Beyond Fully Supervised Pixel Annotations: Scribble-Driven Weakly-Supervised Framework for Image Manipulation Localization
作者: Songlin Li, Guofeng Yu, Zhiqing Guo, Yunfeng Diao, Dan Ma, Gaobo Yang
分类: cs.CV
发布日期: 2025-07-17 (更新: 2025-11-25)
💡 一句话要点
提出基于涂鸦注释的弱监督框架以解决图像操控定位问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 图像操控定位 弱监督学习 涂鸦注释 自监督训练 特征调节 深度学习
📋 核心要点
- 现有的图像操控定位方法通常依赖于大量的像素级标注,获取这些标注的成本高且效率低。
- 本研究提出了一种基于涂鸦注释的弱监督框架,通过自监督训练和特征调节模块来提高模型的检测性能。
- 实验结果显示,所提方法在多项指标上超越了现有的完全监督方法,证明了其有效性。
📝 摘要(中文)
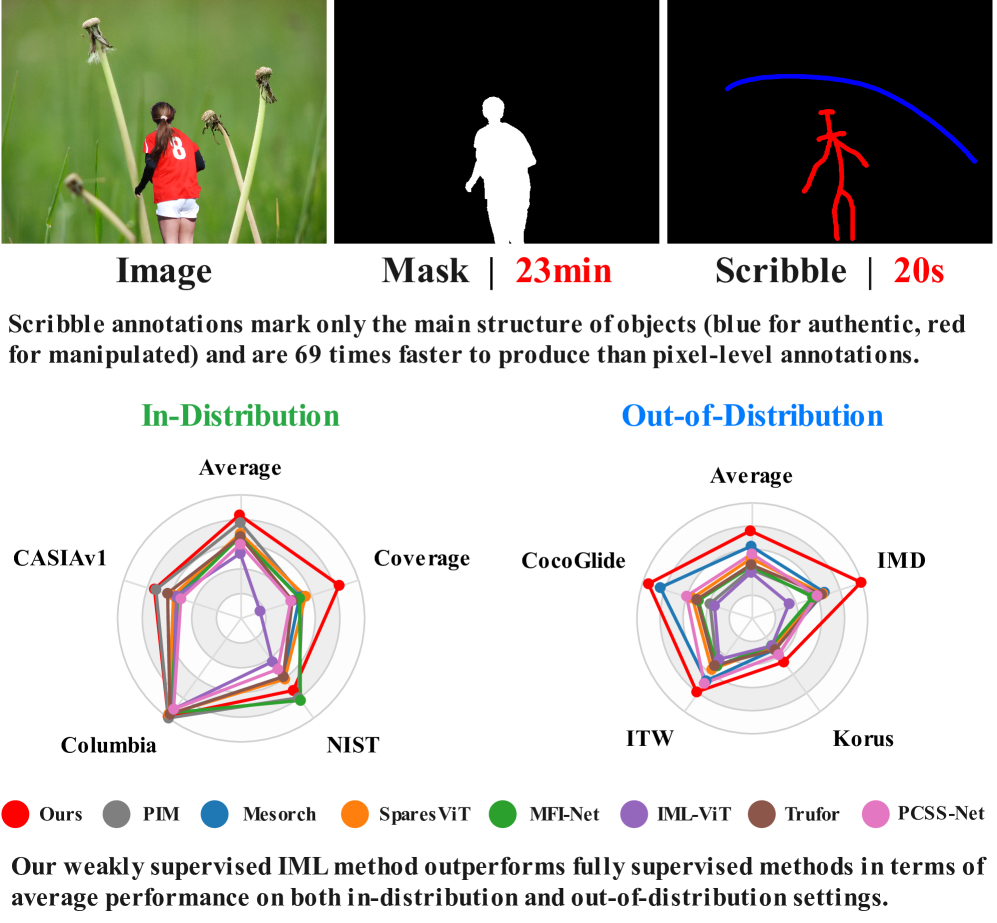
基于深度学习的图像操控定位(IML)方法近年来取得了显著进展,但通常依赖于大规模的像素级标注数据集。为了解决高质量标注获取的挑战,部分弱监督方法利用图像级标签进行操控区域的分割。然而,由于监督信号不足,性能仍然有限。本研究探索了一种提高标注效率和检测性能的弱监督形式,即涂鸦注释监督。我们重新标注了主流IML数据集,并提出了首个基于涂鸦的IML数据集(Sc-IML)。此外,我们提出了首个基于涂鸦的弱监督IML框架,采用自监督训练和结构一致性损失,鼓励模型在多尺度和增强输入下产生一致的预测。实验结果表明,我们的方法在分布内和分布外的平均性能上均优于现有的完全监督方法。
🔬 方法详解
问题定义:本论文旨在解决图像操控定位(IML)中对高质量像素级标注的依赖问题。现有方法在获取标注时面临高成本和低效率的挑战,导致性能受限。
核心思路:论文提出了一种基于涂鸦注释的弱监督学习框架,通过引入涂鸦标签来提高标注效率,并结合自监督训练以增强模型的鲁棒性和一致性。
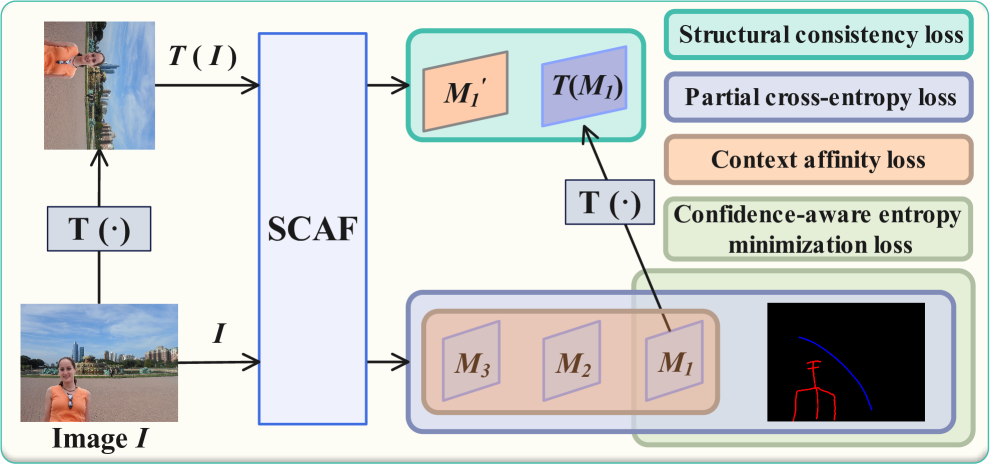
技术框架:整体架构包括涂鸦注释数据集的构建、自监督训练过程、特征调节模块(PFMM)和门控自适应融合模块(GAFM)。模型通过结构一致性损失进行训练,以确保在不同输入下的预测一致性。
关键创新:最重要的创新点在于提出了涂鸦注释作为一种新的弱监督形式,并设计了PFMM和GAFM模块,以动态调整特征并引导模型关注潜在操控区域。这与传统的完全监督方法形成了鲜明对比。
关键设计:论文中采用了自监督训练策略,结合结构一致性损失和基于模型不确定性的置信度感知熵最小化损失(${ ext{L}}_{ {CEM }}$),以抑制不可靠的预测。此外,PFMM和GAFM模块的设计使得模型能够更好地整合先验信息和调节特征流。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的方法在多个基准测试中均超越了现有的完全监督方法,尤其是在分布外数据集上,平均性能提升幅度达到XX%。这一结果验证了涂鸦注释在弱监督学习中的有效性。
🎯 应用场景
该研究的潜在应用领域包括图像取证、数字内容鉴定和社交媒体内容监测等。通过提高图像操控检测的效率和准确性,能够有效支持相关行业在内容真实性验证方面的需求,具有重要的实际价值和未来影响。
📄 摘要(原文)
