BusterX++: Towards Unified Cross-Modal AI-Generated Content Detection and Explanation with MLLM
作者: Haiquan Wen, Tianxiao Li, Zhenglin Huang, Yiwei He, Guangliang Cheng
分类: cs.CV
发布日期: 2025-07-19 (更新: 2026-01-06)
💡 一句话要点
BusterX++:提出基于MLLM的统一跨模态AI生成内容检测与解释框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态检测 AI生成内容 多模态大语言模型 强化学习 虚假信息检测
📋 核心要点
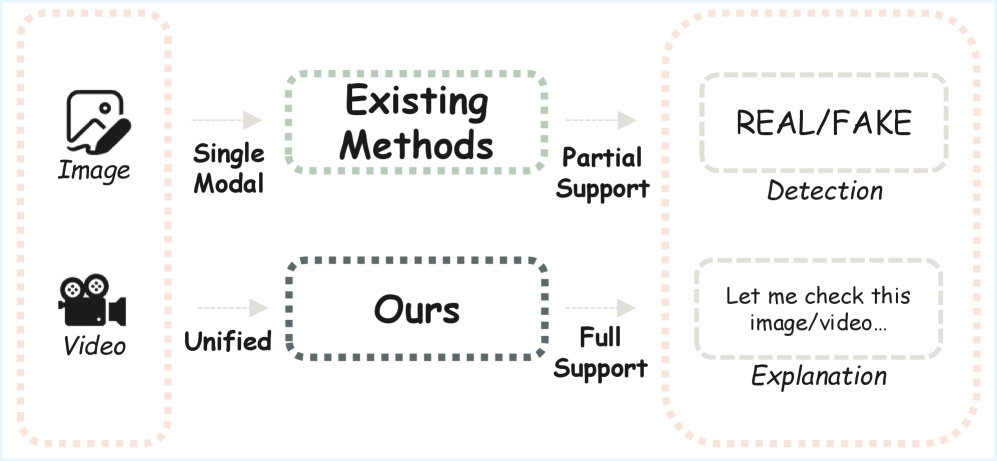
- 现有AI生成内容检测方法主要针对单一模态,无法有效应对混合模态的合成内容,检测能力受限。
- BusterX++框架通过多模态大型语言模型,统一检测和解释合成图像与视频,并采用强化学习进行后训练。
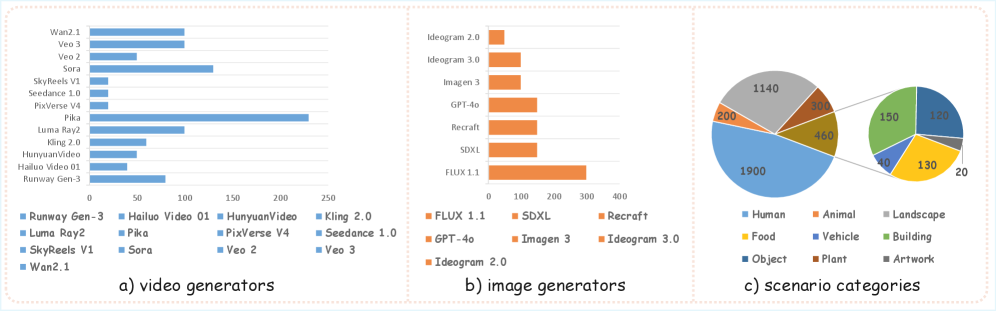
- GenBuster++基准包含4000个高质量、多样化的图像和视频片段,实验结果验证了BusterX++的有效性和泛化能力。
📝 摘要(中文)
生成式AI的最新进展显著提高了图像和视频的合成能力,但也增加了通过复杂伪造内容传播虚假信息的风险。为了应对这一挑战,检测方法已经从传统方法发展到多模态大型语言模型(MLLM),从而在识别合成媒体方面提供了更高的透明度和可解释性。然而,当前的检测系统在根本上受到其单模态设计的限制。这些方法分别分析图像或视频,使其在面对组合多种媒体格式的合成内容时无效。为了解决这些挑战,我们提出了 extbf{BusterX++},一个用于统一检测和解释合成图像和视频的框架,并采用直接强化学习(RL)后训练策略。为了实现全面的评估,我们还提出了 extbf{GenBuster++},一个利用最先进的图像和视频生成技术的统一基准。该基准包含4,000张图像和视频片段,由人工专家精心策划,以确保高质量、多样性和实际适用性。大量的实验证明了我们方法的有效性和泛化性。
🔬 方法详解
问题定义:当前AI生成内容检测方法主要集中于单一模态(图像或视频),缺乏对跨模态合成内容的有效检测能力。例如,将AI生成的图像嵌入到真实视频中,或者将AI生成的视频片段拼接成新的视频,这些情况现有方法难以准确识别。现有方法的痛点在于无法充分利用不同模态之间的关联信息,导致检测性能下降。
核心思路:BusterX++的核心思路是利用多模态大型语言模型(MLLM)的强大理解和推理能力,将图像和视频信息统一编码,并进行联合分析。通过MLLM,模型可以学习不同模态之间的关联性,从而更准确地判断内容是否为AI生成。此外,采用强化学习进行后训练,进一步提升模型的检测性能和解释能力。
技术框架:BusterX++框架主要包含以下几个模块:1) 多模态编码器:用于提取图像和视频的特征表示。2) 多模态大型语言模型(MLLM):将提取的特征输入MLLM,进行联合分析和推理。3) 检测头:基于MLLM的输出,判断内容是否为AI生成。4) 解释模块:生成对检测结果的解释,例如指出图像或视频中哪些区域或特征表明其为AI生成。5) 强化学习模块:使用强化学习对模型进行后训练,优化检测性能和解释能力。
关键创新:BusterX++最重要的技术创新点在于其统一的跨模态检测框架和强化学习后训练策略。与现有方法相比,BusterX++能够同时处理图像和视频,并利用它们之间的关联信息进行检测,从而提高了检测的准确性和鲁棒性。强化学习后训练策略进一步提升了模型的性能和可解释性。
