Light Future: Multimodal Action Frame Prediction via InstructPix2Pix
作者: Zesen Zhong, Duomin Zhang, Yijia Li
分类: cs.CV, cs.MM, cs.RO
发布日期: 2025-07-20 (更新: 2025-11-04)
备注: 9 pages including appendix, 4 tables, 8 figures, to be submitted to WACV 2026
💡 一句话要点
提出基于InstructPix2Pix的轻量级多模态动作帧预测方法,用于机器人任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人动作预测 未来帧预测 InstructPix2Pix 多模态学习 轻量级模型
📋 核心要点
- 现有视频预测模型计算成本高、推理延迟大,难以满足机器人等实时性要求高的场景。
- 利用InstructPix2Pix模型,结合单张图像和文本指令,预测未来帧,实现轻量级多模态动作预测。
- 在RoboTWin数据集上,该方法在SSIM和PSNR指标上优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖、高效且轻量级的机器人动作预测方法,与传统的视频预测模型相比,显著降低了计算成本和推理延迟。该方法率先将InstructPix2Pix模型应用于机器人任务中的未来视觉帧预测,扩展了其在静态图像编辑之外的用途。我们实现了一个基于深度学习的视觉预测框架,该框架在给定当前图像和文本指令的情况下,预测机器人未来100帧(10秒)的观测结果。我们重新利用并微调了InstructPix2Pix模型,使其能够接受视觉和文本输入,从而实现多模态未来帧预测。在基于真实场景生成的RoboTWin数据集上的实验表明,我们的方法在机器人动作预测任务中实现了优于最先进基线的SSIM和PSNR。与需要多个输入帧、大量计算和缓慢推理延迟的传统视频预测模型不同,我们的方法只需要单个图像和文本提示作为输入。这种轻量级设计能够实现更快的推理、降低GPU需求和灵活的多模态控制,这对于机器人和体育运动轨迹分析等应用尤其有价值,在这些应用中,运动轨迹精度优先于视觉逼真度。
🔬 方法详解
问题定义:论文旨在解决机器人动作预测问题,即在给定当前图像和文本指令的情况下,预测机器人未来一段时间内的视觉观测。现有视频预测模型通常需要多个输入帧,计算量大,推理速度慢,难以满足机器人等实时性要求高的应用场景。
核心思路:论文的核心思路是利用InstructPix2Pix模型,通过单张图像和文本指令作为输入,预测未来帧。InstructPix2Pix原本用于静态图像编辑,论文将其扩展到视频预测领域,并针对机器人动作预测任务进行了微调。这种方法避免了传统视频预测模型需要处理大量视频帧的复杂性,从而降低了计算成本和推理延迟。
技术框架:整体框架包含以下几个主要步骤:1) 输入当前图像和文本指令;2) 将图像和文本指令输入到微调后的InstructPix2Pix模型中;3) InstructPix2Pix模型生成未来帧的预测结果。该框架的核心是InstructPix2Pix模型,它负责将图像和文本信息融合,并生成未来帧的视觉表示。
关键创新:论文的关键创新在于将InstructPix2Pix模型应用于机器人动作预测任务,并成功地实现了轻量级多模态未来帧预测。与传统的视频预测模型相比,该方法只需要单张图像和文本指令作为输入,大大降低了计算复杂度。此外,该方法还能够灵活地接受文本指令,实现对未来动作的控制。
关键设计:论文对InstructPix2Pix模型进行了微调,使其能够更好地适应机器人动作预测任务。具体的微调策略和损失函数等技术细节在论文中没有详细描述,属于未知信息。论文强调了使用SSIM和PSNR作为评估指标,以衡量预测帧与真实帧之间的相似度。
🖼️ 关键图片
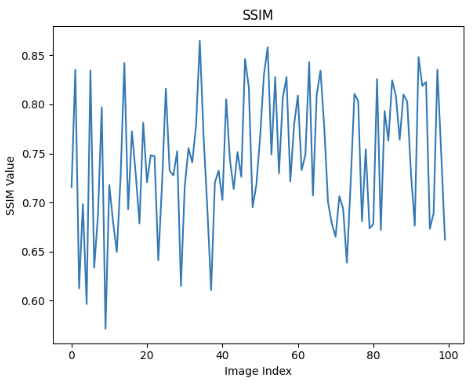
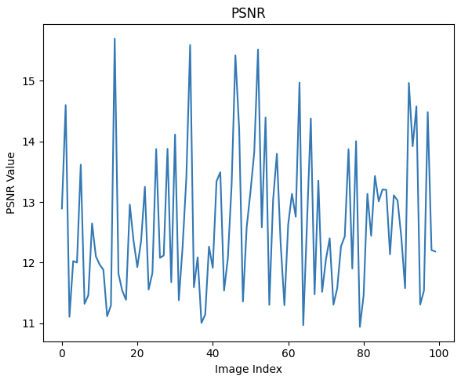

📊 实验亮点
实验结果表明,该方法在RoboTWin数据集上取得了优于现有方法的性能。具体而言,该方法在SSIM和PSNR指标上均优于最先进的基线方法,证明了其在机器人动作预测任务中的有效性。由于论文中没有给出具体的数值提升,因此无法量化提升幅度。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶系统和人体活动预测等领域。在机器人领域,可以帮助机器人更好地理解环境,预测自身行为的后果,从而做出更安全、更智能的决策。在自动驾驶领域,可以用于预测其他车辆或行人的行为,提高驾驶安全性。在人体活动预测领域,可以用于智能监控、运动分析等应用。
📄 摘要(原文)
Predicting future motion trajectories is a critical capability across domains such as robotics, autonomous systems, and human activity forecasting, enabling safer and more intelligent decision-making. This paper proposes a novel, efficient, and lightweight approach for robot action prediction, offering significantly reduced computational cost and inference latency compared to conventional video prediction models. Importantly, it pioneers the adaptation of the InstructPix2Pix model for forecasting future visual frames in robotic tasks, extending its utility beyond static image editing. We implement a deep learning-based visual prediction framework that forecasts what a robot will observe 100 frames (10 seconds) into the future, given a current image and a textual instruction. We repurpose and fine-tune the InstructPix2Pix model to accept both visual and textual inputs, enabling multimodal future frame prediction. Experiments on the RoboTWin dataset (generated based on real-world scenarios) demonstrate that our method achieves superior SSIM and PSNR compared to state-of-the-art baselines in robot action prediction tasks. Unlike conventional video prediction models that require multiple input frames, heavy computation, and slow inference latency, our approach only needs a single image and a text prompt as input. This lightweight design enables faster inference, reduced GPU demands, and flexible multimodal control, particularly valuable for applications like robotics and sports motion trajectory analytics, where motion trajectory precision is prioritized over visual fidelity.