Efficient Whole Slide Pathology VQA via Token Compression
作者: Weimin Lyu, Qingqiao Hu, Kehan Qi, Zhan Shi, Wentao Huang, Saumya Gupta, Chao Chen
分类: cs.CV, cs.CL
发布日期: 2025-07-19 (更新: 2025-10-02)
💡 一句话要点
提出TCP-LLaVA,通过token压缩实现高效的全切片病理图像VQA
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全切片图像 视觉问答 多模态学习 token压缩 病理诊断
📋 核心要点
- 现有MLLM方法在全切片病理图像VQA中,直接输入大量patch token导致计算资源消耗巨大。
- TCP-LLaVA通过引入可训练的压缩token,聚合视觉和文本信息,显著减少输入LLM的token数量。
- 实验表明,TCP-LLaVA在VQA准确率上优于现有基线,并显著降低了训练资源消耗。
📝 摘要(中文)
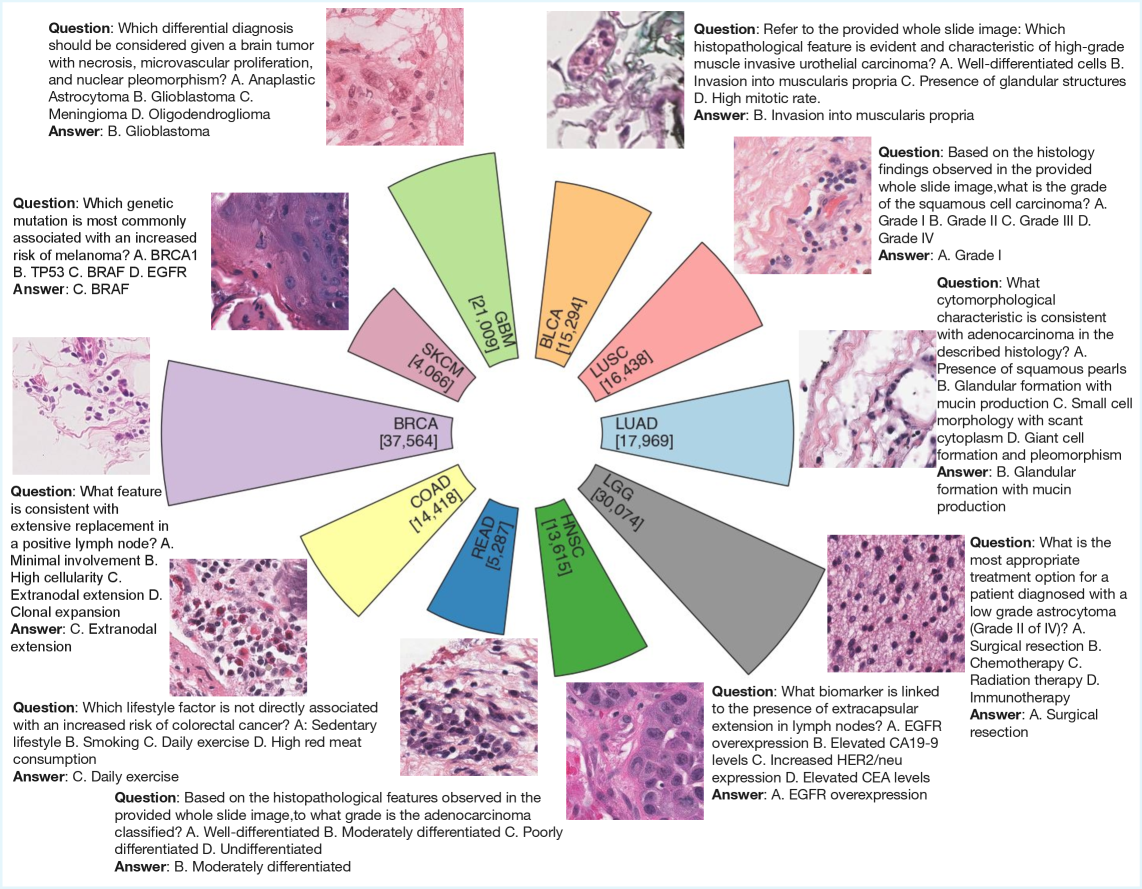
病理学中的全切片图像(WSI)可达10,000 x 10,000像素,对多模态大型语言模型(MLLM)提出了长上下文长度和高计算需求的挑战。以往方法侧重于使用基于CLIP的模型和多示例学习进行patch级别分析或slide级别分类,缺乏视觉问答(VQA)所需的生成能力。最近基于MLLM的方法通过将数千个patch token直接输入到语言模型中来解决VQA问题,导致过度的资源消耗。为了解决这些限制,我们提出了Token Compression Pathology LLaVA (TCP-LLaVA),这是第一个通过token压缩执行WSI VQA的MLLM架构。TCP-LLaVA引入了一组可训练的压缩token,通过受BERT中[CLS] token机制启发的模态压缩模块来聚合视觉和文本信息。只有压缩后的token被转发到LLM以生成答案,从而显著减少了输入长度和计算成本。在十种TCGA肿瘤亚型上的实验表明,TCP-LLaVA在VQA准确性方面优于现有的MLLM基线,同时大幅降低了训练资源消耗。
🔬 方法详解
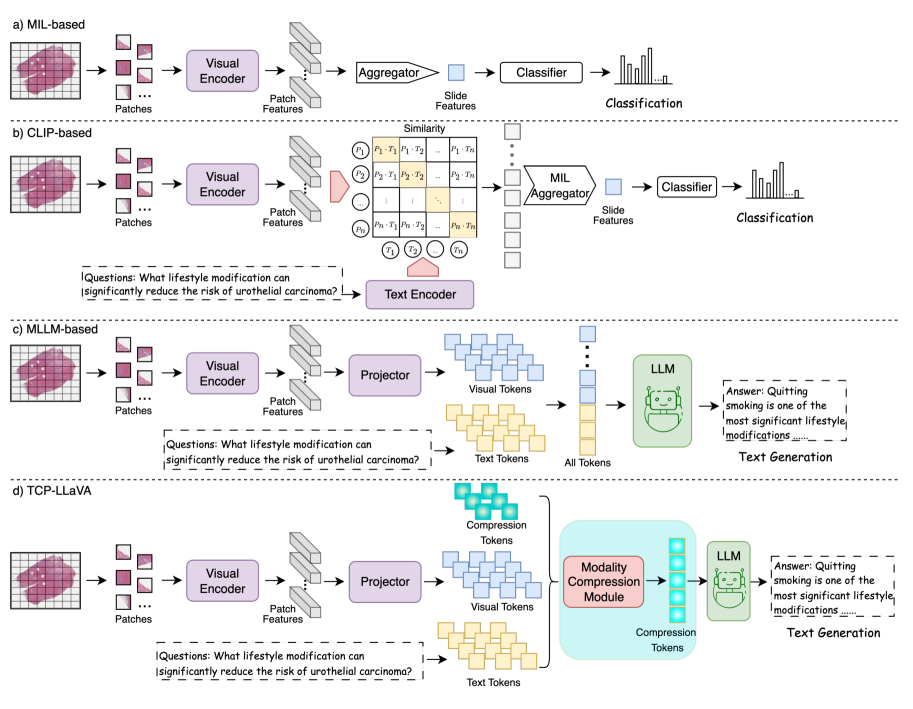
问题定义:论文旨在解决全切片病理图像(WSI)的视觉问答(VQA)问题。现有基于MLLM的方法,如直接将大量图像patch token输入LLM,导致计算资源消耗过大,难以实际应用。此外,一些方法侧重于图像分类,缺乏生成式VQA能力。