关键设计:在多模态编码器方面,可以使用预训练的视觉模型(如CLIP)提取图像和视频帧的特征。MLLM可以选择现有的开源模型,如LLaVA或MiniGPT-4,并进行微调。强化学习模块可以使用策略梯度算法,奖励模型正确检测和生成合理的解释。损失函数可以包括交叉熵损失(用于检测)和语言模型损失(用于解释)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,BusterX++在GenBuster++基准上取得了显著的性能提升,相较于单模态检测方法,在跨模态合成内容检测方面具有更高的准确率和鲁棒性。强化学习后训练策略进一步提升了模型的检测性能和解释能力,为AI生成内容检测领域的研究提供了新的思路。
🎯 应用场景
BusterX++可应用于社交媒体平台、新闻媒体机构等,用于检测和识别AI生成的虚假信息,维护网络信息安全。该研究有助于提高公众对AI生成内容的辨别能力,减少虚假信息带来的负面影响,并为未来的AI内容监管提供技术支持。
📄 摘要(原文)
Recent advances in generative AI have dramatically improved image and video synthesis capabilities, significantly increasing the risk of misinformation through sophisticated fake content. In response, detection methods have evolved from traditional approaches to multimodal large language models (MLLMs), offering enhanced transparency and interpretability in identifying synthetic media. However, current detection systems remain fundamentally limited by their single-modality design. These approaches analyze images or videos separately, making them ineffective against synthetic content that combines multiple media formats. To address these challenges, we introduce \textbf{BusterX++}, a framework for unified detection and explanation of synthetic image and video, with a direct reinforcement learning (RL) post-training strategy. To enable comprehensive evaluation, we also present \textbf{GenBuster++}, a unified benchmark leveraging state-of-the-art image and video generation techniques. This benchmark comprises 4,000 images and video clips, meticulously curated by human experts to ensure high quality, diversity, and real-world applicability. Extensive experiments demonstrate the effectiveness and generalizability of our approach.