DINO-VO: A Feature-based Visual Odometry Leveraging a Visual Foundation Model
作者: Maulana Bisyir Azhari, David Hyunchul Shim
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-07-17
备注: 8 pages, 6 figures. Accepted for publication in IEEE Robotics and Automation Letters (RA-L), July 2025
💡 一句话要点
DINO-VO:利用视觉基础模型DINOv2的特征点视觉里程计,提升鲁棒性和泛化性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉里程计 视觉基础模型 DINOv2 特征匹配 机器人导航
📋 核心要点
- 现有基于学习的单目VO方法在鲁棒性、泛化性和效率方面存在不足,难以应对复杂环境。
- DINO-VO利用DINOv2视觉基础模型提取特征,并结合定制的关键点检测器和几何特征,增强定位能力。
- 实验表明,DINO-VO在多个数据集上优于现有VO方法,并在户外驾驶场景中与视觉SLAM系统竞争。
📝 摘要(中文)
基于学习的单目视觉里程计(VO)在机器人领域面临鲁棒性、泛化性和效率方面的挑战。视觉基础模型(如DINOv2)的最新进展提高了各种视觉任务的鲁棒性和泛化性,但由于特征粒度粗糙,它们在VO中的集成仍然有限。本文提出了DINO-VO,一种基于特征的VO系统,利用DINOv2视觉基础模型进行稀疏特征匹配。为了解决集成挑战,我们提出了一种针对DINOv2粗糙特征定制的显著关键点检测器。此外,我们用细粒度的几何特征来补充DINOv2的鲁棒语义特征,从而产生更易于定位的表示。最后,基于Transformer的匹配器和可微姿态估计层通过学习良好的匹配来实现精确的相机运动估计。与之前的检测器-描述符网络(如SuperPoint)相比,DINO-VO在具有挑战性的环境中表现出更强的鲁棒性。此外,我们展示了所提出的特征描述符相对于独立的DINOv2粗糙特征具有更高的准确性和泛化性。DINO-VO在TartanAir和KITTI数据集上优于之前的帧到帧VO方法,并且在EuRoC数据集上具有竞争力,同时在单个GPU上以72 FPS的效率运行,内存使用量小于1GB。此外,它在户外驾驶场景中与视觉SLAM系统相比具有竞争力,展示了其泛化能力。
🔬 方法详解
问题定义:论文旨在解决单目视觉里程计在复杂环境下的鲁棒性和泛化性问题。现有的基于学习的VO方法,以及直接使用视觉基础模型提取的特征,难以在各种场景中保持良好的性能,尤其是在特征稀疏或光照变化剧烈的环境中。
核心思路:论文的核心思路是利用视觉基础模型DINOv2提取的语义特征,并结合定制的关键点检测器和几何特征,从而获得更鲁棒和更具区分性的特征表示。通过Transformer匹配器学习特征之间的对应关系,并使用可微姿态估计层优化相机位姿。
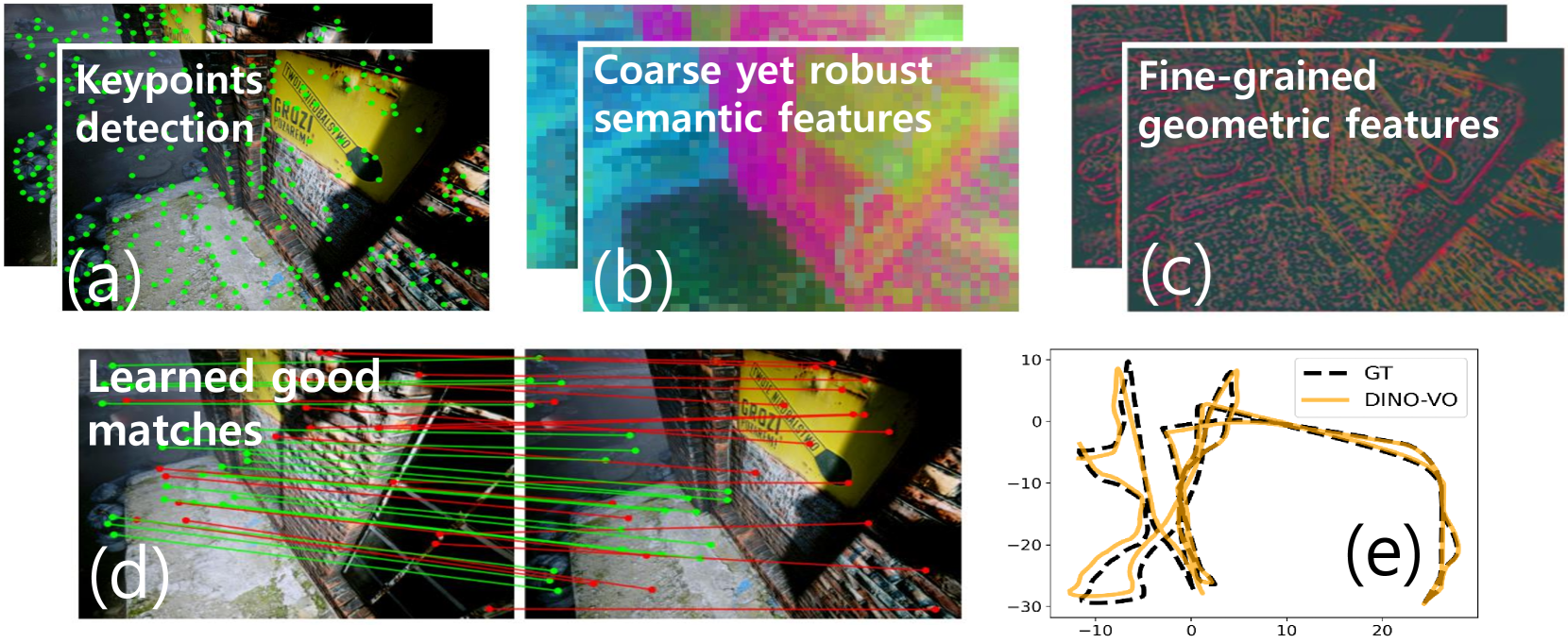
技术框架:DINO-VO系统主要包含以下几个模块:1) 基于DINOv2的特征提取器,提取图像的粗糙语义特征;2) 显著关键点检测器,用于在DINOv2特征图上选择关键点;3) 几何特征提取器,提取关键点周围的局部几何特征;4) 基于Transformer的特征匹配器,用于学习不同图像帧之间的特征对应关系;5) 可微姿态估计层,用于根据特征匹配结果估计相机位姿。
关键创新:论文的关键创新在于:1) 提出了一种针对DINOv2粗糙特征定制的显著关键点检测器,能够有效地选择具有代表性的关键点;2) 将DINOv2的语义特征与几何特征相结合,从而获得更鲁棒和更具区分性的特征表示;3) 使用基于Transformer的匹配器学习特征之间的对应关系,提高了匹配的准确性。
关键设计:关键点检测器可能采用了基于梯度或局部最大值的策略,以适应DINOv2特征的特性。几何特征可能包括SIFT、ORB等传统特征。Transformer匹配器可能使用了自注意力机制来学习特征之间的关系。可微姿态估计层可能使用了迭代最近点(ICP)或光束法平差(Bundle Adjustment)等方法进行优化。
