Semantic-Aware Representation Learning via Conditional Transport for Multi-Label Image Classification
作者: Ren-Dong Xie, Zhi-Fen He, Bo Li, Bin Liu, Jin-Yan Hu
分类: cs.CV
发布日期: 2025-07-20 (更新: 2025-11-02)
备注: The paper is under consideration at Pattern Recognition Letters
💡 一句话要点
提出SCT模型,通过条件传输的语义感知表示学习解决多标签图像分类问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多标签图像分类 语义感知表示学习 条件传输 视觉-语义对齐 特征学习 深度学习 图像分析
📋 核心要点
- 现有方法在多标签图像分类中难以学习判别性的语义感知特征,且视觉表示和标签嵌入之间缺乏细粒度对齐。
- SCT模型通过语义相关特征学习模块提取标签特定特征,并利用条件传输对齐机制实现精确的视觉-语义对齐。
- 在VOC2007和MS-COCO数据集上的实验表明,SCT模型优于现有方法,验证了其有效性。
📝 摘要(中文)
多标签图像分类是机器学习中的一项关键任务,旨在为单个图像准确分配多个标签。现有方法通常利用注意力机制或图卷积网络来建模视觉表示,但其性能仍受到两个关键限制的约束:无法学习判别性的语义感知特征,以及视觉表示和标签嵌入之间缺乏细粒度的对齐。为了在统一的框架中解决这些问题,本文提出了一种名为基于条件传输的语义感知表示学习(SCT)的新方法。该方法引入了一个语义相关特征学习模块,通过强调语义相关性和交互来提取判别性的标签特定特征,以及一个基于条件传输的对齐机制,从而实现精确的视觉-语义对齐。在两个广泛使用的基准数据集VOC2007和MS-COCO上的大量实验验证了SCT的有效性,并证明了其优于现有最先进方法的性能。
🔬 方法详解
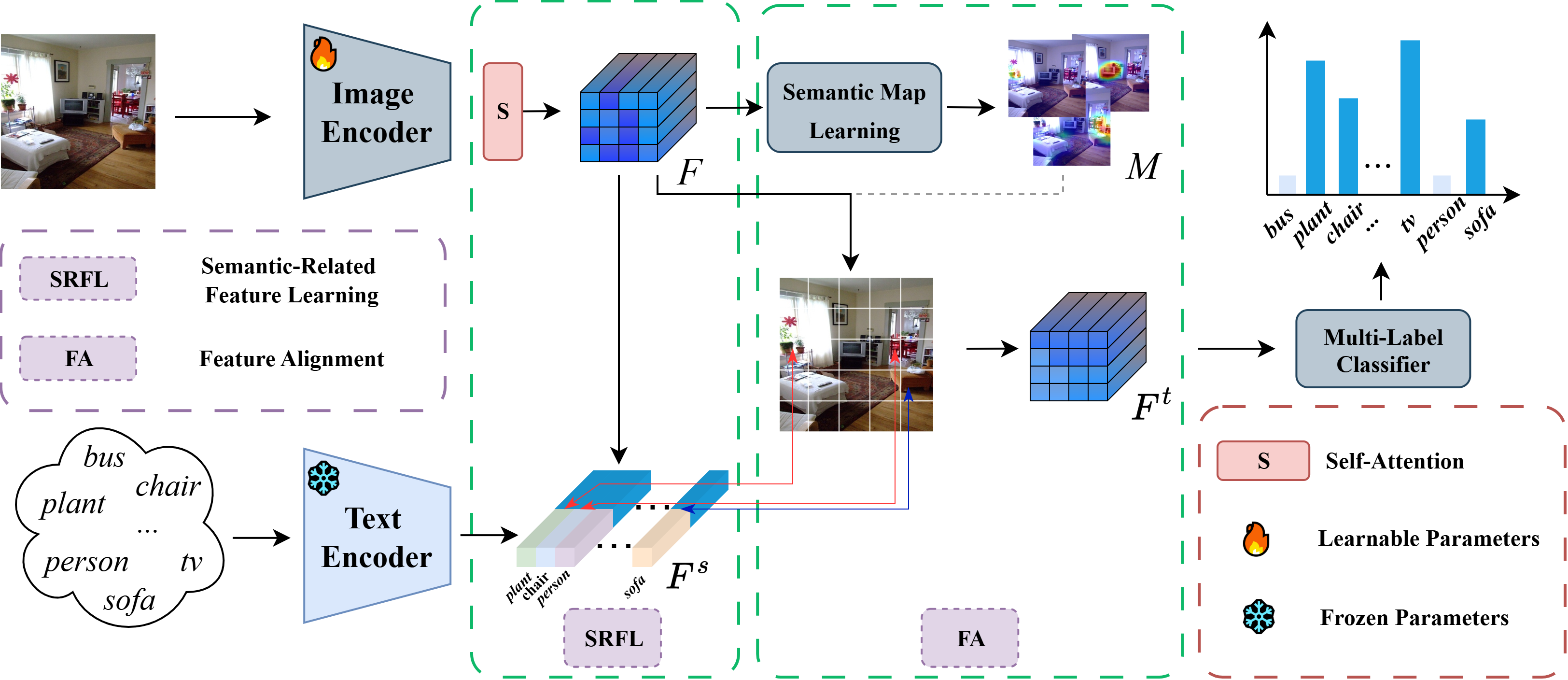
问题定义:多标签图像分类旨在为图像分配多个标签,现有方法如基于注意力机制或图卷积网络的方法,无法充分学习图像中判别性的语义感知特征,并且视觉表示与标签嵌入之间的对齐不够精细,导致分类性能受限。
核心思路:本文的核心思路是通过学习语义相关的特征表示,并进行视觉和语义的精细对齐来提升多标签图像分类的性能。具体来说,通过一个语义相关特征学习模块来提取标签特定的特征,并使用条件传输方法来实现视觉和语义表示的对齐。
技术框架:SCT模型的整体框架包含两个主要模块:语义相关特征学习模块和基于条件传输的对齐模块。首先,语义相关特征学习模块利用注意力机制或类似方法提取与每个标签相关的视觉特征。然后,基于条件传输的对齐模块将视觉特征和标签嵌入进行对齐,使得视觉特征能够更好地表达标签的语义信息。最后,利用对齐后的特征进行多标签分类。
关键创新:SCT模型的关键创新在于提出了一个统一的框架,同时解决了语义感知特征学习和视觉-语义对齐两个问题。语义相关特征学习模块能够提取判别性的标签特定特征,而条件传输对齐机制能够实现视觉和语义表示的精细对齐。这种联合优化方法能够显著提升多标签图像分类的性能。
关键设计:语义相关特征学习模块可能采用注意力机制,例如Transformer或图卷积网络,来学习标签相关的特征。条件传输对齐模块可能使用最优传输理论,通过最小化视觉特征和标签嵌入之间的传输代价来实现对齐。损失函数包括分类损失(例如,二元交叉熵损失)和对齐损失(例如,最优传输代价)。具体的网络结构和参数设置需要根据实际情况进行调整。
