Orbis: Overcoming Challenges of Long-Horizon Prediction in Driving World Models
作者: Arian Mousakhan, Sudhanshu Mittal, Silvio Galesso, Karim Farid, Thomas Brox
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-17 (更新: 2025-12-11)
备注: Project page: https://lmb-freiburg.github.io/orbis.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Orbis:提出一种长时域预测的驾驶世界模型,在复杂场景下表现出色。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 自动驾驶 长时域预测 自回归模型 视频预测
📋 核心要点
- 现有自动驾驶世界模型难以进行长时域预测,并且在复杂场景下的泛化能力不足。
- Orbis模型采用简洁的设计,无需额外传感器或监督,专注于提升长时域预测的准确性和鲁棒性。
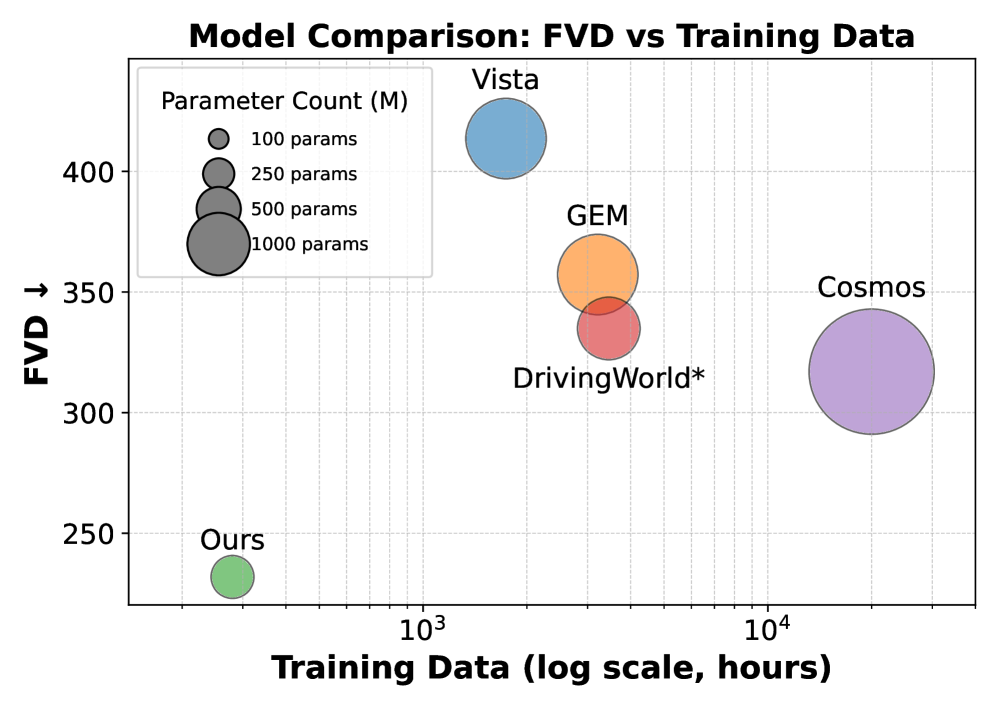
- 实验表明,Orbis模型在参数量和训练数据量有限的情况下,在复杂驾驶场景中取得了优异的性能。
📝 摘要(中文)
现有的自动驾驶世界模型在长时域生成和复杂场景泛化方面面临挑战。本文提出一种模型,该模型采用简单的设计选择,且无需额外的监督或传感器,如地图、深度或多摄像头。实验表明,该模型仅使用4.69亿参数并在280小时的视频数据上训练,即可实现最先进的性能,尤其是在转弯操作和城市交通等困难场景中表现突出。此外,本文还研究了离散token模型是否可能优于基于流匹配的连续模型,并建立了一个混合tokenizer,以支持两种方法并进行并排比较。研究结果表明,连续自回归模型在设计选择上更具鲁棒性,并且比基于离散token的模型更强大。代码、模型和定性结果已公开。
🔬 方法详解
问题定义:现有自动驾驶世界模型在长时域预测方面存在困难,难以准确预测车辆在较长时间范围内的行为。此外,这些模型在面对复杂和具有挑战性的驾驶场景(如城市交通和转弯操作)时,泛化能力较差,预测结果不稳定。现有方法通常依赖于额外的传感器数据(如地图、深度信息)或复杂的模型结构,增加了成本和复杂性。
核心思路:Orbis模型的核心思路是采用一个简洁而高效的设计,专注于利用视频数据进行自监督学习,从而实现长时域预测。通过优化模型结构和训练策略,提高模型在复杂场景下的泛化能力。同时,探索连续自回归模型和离散token模型在世界模型中的应用,并进行对比分析。
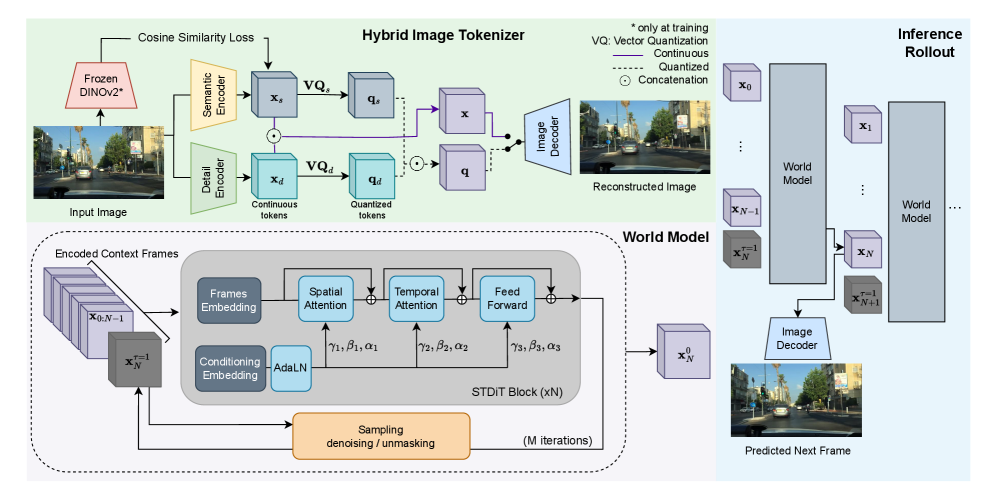
技术框架:Orbis模型采用一个自回归的框架,通过编码器将输入的视频帧序列编码成潜在表示,然后使用解码器基于这些潜在表示生成未来的视频帧序列。该框架包含以下主要模块:1) 视频编码器:将输入的视频帧编码成潜在向量。2) 自回归解码器:基于过去的潜在向量预测未来的潜在向量。3) 视频解码器:将预测的潜在向量解码成未来的视频帧。
关键创新:Orbis模型的关键创新在于其简洁的设计和对连续自回归模型的有效利用。与依赖复杂结构或额外传感器的模型不同,Orbis模型仅使用RGB视频数据进行训练,并通过优化模型结构和训练策略,实现了最先进的性能。此外,对连续模型和离散模型进行了深入的对比研究,为未来世界模型的设计提供了有价值的参考。
