Augmented Reality in Cultural Heritage: A Dual-Model Pipeline for 3D Artwork Reconstruction
作者: Daniele Pannone, Alessia Castronovo, Maurizio Mancini, Gian Luca Foresti, Claudio Piciarelli, Rossana Gabrieli, Muhammad Yasir Bilal, Danilo Avola
分类: cs.CV
发布日期: 2025-07-18
💡 一句话要点
提出双模型融合的增强现实管线,用于文化遗产领域3D艺术品重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 增强现实 文化遗产 3D重建 深度估计 双模型融合
📋 核心要点
- 现有方法难以从单张图像精确重建具有复杂特征的艺术品3D模型,尤其是在纹理和轮廓不规则的情况下。
- 该论文提出一种双模型管线,融合GLPN的全局结构感知和Depth-Anything的局部细节捕捉能力,优化深度估计。
- 实验结果表明,该方法显著提升了艺术品3D重建的精度和视觉真实感,增强了博物馆AR体验。
📝 摘要(中文)
本文提出了一种创新的增强现实管线,专为博物馆环境设计,旨在从单张图像中识别艺术品并生成精确的3D模型。该方法集成了两个互补的预训练深度估计模型:GLPN用于捕获全局场景结构,Depth-Anything用于详细的局部重建。通过这种方式,该方法生成了优化的深度图,能够有效地表示复杂的艺术特征。这些深度图随后被转换为高质量的点云和网格,从而能够创建沉浸式的AR体验。该方法利用了最先进的神经网络架构和先进的计算机视觉技术,以克服艺术品中不规则轮廓和可变纹理所带来的挑战。实验结果表明,重建精度和视觉真实感得到了显著提高,使得该系统成为博物馆通过交互式数字内容增强游客参与度的强大工具。
🔬 方法详解
问题定义:该论文旨在解决从单张艺术品图像中进行精确3D重建的问题。现有方法在处理艺术品时,由于其不规则的轮廓、多变的纹理以及复杂的几何结构,往往难以获得高质量的3D模型。这限制了增强现实技术在文化遗产领域的应用,例如博物馆展览中互动式体验的创建。
核心思路:该论文的核心思路是利用两个互补的深度估计模型,分别从全局和局部两个层面提取深度信息,然后将这些信息融合,从而获得更准确、更完整的深度图。这种双模型融合的方法旨在克服单一模型在处理复杂艺术品时的局限性。
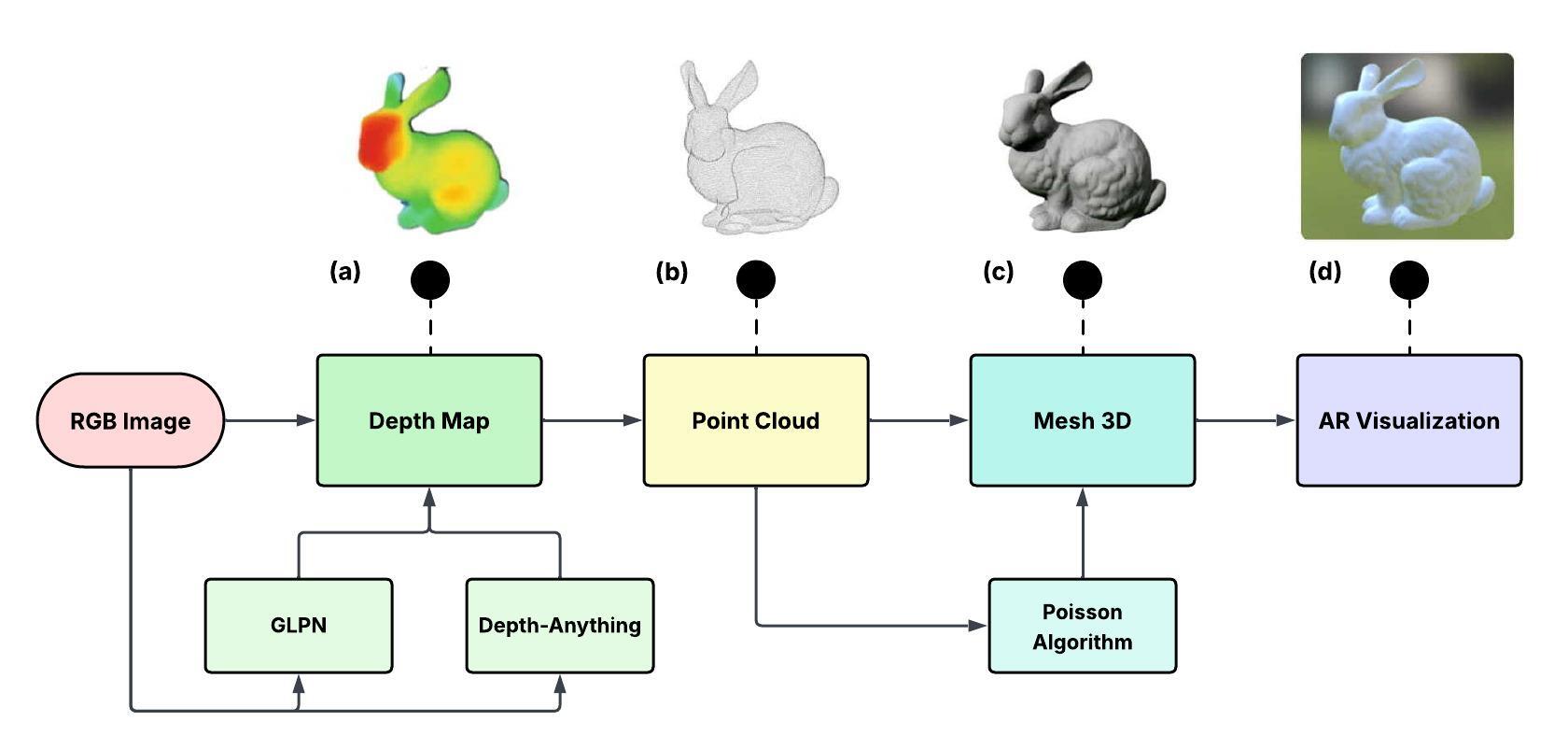
技术框架:该管线主要包含以下几个阶段:1) 图像输入:输入单张艺术品图像。2) 深度估计:使用GLPN模型估计全局深度信息,使用Depth-Anything模型估计局部深度信息。3) 深度图融合:将两个模型的深度图进行融合,生成优化的深度图。4) 点云生成:将深度图转换为点云。5) 网格重建:从点云重建3D网格模型。
关键创新:该论文的关键创新在于双模型融合的深度估计方法。通过结合GLPN的全局场景理解能力和Depth-Anything的局部细节捕捉能力,该方法能够更准确地估计艺术品的深度信息,从而提高3D重建的质量。与仅使用单一深度估计模型的方法相比,该方法能够更好地处理艺术品中复杂多变的特征。
