$π^3$: Permutation-Equivariant Visual Geometry Learning
作者: Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, Tong He
分类: cs.CV
发布日期: 2025-07-17 (更新: 2025-09-09)
备注: Project page: https://yyfz.github.io/pi3/
💡 一句话要点
提出$π^3$置换等变网络,用于无参考视角的视觉几何重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉几何重建 置换等变网络 相机姿态估计 深度估计 点云重建
📋 核心要点
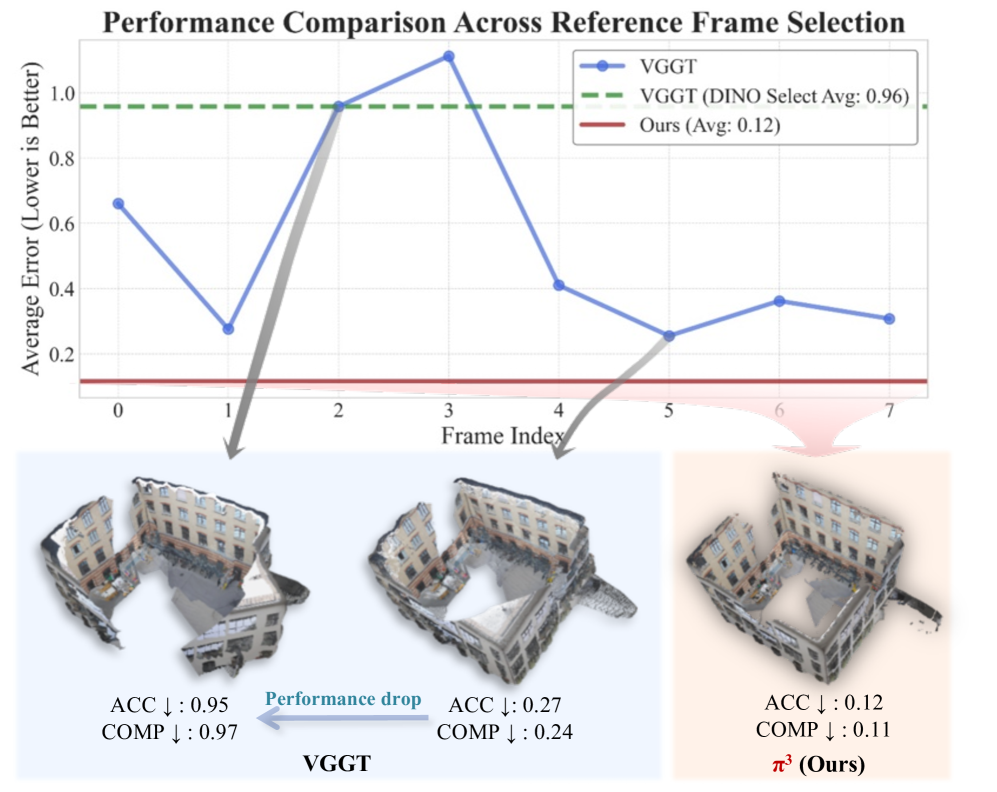
- 传统视觉几何重建方法依赖固定参考视角,当参考视角不佳时,会导致重建不稳定甚至失败。
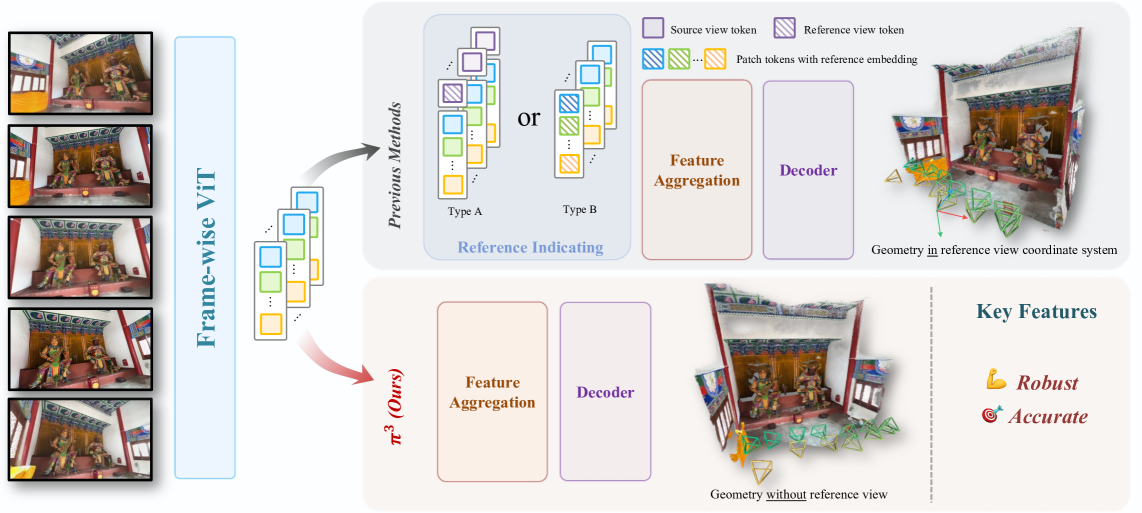
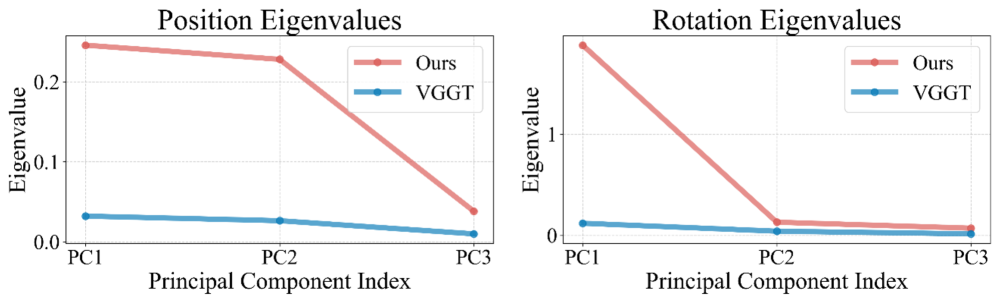
- $π^3$采用完全置换等变架构,无需参考帧即可预测仿射不变的相机姿态和尺度不变的局部点云图。
- 该方法在相机姿态估计、单目/视频深度估计和密集点云图重建等任务上取得了最先进的性能。
📝 摘要(中文)
本文提出了一种名为$π^3$的前馈神经网络,它为视觉几何重建提供了一种新颖的方法,打破了对传统固定参考视角的依赖。以往的方法通常将它们的重建锚定到一个指定的视点,这种归纳偏置可能导致不稳定和失败,如果参考视点不是最优的。相比之下,$π^3$采用完全置换等变的架构来预测仿射不变的相机姿态和尺度不变的局部点云图,而无需任何参考帧。这种设计不仅使我们的模型本质上对输入顺序具有鲁棒性,而且还提高了精度和性能。这些优势使我们简单且无偏的方法能够在各种任务上实现最先进的性能,包括相机姿态估计、单目/视频深度估计和密集点云图重建。代码和模型已公开。
🔬 方法详解
问题定义:现有视觉几何重建方法通常依赖于一个固定的参考视角,这引入了一个固有的偏置。当参考视角选择不当(例如,遮挡严重、质量差)时,重建结果的准确性和鲁棒性会受到显著影响。因此,如何消除对固定参考视角的依赖,实现更稳定、更准确的视觉几何重建是一个关键问题。
核心思路:$π^3$的核心思路是利用置换等变性来消除参考视角的依赖。通过设计一个对输入图像顺序不敏感的网络结构,模型能够从多个视角中提取共有的几何信息,从而实现无参考视角的重建。这种方法避免了因选择不佳的参考视角而导致的误差累积和不稳定性。
技术框架:$π^3$的整体框架是一个前馈神经网络,它接收一组图像作为输入,并输出仿射不变的相机姿态和尺度不变的局部点云图。该框架主要包含以下模块:特征提取模块(用于提取每张图像的局部特征)、置换等变聚合模块(用于聚合来自不同视角的特征,保证输出对输入顺序的不变性)和姿态/点云预测模块(用于预测相机姿态和局部点云)。
关键创新:$π^3$最重要的创新在于其完全置换等变的架构设计。传统的神经网络通常对输入顺序敏感,而$π^3$通过精心设计的网络结构,保证了输出结果与输入图像的顺序无关。这种设计使得模型能够从多个视角中提取一致的几何信息,从而实现无参考视角的重建。与现有方法相比,$π^3$避免了对特定参考视角的依赖,从而提高了重建的鲁棒性和准确性。
