VITA: Vision-to-Action Flow Matching Policy
作者: Dechen Gao, Boqi Zhao, Andrew Lee, Ian Chuang, Hanchu Zhou, Hang Wang, Zhe Zhao, Junshan Zhang, Iman Soltani
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-07-17 (更新: 2025-12-01)
备注: Project page: https://ucd-dare.github.io/VITA/ Code: https://github.com/ucd-dare/VITA
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VITA:一种无噪声、无条件反射的视觉到动作流匹配策略,加速机器人控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 流匹配 视觉到动作 策略学习 动作自编码器
📋 核心要点
- 传统流匹配策略依赖迭代去噪和视觉条件反射,计算开销大,限制了其在机器人控制中的应用。
- VITA直接从视觉表征生成动作,无需视觉条件反射,并通过动作自编码器对齐视觉和动作的潜在空间。
- 实验表明,VITA在多个机器人任务中实现了更快的推理速度,并取得了与现有最佳方法相当或更优的性能。
📝 摘要(中文)
本文提出VITA(VIsion-To-Action policy),一种无噪声且无条件反射的流匹配策略学习框架,直接从视觉表征流向潜在动作。由于流的源头是视觉信息,VITA无需在生成过程中进行视觉条件反射,从而降低了复杂性。为了解决视觉和动作之间的差异,VITA引入了一个动作自编码器,将原始动作映射到与视觉潜在空间对齐的结构化潜在空间,并与流匹配联合训练。为了防止潜在空间崩溃,提出了流潜在解码,通过在流匹配ODE(常微分方程)求解步骤中反向传播动作重构损失来锚定潜在生成过程。在ALOHA和Robomimic的9个模拟和5个真实世界任务中评估了VITA。结果表明,与具有条件反射模块的传统方法相比,VITA实现了1.5倍-2倍的更快推理速度,同时优于或匹配了最先进的策略。
🔬 方法详解
问题定义:现有基于流匹配和扩散模型的策略,在生成动作时需要从标准噪声分布迭代去噪,并且需要条件模块重复地整合视觉信息,导致时间和内存开销巨大。尤其是在机器人控制等实时性要求高的场景下,这种开销会严重影响策略的部署和应用。
核心思路:VITA的核心思路是直接建立从视觉表征到动作的映射,避免了从噪声到动作的生成过程。通过将视觉信息作为流的起点,消除了在生成过程中进行视觉条件反射的需要,从而降低了计算复杂度。为了解决视觉和动作之间的差异,VITA引入了动作自编码器,将动作映射到与视觉潜在空间对齐的结构化潜在空间。
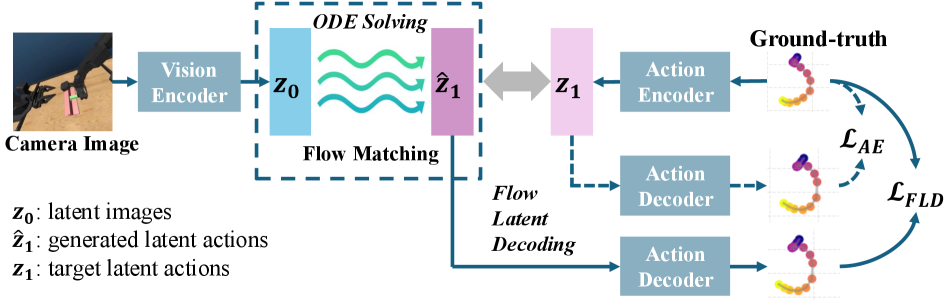
技术框架:VITA的整体框架包括以下几个主要模块:1) 视觉编码器:将原始视觉输入编码成视觉潜在表征。2) 动作自编码器:将原始动作编码成动作潜在表征,并进行重构。3) 流匹配模块:学习从视觉潜在表征到动作潜在表征的映射关系。4) 流潜在解码:通过反向传播动作重构损失来约束潜在空间的学习。整个流程通过联合训练的方式进行优化。
关键创新:VITA的关键创新在于:1) 提出了一种无噪声、无条件反射的流匹配策略,直接从视觉表征生成动作,避免了迭代去噪和视觉条件反射。2) 引入了动作自编码器,将动作映射到与视觉潜在空间对齐的结构化潜在空间,解决了视觉和动作之间的差异。3) 提出了流潜在解码,通过反向传播动作重构损失来约束潜在空间的学习,防止潜在空间崩溃。与现有方法相比,VITA在推理速度和计算复杂度上具有显著优势。
关键设计:动作自编码器的设计至关重要,它需要能够有效地将原始动作映射到与视觉潜在空间对齐的结构化潜在空间。流匹配模块采用ODE求解器进行训练和推理。流潜在解码通过在ODE求解的每一步反向传播动作重构损失来实现。损失函数包括流匹配损失、动作重构损失和潜在空间正则化损失。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
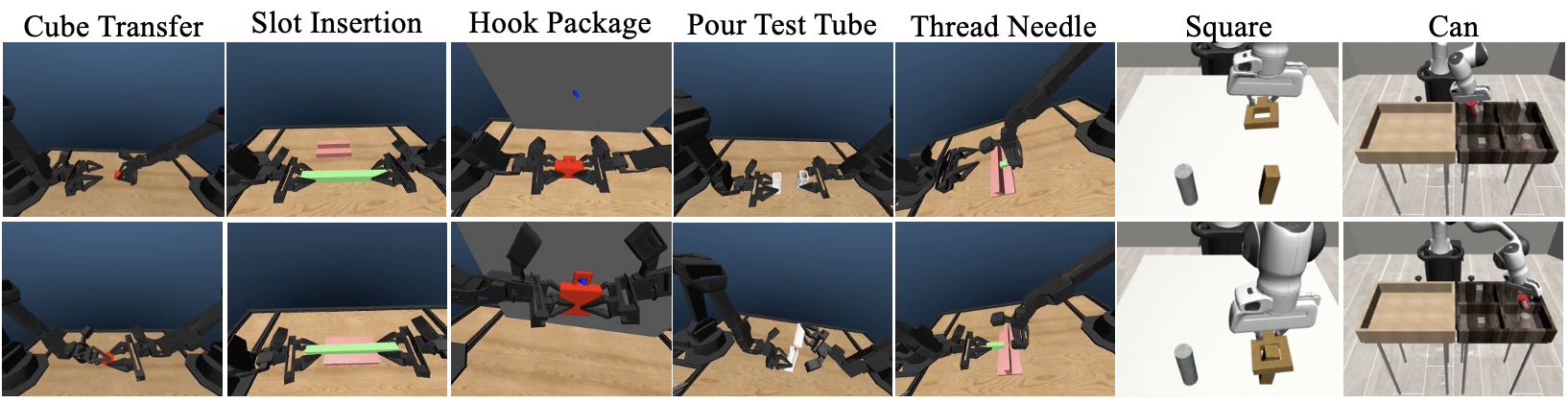
