Multispectral State-Space Feature Fusion: Bridging Shared and Cross-Parametric Interactions for Object Detection
作者: Jifeng Shen, Haibo Zhan, Shaohua Dong, Xin Zuo, Wankou Yang, Haibin Ling
分类: cs.CV
发布日期: 2025-07-19 (更新: 2025-10-28)
备注: submitted on 30/4/2025, Accepted by Information Fusion
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于状态空间模型的多光谱特征融合框架MS2Fusion,提升目标检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多光谱融合 目标检测 状态空间模型 跨模态学习 特征融合
📋 核心要点
- 现有方法在多光谱融合时,过度关注局部互补特征,忽略了跨模态的共享语义,影响了泛化能力。
- MS2Fusion利用状态空间模型,设计双路径参数交互机制,兼顾跨模态互补信息和共享语义空间。
- 在多个数据集上,MS2Fusion在多光谱目标检测、语义分割和显著目标检测任务上均取得了SOTA结果。
📝 摘要(中文)
本文针对多光谱目标检测中过度依赖局部互补特征而忽略跨模态共享语义,以及感受野大小与计算复杂度之间的权衡问题,提出了一种新颖的多光谱状态空间特征融合框架MS2Fusion。该框架基于状态空间模型(SSM),通过双路径参数交互机制实现高效且有效的融合。其中,跨参数交互分支利用交叉注意力挖掘互补信息,并通过SSM中的跨模态隐藏状态解码。共享参数分支通过SSM中的参数共享,利用联合嵌入探索跨模态对齐,获得跨模态相似的语义特征和结构。最后,这两个路径通过SSM联合优化,在统一框架中融合多光谱特征。在FLIR、M3FD和LLVIP等主流基准测试中,MS2Fusion显著优于其他最先进的多光谱目标检测方法。此外,MS2Fusion具有通用性,即使没有专门设计,也能在RGB-T语义分割和RGBT显著目标检测上取得最先进的结果。
🔬 方法详解
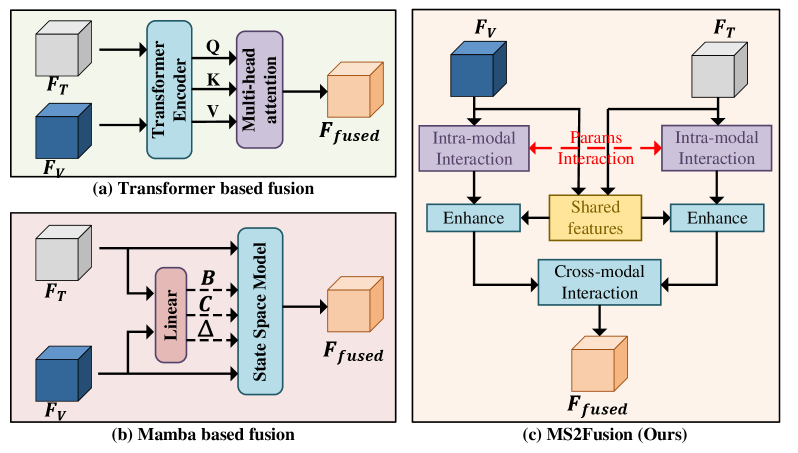
问题定义:多光谱目标检测旨在融合来自不同传感器的信息(如可见光和红外图像)以提高目标检测的准确性和鲁棒性。现有方法通常侧重于提取局部互补特征,但忽略了跨模态的共享语义信息,导致泛化能力不足。此外,感受野大小和计算复杂度之间的权衡也是一个挑战。
核心思路:MS2Fusion的核心思路是利用状态空间模型(SSM)来桥接跨模态的互补信息和共享语义。通过双路径参数交互机制,分别提取和融合这两种信息,从而实现更有效和鲁棒的多光谱特征融合。这种设计旨在克服现有方法对局部特征的过度依赖,并提高模型的泛化能力。
技术框架:MS2Fusion框架包含两个主要分支:跨参数交互分支和共享参数分支。跨参数交互分支利用交叉注意力机制挖掘跨模态的互补信息,并通过SSM中的跨模态隐藏状态解码进行融合。共享参数分支通过联合嵌入和SSM中的参数共享,探索跨模态的对齐,从而获得跨模态相似的语义特征和结构。这两个分支的输出最终通过SSM进行联合优化,实现多光谱特征的统一融合。
关键创新:MS2Fusion的关键创新在于其双路径参数交互机制,该机制能够同时提取和融合跨模态的互补信息和共享语义。与现有方法相比,MS2Fusion更加注重跨模态的语义对齐,从而提高了模型的泛化能力。此外,利用状态空间模型进行特征融合,能够在保证性能的同时,降低计算复杂度。
关键设计:MS2Fusion的关键设计包括:1) 跨参数交互分支中的交叉注意力机制,用于挖掘跨模态的互补信息;2) 共享参数分支中的联合嵌入和参数共享机制,用于探索跨模态的对齐;3) 基于状态空间模型的特征融合框架,用于联合优化两个分支的输出。具体的参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片


📊 实验亮点
MS2Fusion在FLIR、M3FD和LLVIP等主流多光谱目标检测数据集上取得了显著的性能提升,超越了现有的SOTA方法。此外,该方法在RGB-T语义分割和RGBT显著目标检测任务上也取得了有竞争力的结果,展示了其通用性。具体的性能数据和提升幅度需要在论文全文中查找。
🎯 应用场景
MS2Fusion可应用于自动驾驶、安防监控、搜救等领域。在这些场景中,多光谱信息能够提供更全面的环境感知,提高目标检测的准确性和鲁棒性。例如,在夜间或恶劣天气条件下,红外图像可以弥补可见光图像的不足,从而提高自动驾驶系统的安全性。该研究的未来影响在于推动多光谱感知技术的发展,并促进其在更多实际场景中的应用。
📄 摘要(原文)
Modern multispectral feature fusion for object detection faces two critical limitations: (1) Excessive preference for local complementary features over cross-modal shared semantics adversely affects generalization performance; and (2) The trade-off between the receptive field size and computational complexity present critical bottlenecks for scalable feature modeling. Addressing these issues, a novel Multispectral State-Space Feature Fusion framework, dubbed MS2Fusion, is proposed based on the state space model (SSM), achieving efficient and effective fusion through a dual-path parametric interaction mechanism. More specifically, the first cross-parameter interaction branch inherits the advantage of cross-attention in mining complementary information with cross-modal hidden state decoding in SSM. The second shared-parameter branch explores cross-modal alignment with joint embedding to obtain cross-modal similar semantic features and structures through parameter sharing in SSM. Finally, these two paths are jointly optimized with SSM for fusing multispectral features in a unified framework, allowing our MS2Fusion to enjoy both functional complementarity and shared semantic space. In our extensive experiments on mainstream benchmarks including FLIR, M3FD and LLVIP, our MS2Fusion significantly outperforms other state-of-the-art multispectral object detection methods, evidencing its superiority. Moreover, MS2Fusion is general and applicable to other multispectral perception tasks. We show that, even without specific design, MS2Fusion achieves state-of-the-art results on RGB-T semantic segmentation and RGBT salient object detection, showing its generality. The source code will be available at https://github.com/61s61min/MS2Fusion.git.