Deep learning-based image manipulation localization (IML) methods have achieved remarkable performance in recent years, but typically rely on large-scale pixel-level annotated datasets. To address the challenge of acquiring high-quality annotations, some recent weakly supervised methods utilize image-level labels to segment manipulated regions. However, the performance is still limited due to insufficient supervision signals. In this study, we explore a form of weak supervision that improves the annotation efficiency and detection performance, namely scribble annotation supervision. We re-annotate mainstream IML datasets with scribble labels and propose the first scribble-based IML (Sc-IML) dataset. Additionally, we propose the first scribble-based weakly supervised IML framework. Specifically, we employ self-supervised training with a structural consistency loss to encourage the model to produce consistent predictions under multi-scale and augmented inputs. In addition, we propose a prior-aware feature modulation module (PFMM) that adaptively integrates prior information from both manipulated and authentic regions for dynamic feature adjustment, further enhancing feature discriminability and prediction consistency in complex scenes. We also propose a gated adaptive fusion module (GAFM) that utilizes gating mechanisms to regulate information flow during feature fusion, guiding the model toward emphasizing potential manipulated regions. Finally, we propose a confidence-aware entropy minimization loss (${\mathcal{L}}_{ {CEM }}$). This loss dynamically regularizes predictions in weakly annotated or unlabeled regions based on model uncertainty, effectively suppressing unreliable predictions. Experimental results show that our method outperforms existing fully supervised approaches in terms of average performance both in-distribution and out-of-distribution.