AnyCap Project: A Unified Framework, Dataset, and Benchmark for Controllable Omni-modal Captioning
作者: Yiming Ren, Zhiqiang Lin, Yu Li, Gao Meng, Weiyun Wang, Junjie Wang, Zicheng Lin, Jifeng Dai, Yujiu Yang, Wenhai Wang, Ruihang Chu
分类: cs.CV
发布日期: 2025-07-17 (更新: 2025-10-28)
💡 一句话要点
AnyCap项目:提出统一框架、数据集和基准,用于可控全模态图像/视频描述生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可控描述生成 多模态学习 图像描述 视频描述 指令跟随 数据集构建 评估基准
📋 核心要点
- 现有图像/视频描述模型缺乏细粒度控制,难以满足用户对内容和风格的定制化需求,且缺乏可靠的评估标准。
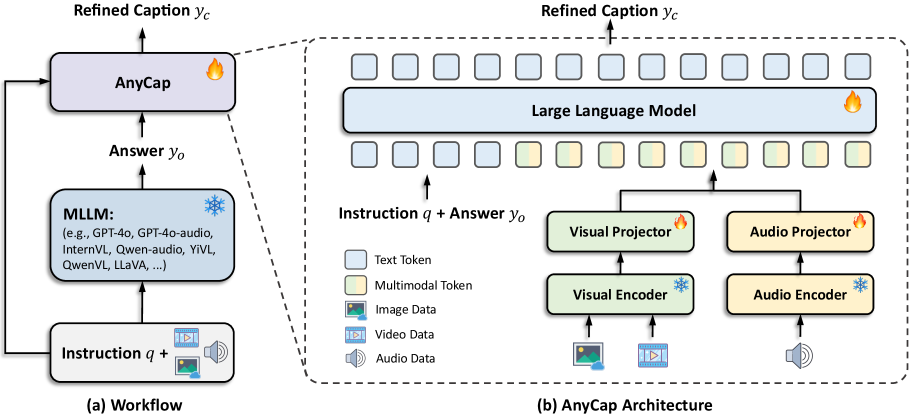
- AnyCap项目提出AnyCapModel,一个轻量级框架,通过结合用户指令和模态特征,增强现有基础模型的可控性,无需重新训练。
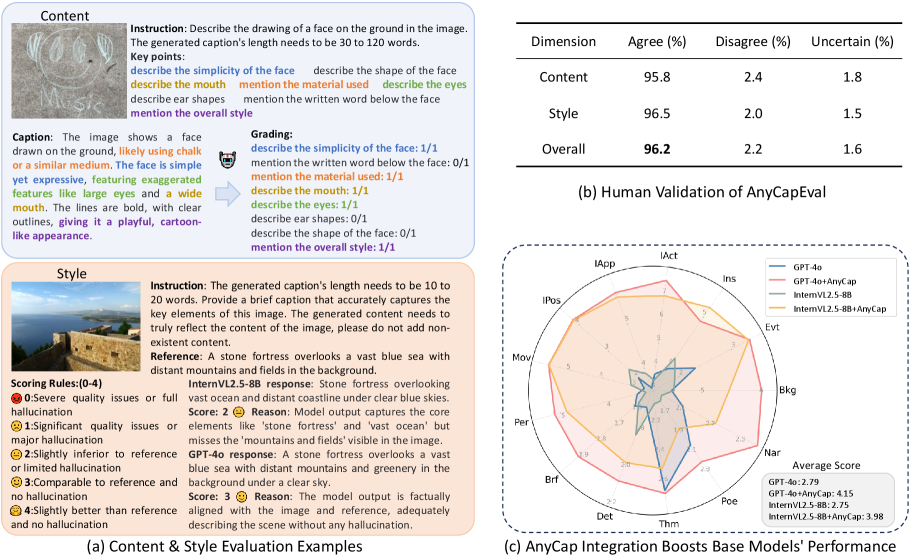
- AnyCap项目构建了AnyCapDataset和AnyCapEval,分别用于解决数据稀缺和评估标准不完善的问题,并在多个基准测试中取得显著提升。
📝 摘要(中文)
可控的图像/视频描述生成对于精确的多模态对齐和指令跟随至关重要,但现有模型通常缺乏细粒度的控制和可靠的评估协议。为了解决这个问题,我们提出了AnyCap项目,这是一个涵盖模型、数据集和评估的集成解决方案。我们引入了AnyCapModel (ACM),这是一个轻量级的即插即用框架,它增强了现有基础模型在全模态描述生成方面的可控性,而无需重新训练基础模型。ACM重用来自基础模型的原始描述,同时结合用户指令和模态特征来生成改进的描述。为了弥补可控多模态描述生成中数据稀缺的问题,我们构建了AnyCapDataset (ACD),涵盖三种模态、28种用户指令类型和30万个高质量数据条目。我们进一步提出了AnyCapEval,一个新的基准,通过解耦内容准确性和风格保真度,为可控描述生成提供更可靠的评估指标。ACM显著提高了AnyCapEval上各种基础模型的描述质量。值得注意的是,ACM-8B将GPT-4o的内容得分提高了45%,风格得分提高了12%,并且在广泛使用的基准(如MIA-Bench和VidCapBench)上也取得了显著的提升。
🔬 方法详解
问题定义:现有图像/视频描述模型难以实现细粒度的可控性,无法根据用户指令生成特定内容或风格的描述。此外,缺乏统一的数据集和评估标准,难以公平地比较不同模型的可控描述生成能力。现有方法通常需要从头训练模型,成本高昂,且难以充分利用预训练模型的知识。
核心思路:AnyCap项目的核心思路是利用一个轻量级的即插即用框架(AnyCapModel),在不重新训练基础模型的前提下,通过融合用户指令和模态特征,增强现有模型的描述生成能力。通过构建大规模数据集(AnyCapDataset)和设计合理的评估指标(AnyCapEval),为可控描述生成提供统一的训练和评估平台。
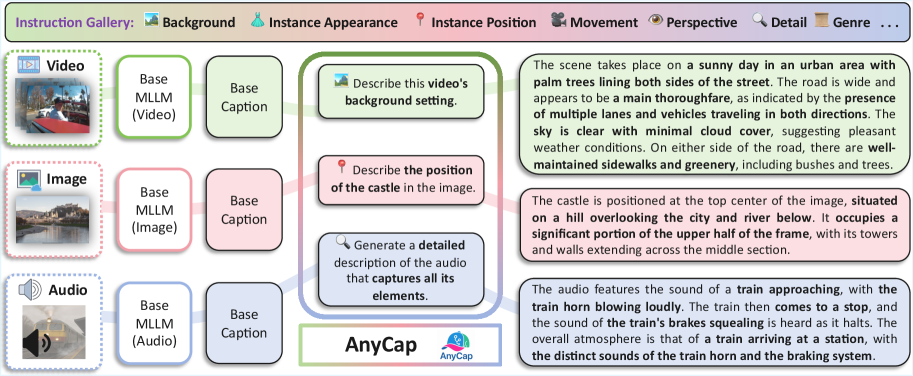
技术框架:AnyCapModel (ACM) 的整体架构是一个即插即用的模块,可以添加到现有的预训练模型中。它主要包含以下几个模块:1) 指令编码器:将用户指令编码成向量表示。2) 模态特征提取器:提取输入图像或视频的特征。3) 融合模块:将指令向量和模态特征融合,得到最终的特征表示。4) 描述生成器:利用融合后的特征生成描述文本。AnyCapDataset (ACD) 包含三种模态的数据,并标注了多种用户指令类型。AnyCapEval 包含内容准确性和风格保真度两个方面的评估指标。
关键创新:AnyCap项目的关键创新在于提出了一个轻量级的即插即用框架,可以在不重新训练基础模型的情况下,显著提高模型的可控描述生成能力。此外,AnyCapDataset和AnyCapEval的构建,为可控描述生成提供了一个统一的训练和评估平台。与现有方法相比,AnyCapModel更加灵活高效,可以方便地应用于各种预训练模型。
