Descrip3D: Enhancing Large Language Model-based 3D Scene Understanding with Object-Level Text Descriptions
作者: Jintang Xue, Ganning Zhao, Jie-En Yao, Hong-En Chen, Yue Hu, Meida Chen, Suya You, C. -C. Jay Kuo
分类: cs.CV
发布日期: 2025-07-19 (更新: 2025-12-07)
🔗 代码/项目: GITHUB
💡 一句话要点
Descrip3D:利用对象级文本描述增强大语言模型对3D场景的理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 大语言模型 对象关系建模 文本描述 多模态融合
📋 核心要点
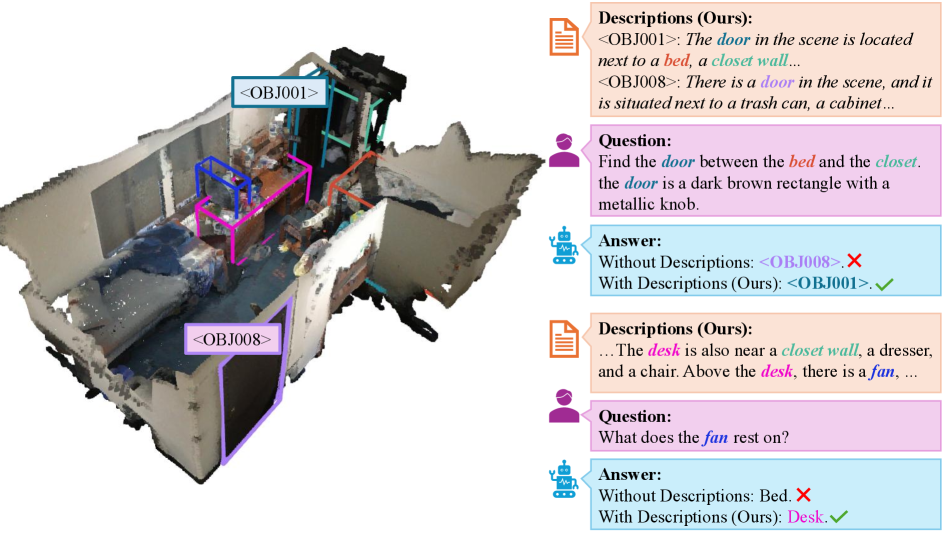
- 现有3D场景-语言模型在关系理解方面存在不足,尤其是在视觉嵌入不足以表达对象角色和交互时。
- Descrip3D通过为每个对象添加文本描述,捕捉其内在属性和上下文关系,显式编码对象间的关系。
- Descrip3D在多个基准数据集上超越了现有模型,验证了语言引导的关系表示在复杂室内场景理解中的有效性。
📝 摘要(中文)
本文提出Descrip3D,一种新颖且强大的框架,它使用自然语言显式地编码对象之间的关系,从而增强基于大语言模型的3D场景理解。与以往仅依赖2D和3D嵌入的方法不同,Descrip3D通过文本描述来增强每个对象,文本描述捕获了对象的内在属性和上下文关系。这些关系线索通过双层集成融入模型:嵌入融合和提示级别注入。这允许跨各种任务(如定位、图像描述和问答)进行统一推理,而无需特定于任务的头部或额外的监督。在五个基准数据集(包括ScanRefer、Multi3DRefer、ScanQA、SQA3D和Scan2Cap)上的评估表明,Descrip3D始终优于强大的基线模型,证明了语言引导的关系表示对于理解复杂室内场景的有效性。
🔬 方法详解
问题定义:现有3D场景理解模型难以有效捕捉对象之间的空间和语义关系,尤其是在视觉信息不足以充分表达对象间的交互时。仅仅依赖2D或3D嵌入无法提供足够的上下文信息,导致模型在诸如定位、问答等任务中表现不佳。
核心思路:Descrip3D的核心思路是利用自然语言来显式地描述对象及其关系。通过为每个对象生成文本描述,模型可以获得更丰富的上下文信息,从而更好地理解场景。这种方法将视觉信息与语言信息相结合,弥补了视觉嵌入的不足。
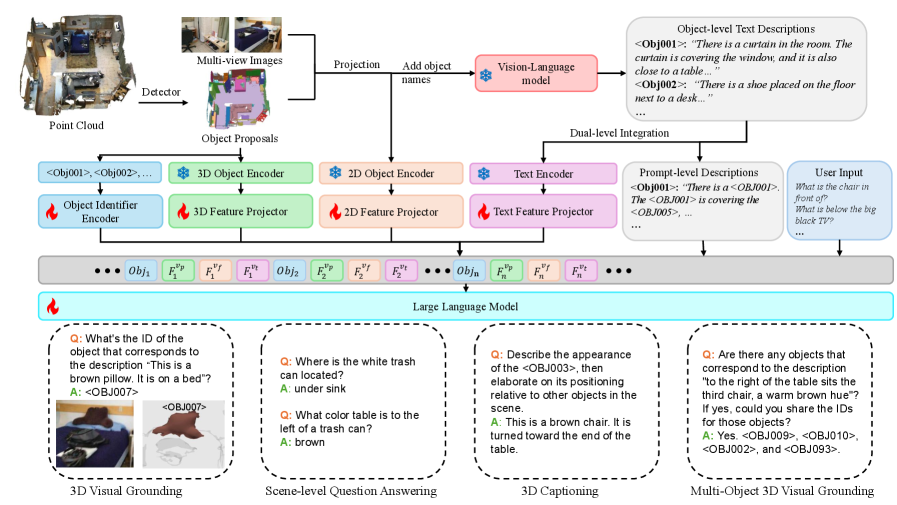
技术框架:Descrip3D框架包含以下主要模块:1) 对象检测与分割:从3D场景中检测和分割出各个对象。2) 文本描述生成:为每个对象生成文本描述,描述其属性和与其他对象的关系。3) 双层集成:将文本描述融入模型,包括嵌入融合(将文本嵌入与视觉嵌入融合)和提示级别注入(将文本描述作为提示输入模型)。4) 统一推理:使用融合后的信息进行各种任务,如定位、图像描述和问答。
关键创新:Descrip3D的关键创新在于使用对象级别的文本描述来增强3D场景理解。与以往仅依赖视觉嵌入的方法不同,Descrip3D显式地编码了对象之间的关系,从而提高了模型的推理能力。此外,双层集成策略有效地将文本信息融入模型,实现了跨任务的统一推理。
关键设计:文本描述生成模块的设计至关重要,需要考虑如何有效地捕捉对象的属性和关系。嵌入融合模块需要选择合适的融合策略,例如注意力机制或简单的拼接。提示级别注入模块需要设计合适的提示模板,以引导模型进行推理。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
