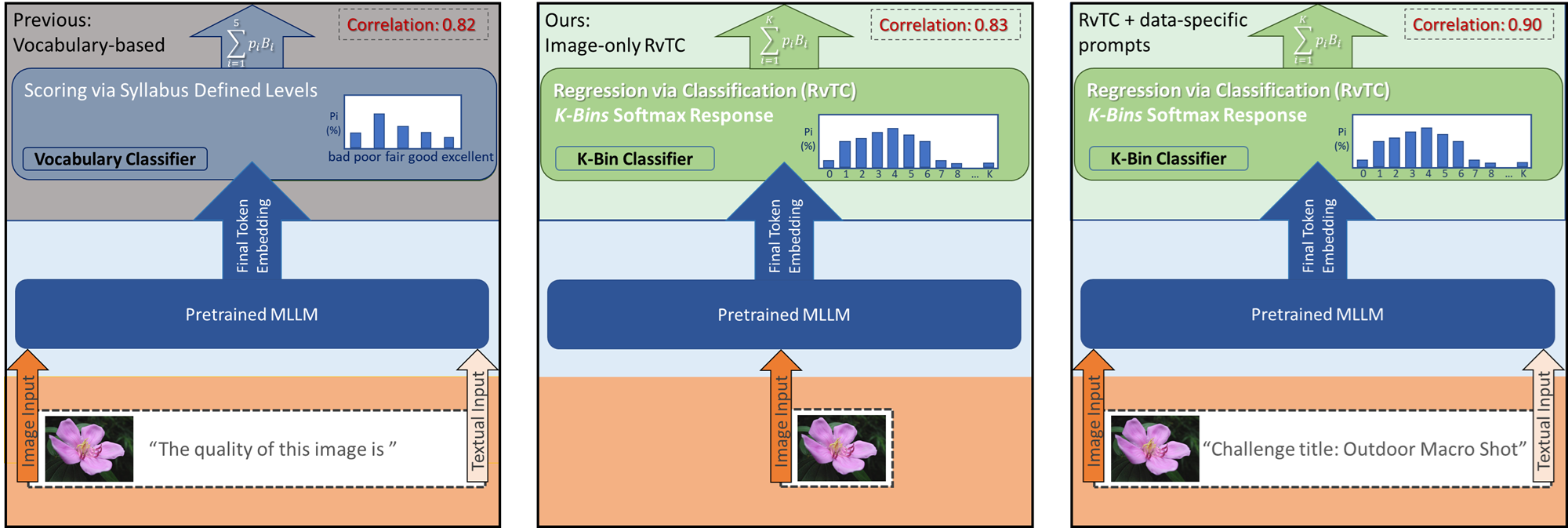
- 现有MLLM图像回归方法依赖预设词汇表和通用提示,未能有效利用文本语义信息。
- 提出RvTC框架,采用基于bin的灵活分类,并结合数据特定提示,增强跨模态理解。
- 实验表明,RvTC在多个图像评估数据集上取得SOTA性能,并验证了方法的通用性。
📝 摘要(中文)
多模态大语言模型(MLLM)在基于图像的回归任务中展现出潜力,但现有方法存在关键局限。目前的方法使用预设的输出词汇表和通用的任务级提示(例如,“你如何评价这张图片?”)来微调MLLM,并假设这可以模仿人类的评分行为。我们的分析表明,这些方法并没有比仅使用图像进行训练带来任何好处。使用预设词汇表和通用提示的模型与仅使用图像的模型表现相当,无法利用文本输入的语义理解。我们提出了基于Transformer分类的回归(RvTC),它用灵活的基于bin的方法取代了受词汇表约束的分类。与通过复杂分布建模来解决离散化误差的方法不同,RvTC通过简单的bin增加来消除手动词汇表制作,仅使用图像就在四个图像评估数据集上实现了最先进的性能。更重要的是,我们证明了数据特定的提示可以显著提高性能。与通用的任务描述不同,包含关于特定图像的语义信息的提示使MLLM能够利用跨模态理解。在AVA数据集上,将挑战标题添加到提示中,大大提高了我们已经是最先进的仅图像基线。我们通过来自AVA和AGIQA-3k数据集的经验证据表明,MLLM受益于语义提示信息,超越了单纯的统计偏差。我们在两种不同的MLLM架构上验证了RvTC,证明了一致的改进和方法的通用性。
🔬 方法详解
问题定义:现有基于MLLM的图像回归方法,通常采用预设的输出词汇表和通用的任务级提示,例如“这张图片你觉得怎么样?”。这种方式无法充分利用文本模态的语义信息,导致模型性能与仅使用图像训练的模型相当,未能体现多模态融合的优势。现有方法在处理离散化误差时,往往采用复杂的分布建模,增加了模型复杂度。
核心思路:论文的核心思路是,通过更灵活的回归方式和更具语义信息的提示,来提升MLLM在图像回归任务中的性能。具体来说,采用基于bin的分类方法(RvTC)取代预设词汇表的分类,并利用数据特定的提示(例如,包含图像挑战标题的提示)来引导模型学习跨模态的关联。
技术框架:RvTC框架主要包含以下几个阶段:1) 图像特征提取:使用预训练的视觉模型提取图像的视觉特征。2) 文本提示构建:根据任务和数据集,构建包含语义信息的文本提示。3) 多模态融合:将图像特征和文本提示输入到MLLM中进行融合。4) 基于bin的分类:使用Transformer进行分类,将连续的回归值离散化到不同的bin中。5) 预测输出:根据分类结果,输出最终的回归值。
关键创新:论文的关键创新点在于:1) 提出了RvTC框架,采用基于bin的分类方法,避免了手动构建词汇表,提高了模型的灵活性。2) 强调了数据特定提示的重要性,证明了包含语义信息的提示可以显著提升MLLM的性能。3) 通过实验验证了RvTC框架在不同MLLM架构上的通用性。
关键设计:RvTC的关键设计包括:1) Bin的数量:通过增加bin的数量来提高回归精度,无需复杂的分布建模。2) 提示的设计:根据不同的数据集和任务,设计包含语义信息的提示,例如,在AVA数据集上,使用图像的挑战标题作为提示。3) 损失函数:使用交叉熵损失函数来训练分类器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RvTC框架在AVA和AGIQA-3k数据集上取得了SOTA性能。在AVA数据集上,添加挑战标题到提示中,显著提升了模型性能,超越了仅使用图像的基线模型。实验还验证了RvTC框架在不同MLLM架构上的通用性,表明该方法具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于图像质量评估、图像美学评分、医学图像诊断等领域。通过结合图像和文本信息,可以更准确地评估图像的质量和价值,为用户提供更好的体验。