关键设计:论文中没有明确说明具体的参数设置、损失函数或网络结构等技术细节,这些信息可能包含在GLPN和Depth-Anything的原始论文中。但整体框架的关键在于如何有效地融合两个模型的深度图,这部分的设计对最终的重建效果至关重要,但具体融合策略未知。
🖼️ 关键图片


📊 实验亮点
论文实验结果表明,该方法在艺术品3D重建的精度和视觉真实感方面取得了显著提升。虽然论文中没有提供具体的性能数据和对比基线,但强调了该方法能够更好地处理艺术品中复杂多变的特征,从而生成更高质量的3D模型,为博物馆提供更强大的AR工具。
🎯 应用场景
该研究成果可广泛应用于文化遗产领域,例如博物馆展览、虚拟旅游、艺术品修复和教育。通过增强现实技术,游客可以更深入地了解艺术品的细节和历史背景,从而提升参观体验。此外,该技术还可以用于创建艺术品的数字档案,方便研究人员进行分析和保护。
📄 摘要(原文)
This paper presents an innovative augmented reality pipeline tailored for museum environments, aimed at recognizing artworks and generating accurate 3D models from single images. By integrating two complementary pre-trained depth estimation models, i.e., GLPN for capturing global scene structure and Depth-Anything for detailed local reconstruction, the proposed approach produces optimized depth maps that effectively represent complex artistic features. These maps are then converted into high-quality point clouds and meshes, enabling the creation of immersive AR experiences. The methodology leverages state-of-the-art neural network architectures and advanced computer vision techniques to overcome challenges posed by irregular contours and variable textures in artworks. Experimental results demonstrate significant improvements in reconstruction accuracy and visual realism, making the system a highly robust tool for museums seeking to enhance visitor engagement through interactive digital content.