🖼️ 关键图片


📊 实验亮点
DINO-VO在TartanAir和KITTI数据集上优于之前的帧到帧VO方法,并在EuRoC数据集上具有竞争力。在单个GPU上以72 FPS的效率运行,内存使用量小于1GB。与SuperPoint等方法相比,DINO-VO在具有挑战性的环境中表现出更强的鲁棒性。在户外驾驶场景中与视觉SLAM系统相比具有竞争力,展示了其泛化能力。
🎯 应用场景
DINO-VO可应用于机器人导航、自动驾驶、增强现实等领域。其鲁棒性和泛化性使其能够在各种复杂环境中实现精确的定位和建图,为机器人和智能系统的自主运行提供可靠的基础。该研究的成果有助于推动视觉里程计技术的发展,并促进其在更广泛领域的应用。
📄 摘要(原文)
Learning-based monocular visual odometry (VO) poses robustness, generalization, and efficiency challenges in robotics. Recent advances in visual foundation models, such as DINOv2, have improved robustness and generalization in various vision tasks, yet their integration in VO remains limited due to coarse feature granularity. In this paper, we present DINO-VO, a feature-based VO system leveraging DINOv2 visual foundation model for its sparse feature matching. To address the integration challenge, we propose a salient keypoints detector tailored to DINOv2's coarse features. Furthermore, we complement DINOv2's robust-semantic features with fine-grained geometric features, resulting in more localizable representations. Finally, a transformer-based matcher and differentiable pose estimation layer enable precise camera motion estimation by learning good matches. Against prior detector-descriptor networks like SuperPoint, DINO-VO demonstrates greater robustness in challenging environments. Furthermore, we show superior accuracy and generalization of the proposed feature descriptors against standalone DINOv2 coarse features. DINO-VO outperforms prior frame-to-frame VO methods on the TartanAir and KITTI datasets and is competitive on EuRoC dataset, while running efficiently at 72 FPS with less than 1GB of memory usage on a single GPU. Moreover, it performs competitively against Visual SLAM systems on outdoor driving scenarios, showcasing its generalization capabilities.