未来,该方法有望扩展到其他多模态回归任务中,例如视频质量评估、音频情感分析等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) show promise for image-based regression tasks, but current approaches face key limitations. Recent methods fine-tune MLLMs using preset output vocabularies and generic task-level prompts (e.g., "How would you rate this image?"), assuming this mimics human rating behavior. Our analysis reveals that these approaches provide no benefit over image-only training. Models using preset vocabularies and generic prompts perform equivalently to image-only models, failing to leverage semantic understanding from textual input. We propose Regression via Transformer-Based Classification (RvTC), which replaces vocabulary-constrained classification with a flexible bin-based approach. Unlike approaches that address discretization errors through complex distributional modeling, RvTC eliminates manual vocabulary crafting through straightforward bin increase, achieving state-of-the-art performance on four image assessment datasets using only images. More importantly, we demonstrate that data-specific prompts dramatically improve performance. Unlike generic task descriptions, prompts containing semantic information about specific images enable MLLMs to leverage cross-modal understanding. On the AVA dataset, adding challenge titles to prompts substantially improves our already state-of-the-art image-only baseline. We demonstrate through empirical evidence from the AVA and AGIQA-3k datasets that MLLMs benefit from semantic prompt information, surpassing mere statistical biases. We validate RvTC across two different MLLM architectures, demonstrating consistent improvements and method generalizability.