关键设计:AnyCapModel的关键设计包括:1) 指令编码器的选择:可以使用预训练的语言模型(如BERT)或简单的词嵌入模型。2) 模态特征提取器的选择:可以使用预训练的视觉模型(如ResNet)或视频模型(如TimeSformer)。3) 融合模块的设计:可以使用简单的拼接或注意力机制。4) 损失函数的设计:可以使用交叉熵损失或对比学习损失。具体参数设置和网络结构的选择取决于具体的基础模型和任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AnyCapModel在AnyCapEval上显著提高了各种基础模型的描述质量。例如,ACM-8B将GPT-4o的内容得分提高了45%,风格得分提高了12%。此外,ACM在MIA-Bench和VidCapBench等广泛使用的基准测试中也取得了显著的提升,证明了其通用性和有效性。
🎯 应用场景
该研究成果可广泛应用于智能客服、图像/视频检索、辅助写作等领域。例如,用户可以通过指定指令,让模型生成特定风格或内容的图像/视频描述,从而提高信息检索的效率和准确性。未来,该技术还可以应用于机器人导航、自动驾驶等领域,帮助机器人更好地理解周围环境。
📄 摘要(原文)
Controllable captioning is essential for precise multimodal alignment and instruction following, yet existing models often lack fine-grained control and reliable evaluation protocols. To address this gap, we present the AnyCap Project, an integrated solution spanning model, dataset, and evaluation. We introduce AnyCapModel (ACM), a lightweight plug-and-play framework that enhances the controllability of existing foundation models for omni-modal captioning without retraining the base model. ACM reuses the original captions from base models while incorporating user instructions and modality features to generate improved captions. To remedy the data scarcity in controllable multimodal captioning, we build AnyCapDataset (ACD), covering three modalities, 28 user-instruction types, and 300\,k high-quality data entries. We further propose AnyCapEval, a new benchmark that provides more reliable evaluation metrics for controllable captioning by decoupling content accuracy and stylistic fidelity. ACM markedly improves caption quality across a diverse set of base models on AnyCapEval. Notably, ACM-8B raises GPT-4oś content scores by 45\% and style scores by 12\%, and it also achieves substantial gains on widely used benchmarks such as MIA-Bench and VidCapBench.