Docopilot: Improving Multimodal Models for Document-Level Understanding
作者: Yuchen Duan, Zhe Chen, Yusong Hu, Weiyun Wang, Shenglong Ye, Botian Shi, Lewei Lu, Qibin Hou, Tong Lu, Hongsheng Li, Jifeng Dai, Wenhai Wang
分类: cs.CV, cs.CL
发布日期: 2025-07-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出Docopilot,一种用于文档级理解的多模态模型,并构建高质量数据集Doc-750K。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 文档理解 长文本建模 跨页依赖 数据集构建
📋 核心要点
- 现有MLLM在多页文档理解方面表现不足,主要原因是缺乏高质量的文档级数据集。
- Docopilot通过构建Doc-750K数据集,并开发原生多模态模型,无需RAG即可处理文档级依赖。
- 实验表明,Docopilot在文档理解任务中表现出更高的连贯性、准确性和效率,设立了新基准。
📝 摘要(中文)
尽管多模态大语言模型(MLLMs)取得了显著进展,但它们在复杂的多页文档理解方面的性能仍然不足,这主要是由于缺乏高质量的文档级数据集。现有的检索增强生成(RAG)方法提供了一些解决方案,但存在检索上下文碎片化、多阶段误差累积以及额外的检索时间成本等问题。本文提出了一个高质量的文档级数据集Doc-750K,旨在支持对多模态文档的深入理解。该数据集包含多样化的文档结构、广泛的跨页依赖关系以及源自原始文档的真实问答对。基于该数据集,我们开发了一种原生的多模态模型Docopilot,它可以准确地处理文档级依赖关系,而无需依赖RAG。实验表明,Docopilot在文档理解任务和多轮交互中实现了卓越的连贯性、准确性和效率,为文档级多模态理解设定了新的基准。数据、代码和模型已在https://github.com/OpenGVLab/Docopilot上发布。
🔬 方法详解
问题定义:现有方法在处理多页文档理解时,面临着缺乏高质量数据集的挑战。检索增强生成(RAG)方法虽然可以缓解部分问题,但存在检索上下文不完整、多阶段误差累积以及额外的计算开销等痛点。因此,需要一种能够原生处理文档级依赖关系,且无需依赖RAG的模型。
核心思路:Docopilot的核心思路是构建一个高质量的文档级数据集Doc-750K,并在此基础上训练一个能够直接处理文档级依赖关系的多模态模型。通过端到端的方式学习文档的整体结构和跨页信息,避免了RAG方法带来的问题。
技术框架:Docopilot的技术框架主要包括两个部分:一是Doc-750K数据集的构建,二是Docopilot模型的训练。Doc-750K数据集包含了多样化的文档结构、广泛的跨页依赖关系以及真实的问答对。Docopilot模型则是一个基于Transformer的多模态模型,能够同时处理文本和图像信息。
关键创新:Docopilot的关键创新在于它是一种原生的多模态模型,能够直接处理文档级依赖关系,而无需依赖RAG。这避免了RAG方法带来的检索上下文碎片化和多阶段误差累积等问题。此外,Doc-750K数据集的构建也为文档级多模态理解提供了高质量的训练数据。