关键设计:Orbis模型采用了一个相对较小的模型规模(4.69亿参数),以提高训练效率和泛化能力。在训练过程中,使用了标准的自回归损失函数,并采用了一些正则化技术来防止过拟合。此外,对编码器和解码器的网络结构进行了优化,以提高模型的表达能力。在连续模型和离散模型的对比实验中,使用了相同的混合tokenizer,以确保公平的比较。
🖼️ 关键图片

📊 实验亮点
Orbis模型在长时域预测任务中取得了最先进的性能,尤其是在转弯操作和城市交通等复杂场景中表现突出。尽管模型参数量较小(4.69亿)且仅使用280小时的视频数据进行训练,但其性能优于其他需要更多数据或更复杂设计的模型。此外,对比实验表明,连续自回归模型在世界模型中具有更强的鲁棒性和表达能力。
🎯 应用场景
Orbis模型可应用于自动驾驶系统的感知和规划模块,提高自动驾驶车辆在复杂环境下的决策能力和安全性。该模型还可以用于驾驶模拟器,生成逼真的驾驶场景,用于自动驾驶算法的测试和验证。此外,该模型还可以扩展到其他需要长时域预测的领域,如机器人导航和视频游戏。
📄 摘要(原文)
Existing world models for autonomous driving struggle with long-horizon generation and generalization to challenging scenarios. In this work, we develop a model using simple design choices, and without additional supervision or sensors, such as maps, depth, or multiple cameras. We show that our model yields state-of-the-art performance, despite having only 469M parameters and being trained on 280h of video data. It particularly stands out in difficult scenarios like turning maneuvers and urban traffic. We test whether discrete token models possibly have advantages over continuous models based on flow matching. To this end, we set up a hybrid tokenizer that is compatible with both approaches and allows for a side-by-side comparison. Our study concludes in favor of the continuous autoregressive model, which is less brittle on individual design choices and more powerful than the model built on discrete tokens. Code, models and qualitative results are publicly available at https://lmb-freiburg.github.io/orbis.github.io/.