Descrip3D在ScanRefer、Multi3DRefer、ScanQA、SQA3D和Scan2Cap等五个基准数据集上进行了评估,结果表明Descrip3D始终优于强大的基线模型。具体性能提升幅度未知,但实验结果证明了语言引导的关系表示对于理解复杂室内场景的有效性。
🎯 应用场景
Descrip3D技术可应用于机器人导航、智能家居、虚拟现实、增强现实等领域。例如,机器人可以利用该技术更好地理解周围环境,从而更安全、更有效地完成任务。在智能家居中,该技术可以帮助系统更好地理解用户的意图,提供更个性化的服务。在VR/AR领域,该技术可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
Understanding 3D scenes goes beyond simply recognizing objects; it requires reasoning about the spatial and semantic relationships between them. Current 3D scene-language models often struggle with this relational understanding, particularly when visual embeddings alone do not adequately convey the roles and interactions of objects. In this paper, we introduce Descrip3D, a novel and powerful framework that explicitly encodes the relationships between objects using natural language. Unlike previous methods that rely only on 2D and 3D embeddings, Descrip3D enhances each object with a textual description that captures both its intrinsic attributes and contextual relationships. These relational cues are incorporated into the model through a dual-level integration: embedding fusion and prompt-level injection. This allows for unified reasoning across various tasks such as grounding, captioning, and question answering, all without the need for task-specific heads or additional supervision. When evaluated on five benchmark datasets, including ScanRefer, Multi3DRefer, ScanQA, SQA3D, and Scan2Cap, Descrip3D consistently outperforms strong baseline models, demonstrating the effectiveness of language-guided relational representation for understanding complex indoor scenes. Our code and data are publicly available at https://github.com/jintangxue/Descrip3D.