关键设计:$π^3$的关键设计包括:1) 使用深度卷积神经网络提取图像特征;2) 采用置换等变层(例如,基于集合操作的聚合层)来聚合特征,保证输出对输入顺序的不变性;3) 设计合适的损失函数,例如,基于几何一致性的损失函数,来约束相机姿态和点云的预测结果。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
$π^3$在相机姿态估计、单目/视频深度估计和密集点云图重建等多个任务上取得了最先进的性能。与现有方法相比,$π^3$在鲁棒性和准确性方面均有显著提升。具体性能数据需要在论文中查找。
🎯 应用场景
$π^3$在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以用于构建更鲁棒、更准确的三维地图,从而提高机器人的环境感知能力和导航精度。此外,该方法还可以应用于单目/视频深度估计,为虚拟现实和增强现实应用提供更逼真的三维场景。
📄 摘要(原文)
We introduce $π^3$, a feed-forward neural network that offers a novel approach to visual geometry reconstruction, breaking the reliance on a conventional fixed reference view. Previous methods often anchor their reconstructions to a designated viewpoint, an inductive bias that can lead to instability and failures if the reference is suboptimal. In contrast, $π^3$ employs a fully permutation-equivariant architecture to predict affine-invariant camera poses and scale-invariant local point maps without any reference frames. This design not only makes our model inherently robust to input ordering, but also leads to higher accuracy and performance. These advantages enable our simple and bias-free approach to achieve state-of-the-art performance on a wide range of tasks, including camera pose estimation, monocular/video depth estimation, and dense point map reconstruction. Code and models are publicly available.