VLA-Mark: A cross modal watermark for large vision-language alignment model
作者: Shuliang Liu, Qi Zheng, Jesse Jiaxi Xu, Yibo Yan, Junyan Zhang, He Geng, Aiwei Liu, Peijie Jiang, Jia Liu, Yik-Cheung Tam, Xuming Hu
分类: cs.CV, cs.AI
发布日期: 2025-07-18 (更新: 2025-09-19)
备注: Accepted by the main conference, EMNLP 2025
💡 一句话要点
提出VLA-Mark,通过跨模态对齐的水印嵌入方法,保护视觉-语言模型的知识产权。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 水印技术 跨模态对齐 知识产权保护 语义一致性
📋 核心要点
- 现有文本水印方法破坏视觉-文本对齐,且易受攻击,无法有效保护视觉-语言模型的知识产权。
- VLA-Mark通过跨模态对齐,在不重新训练模型的前提下,嵌入可检测的水印,同时保持语义保真度。
- 实验结果表明,VLA-Mark在水印检测率、语义保持和抗攻击性方面均优于现有方法。
📝 摘要(中文)
视觉-语言模型需要水印解决方案,以保护知识产权,同时不影响多模态一致性。现有的文本水印方法通过有偏的token选择和静态策略,破坏了视觉-文本对齐,使语义关键概念易受攻击。我们提出了VLA-Mark,一个视觉对齐框架,它嵌入可检测的水印,同时通过跨模态协调保持语义保真度。我们的方法集成了多尺度视觉-文本对齐指标,结合局部patch亲和力、全局语义一致性和上下文注意力模式,以指导水印注入,无需模型重新训练。熵敏感机制动态平衡水印强度和语义保持,在低不确定性生成阶段优先考虑视觉基础。实验表明,PPL降低了7.4%,BLEU提高了26.6%,检测率接近完美(98.8% AUC)。该框架对释义和同义词替换等攻击表现出96.1%的攻击弹性,同时保持文本-视觉一致性,为高质量保持的多模态水印建立了新标准。
🔬 方法详解
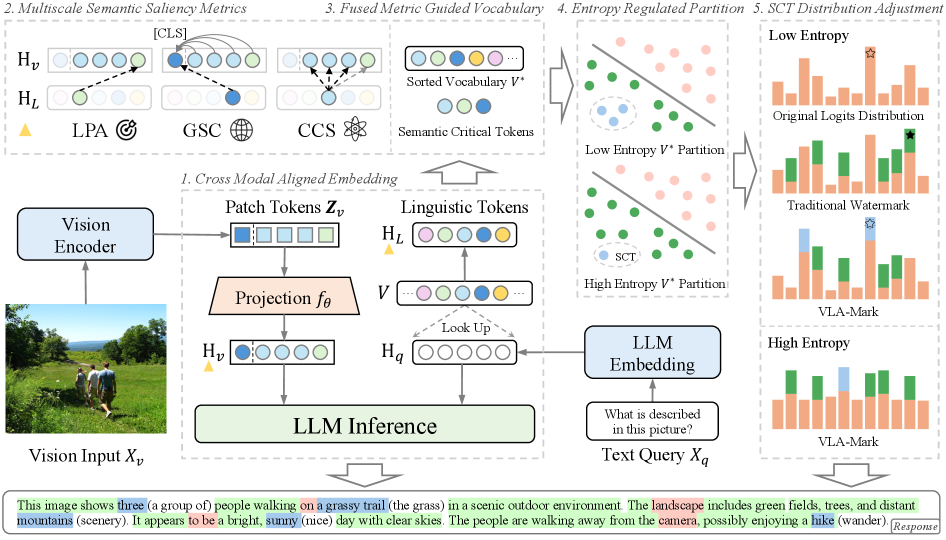
问题定义:现有的文本水印方法在应用于视觉-语言模型时,会破坏视觉和文本之间的对齐关系,导致生成的内容在语义上不一致。这些方法通常采用有偏的token选择策略和静态的水印强度,使得模型容易受到攻击,并且无法有效地保护模型的知识产权。因此,需要一种能够保持视觉-文本一致性,同时具有高检测率和抗攻击性的水印方法。
核心思路:VLA-Mark的核心思路是通过跨模态对齐来指导水印的嵌入过程,从而在保持语义保真度的同时,实现可检测的水印。该方法利用视觉和文本之间的关联性,通过多尺度视觉-文本对齐指标来确定水印的注入位置和强度,确保水印的嵌入不会破坏视觉和文本之间的语义一致性。
技术框架:VLA-Mark框架主要包含以下几个模块:1) 多尺度视觉-文本对齐模块:该模块用于计算局部patch亲和力、全局语义一致性和上下文注意力模式等指标,从而评估视觉和文本之间的对齐程度。2) 熵敏感水印注入模块:该模块根据生成过程中的不确定性(熵)动态调整水印的强度,在低不确定性阶段优先考虑视觉基础。3) 水印检测模块:该模块用于检测生成文本中是否包含预先嵌入的水印。整个框架无需模型重新训练,可以直接应用于现有的视觉-语言模型。
关键创新:VLA-Mark的关键创新在于其跨模态对齐的水印嵌入方法。与传统的文本水印方法不同,VLA-Mark充分利用了视觉和文本之间的关联性,通过多尺度视觉-文本对齐指标来指导水印的注入,从而在保持语义保真度的同时,实现高检测率和抗攻击性。此外,熵敏感机制能够动态调整水印强度,进一步提升了水印的鲁棒性。