🖼️ 关键图片


📊 实验亮点
SCT模型在VOC2007和MS-COCO两个常用数据集上进行了广泛的实验验证。实验结果表明,SCT模型在两个数据集上均取得了优于现有最先进方法的性能。具体的性能提升幅度未知,但摘要中明确指出SCT模型表现出“superior performance compared to existing state-of-the-art methods”。
🎯 应用场景
该研究成果可应用于智能图像分析、图像搜索、目标检测等领域。例如,在图像搜索中,可以根据图像包含的多个标签进行更精确的搜索。在目标检测中,可以利用多标签分类的结果来辅助检测过程,提高检测的准确率。未来,该方法可以扩展到视频等多媒体数据的多标签分类任务中。
📄 摘要(原文)
Multi-label image classification is a critical task in machine learning that aims to accurately assign multiple labels to a single image. While existing methods often utilize attention mechanisms or graph convolutional networks to model visual representations, their performance is still constrained by two critical limitations: the inability to learn discriminative semantic-aware features, and the lack of fine-grained alignment between visual representations and label embeddings. To tackle these issues in a unified framework, this paper proposes a novel approach named Semantic-aware representation learning via Conditional Transport for Multi-Label Image Classification (SCT). The proposed method introduces a semantic-related feature learning module that extracts discriminative label-specific features by emphasizing semantic relevance and interaction, along with a conditional transport-based alignment mechanism that enables precise visual-semantic alignment. Extensive experiments on two widely-used benchmark datasets, VOC2007 and MS-COCO, validate the effectiveness of SCT and demonstrate its superior performance compared to existing state-of-the-art methods.