核心思路:论文的核心思路是通过token压缩来减少输入LLM的token数量,从而降低计算成本。借鉴BERT中[CLS] token的思想,引入一组可训练的压缩token,用于聚合视觉和文本信息。这样,LLM只需要处理少量压缩后的token,即可完成VQA任务。
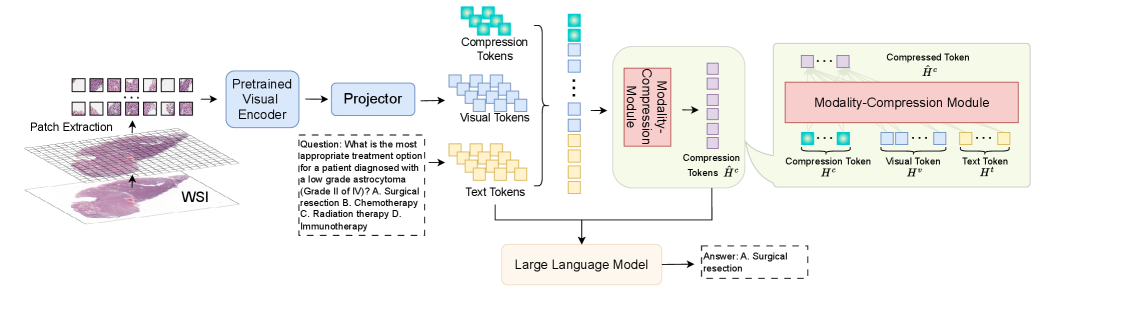
技术框架:TCP-LLaVA的整体架构包含以下几个主要模块:1) 图像编码器:用于提取WSI的视觉特征。2) 文本编码器:用于编码输入的问题。3) 模态压缩模块:将视觉和文本特征通过可训练的压缩token进行聚合。4) LLM:接收压缩后的token,生成答案。流程是:首先,图像和文本分别通过各自的编码器提取特征;然后,模态压缩模块将这些特征与压缩token融合;最后,LLM基于压缩后的token生成答案。
关键创新:论文最关键的创新点在于提出了基于可训练压缩token的模态压缩模块。与直接将大量patch token输入LLM的方法不同,TCP-LLaVA通过压缩token提取关键信息,显著减少了LLM的输入长度。这种方法在保证VQA准确率的同时,大幅降低了计算成本。
关键设计:模态压缩模块是TCP-LLaVA的关键。具体实现细节未知,但可以推测其可能采用Transformer结构,通过自注意力机制学习压缩token与其他token之间的关系。压缩token的数量是一个重要的超参数,需要根据具体任务进行调整。损失函数的设计也至关重要,需要保证压缩token能够有效地聚合视觉和文本信息,并最终生成准确的答案。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
TCP-LLaVA在十种TCGA肿瘤亚型上的实验表明,其VQA准确性优于现有的MLLM基线,同时大幅降低了训练资源消耗。具体的性能提升幅度未知,但摘要强调了资源消耗的显著降低,表明该方法在实际应用中具有重要价值。
🎯 应用场景
该研究成果可应用于病理诊断辅助系统,医生可以通过自然语言提问,系统基于全切片图像给出答案,辅助医生进行诊断决策。该技术有望提高病理诊断的效率和准确性,并降低对病理医生的依赖。未来,该技术还可以扩展到其他医学影像领域,如CT、MRI等。
📄 摘要(原文)
Whole-slide images (WSIs) in pathology can reach up to 10,000 x 10,000 pixels, posing significant challenges for multimodal large language model (MLLM) due to long context length and high computational demands. Previous methods typically focus on patch-level analysis or slide-level classification using CLIP-based models with multi-instance learning, but they lack the generative capabilities needed for visual question answering (VQA). More recent MLLM-based approaches address VQA by feeding thousands of patch tokens directly into the language model, which leads to excessive resource consumption. To address these limitations, we propose Token Compression Pathology LLaVA (TCP-LLaVA), the first MLLM architecture to perform WSI VQA via token compression. TCP-LLaVA introduces a set of trainable compression tokens that aggregate visual and textual information through a modality compression module, inspired by the [CLS] token mechanism in BERT. Only the compressed tokens are forwarded to the LLM for answer generation, significantly reducing input length and computational cost. Experiments on ten TCGA tumor subtypes show that TCP-LLaVA outperforms existing MLLM baselines in VQA accuracy while reducing training resource consumption by a substantial margin.