关键设计:VLA-Mark的关键设计包括:1) 多尺度视觉-文本对齐指标的选取,包括局部patch亲和力、全局语义一致性和上下文注意力模式。2) 熵敏感机制的具体实现,例如如何计算生成过程中的不确定性,以及如何根据不确定性动态调整水印强度。3) 水印检测算法的设计,需要考虑如何在高噪声环境下准确检测水印的存在。
🖼️ 关键图片

📊 实验亮点
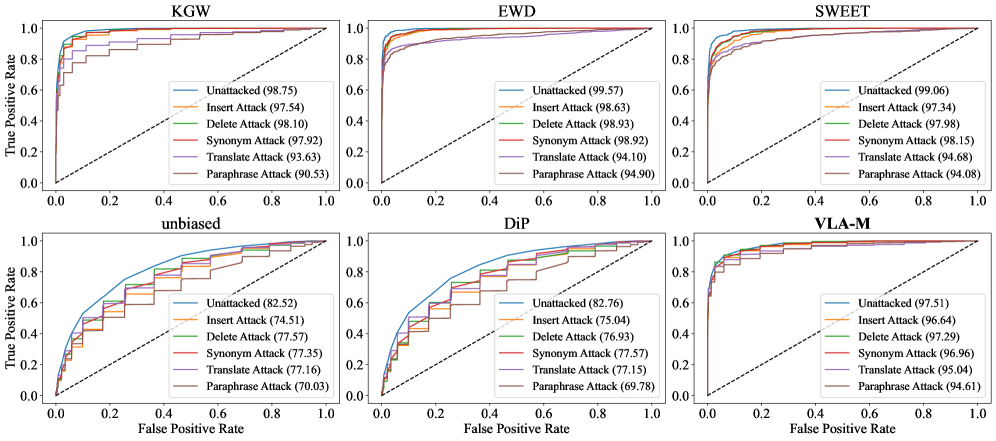
VLA-Mark在实验中表现出显著的优势。相较于传统方法,PPL降低了7.4%,BLEU提高了26.6%,表明其在保持语义一致性方面表现更佳。水印检测的AUC达到了98.8%,接近完美检测。此外,VLA-Mark对释义和同义词替换等攻击表现出96.1%的攻击弹性,证明了其强大的抗攻击能力。
🎯 应用场景
VLA-Mark可应用于各种视觉-语言模型的知识产权保护,例如图像描述生成、视觉问答、文本到图像生成等。通过嵌入水印,可以有效防止未经授权的模型复制和滥用,保护模型开发者的权益。该技术还有助于提高生成内容的安全性,例如防止恶意用户利用模型生成有害信息。
📄 摘要(原文)
Vision-language models demand watermarking solutions that protect intellectual property without compromising multimodal coherence. Existing text watermarking methods disrupt visual-textual alignment through biased token selection and static strategies, leaving semantic-critical concepts vulnerable. We propose VLA-Mark, a vision-aligned framework that embeds detectable watermarks while preserving semantic fidelity through cross-modal coordination. Our approach integrates multiscale visual-textual alignment metrics, combining localized patch affinity, global semantic coherence, and contextual attention patterns, to guide watermark injection without model retraining. An entropy-sensitive mechanism dynamically balances watermark strength and semantic preservation, prioritizing visual grounding during low-uncertainty generation phases. Experiments show 7.4% lower PPL and 26.6% higher BLEU than conventional methods, with near-perfect detection (98.8% AUC). The framework demonstrates 96.1\% attack resilience against attacks such as paraphrasing and synonym substitution, while maintaining text-visual consistency, establishing new standards for quality-preserving multimodal watermarking