关键设计:Docopilot模型的具体结构未知,但可以推测其采用了某种形式的注意力机制,以便能够捕捉文档中的长程依赖关系。损失函数的设计也至关重要,需要能够鼓励模型学习到文档的整体结构和跨页信息。数据集构建方面,如何保证数据的真实性和多样性也是关键的设计考虑。
🖼️ 关键图片
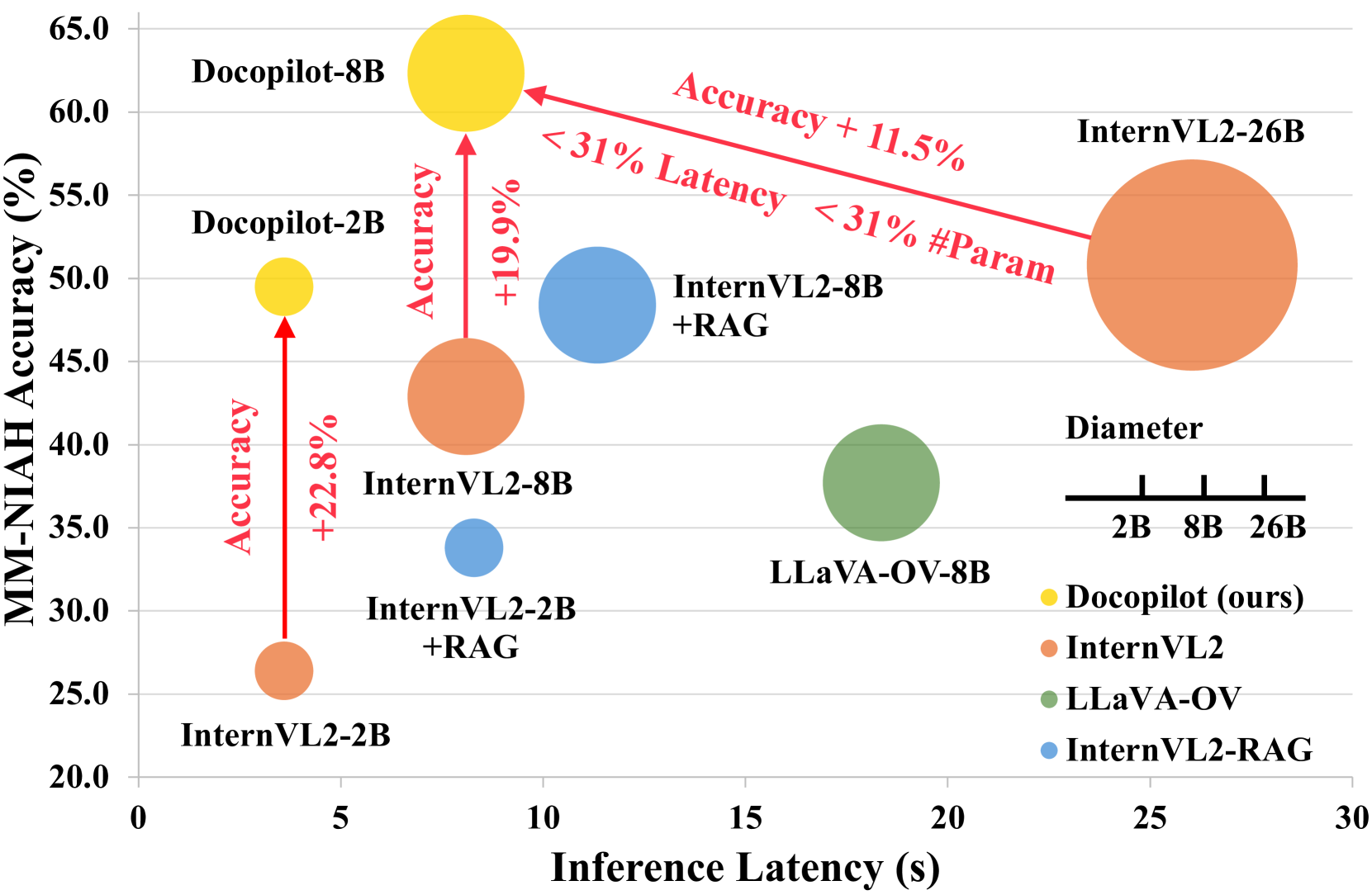


📊 实验亮点
Docopilot在文档理解任务和多轮交互中表现出卓越的性能,实现了更高的连贯性、准确性和效率。具体性能数据未知,但论文强调Docopilot为文档级多模态理解设定了新的基准,表明其性能显著优于现有方法。
🎯 应用场景
Docopilot在办公自动化、教育、金融等领域具有广泛的应用前景。例如,可以用于自动处理和理解合同、报告、教材等文档,提高工作效率和决策质量。未来,Docopilot有望成为智能文档处理的核心技术,推动相关产业的发展。
📄 摘要(原文)
Despite significant progress in multimodal large language models (MLLMs), their performance on complex, multi-page document comprehension remains inadequate, largely due to the lack of high-quality, document-level datasets. While current retrieval-augmented generation (RAG) methods offer partial solutions, they suffer from issues, such as fragmented retrieval contexts, multi-stage error accumulation, and extra time costs of retrieval. In this work, we present a high-quality document-level dataset, Doc-750K, designed to support in-depth understanding of multimodal documents. This dataset includes diverse document structures, extensive cross-page dependencies, and real question-answer pairs derived from the original documents. Building on the dataset, we develop a native multimodal model, Docopilot, which can accurately handle document-level dependencies without relying on RAG. Experiments demonstrate that Docopilot achieves superior coherence, accuracy, and efficiency in document understanding tasks and multi-turn interactions, setting a new baseline for document-level multimodal understanding. Data, code, and models are released at https://github.com/OpenGVLab/Docopilot