VITA在9个模拟和5个真实世界机器人任务中进行了评估,结果表明,与具有条件反射模块的传统方法相比,VITA实现了1.5倍-2倍的更快推理速度,同时优于或匹配了最先进的策略。例如,在ALOHA和Robomimic数据集上,VITA在多个任务中取得了state-of-the-art的性能。
🎯 应用场景
VITA具有广泛的应用前景,可以应用于各种机器人控制任务,例如机械臂操作、无人驾驶、智能导航等。由于其高效的推理速度和较低的计算复杂度,VITA特别适用于对实时性要求较高的场景。此外,VITA还可以应用于其他需要从高维感知信息生成低维控制信号的领域。
📄 摘要(原文)
Conventional flow matching and diffusion-based policies sample through iterative denoising from standard noise distributions (e.g., Gaussian), and require conditioning modules to repeatedly incorporate visual information during the generative process, incurring substantial time and memory overhead. To reduce the complexity, we develop VITA(VIsion-To-Action policy), a noise-free and conditioning-free flow matching policy learning framework that directly flows from visual representations to latent actions. Since the source of the flow is visually grounded, VITA eliminates the need of visual conditioning during generation. As expected, bridging vision and action is challenging, because actions are lower-dimensional, less structured, and sparser than visual representations; moreover, flow matching requires the source and target to have the same dimensionality. To overcome this, we introduce an action autoencoder that maps raw actions into a structured latent space aligned with visual latents, trained jointly with flow matching. To further prevent latent space collapse, we propose flow latent decoding, which anchors the latent generation process by backpropagating the action reconstruction loss through the flow matching ODE (ordinary differential equation) solving steps. We evaluate VITA on 9 simulation and 5 real-world tasks from ALOHA and Robomimic. VITA achieves 1.5x-2x faster inference compared to conventional methods with conditioning modules, while outperforming or matching state-of-the-art policies. Codes, datasets, and demos are available at our project page: https://ucd-dare.github.io/VITA/.