AnyPos: Automated Task-Agnostic Actions for Bimanual Manipulation
作者: Hengkai Tan, Yao Feng, Xinyi Mao, Shuhe Huang, Guodong Liu, Zhongkai Hao, Hang Su, Jun Zhu
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-07-17
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
AnyPos:面向双臂操作的自动化、任务无关动作学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂操作 任务无关学习 逆动力学模型 自动化数据收集 视觉语言动作 机器人学习 动作规划
📋 核心要点
- 现有VLA模型依赖大量任务特定人工演示,泛化性差且数据采集成本高昂。
- AnyPos提出任务无关动作范式,解耦动作执行与任务条件,提升可扩展性和效率。
- ATARA加速数据收集,AnyPos模型解决分布不匹配问题,实验验证有效性。
📝 摘要(中文)
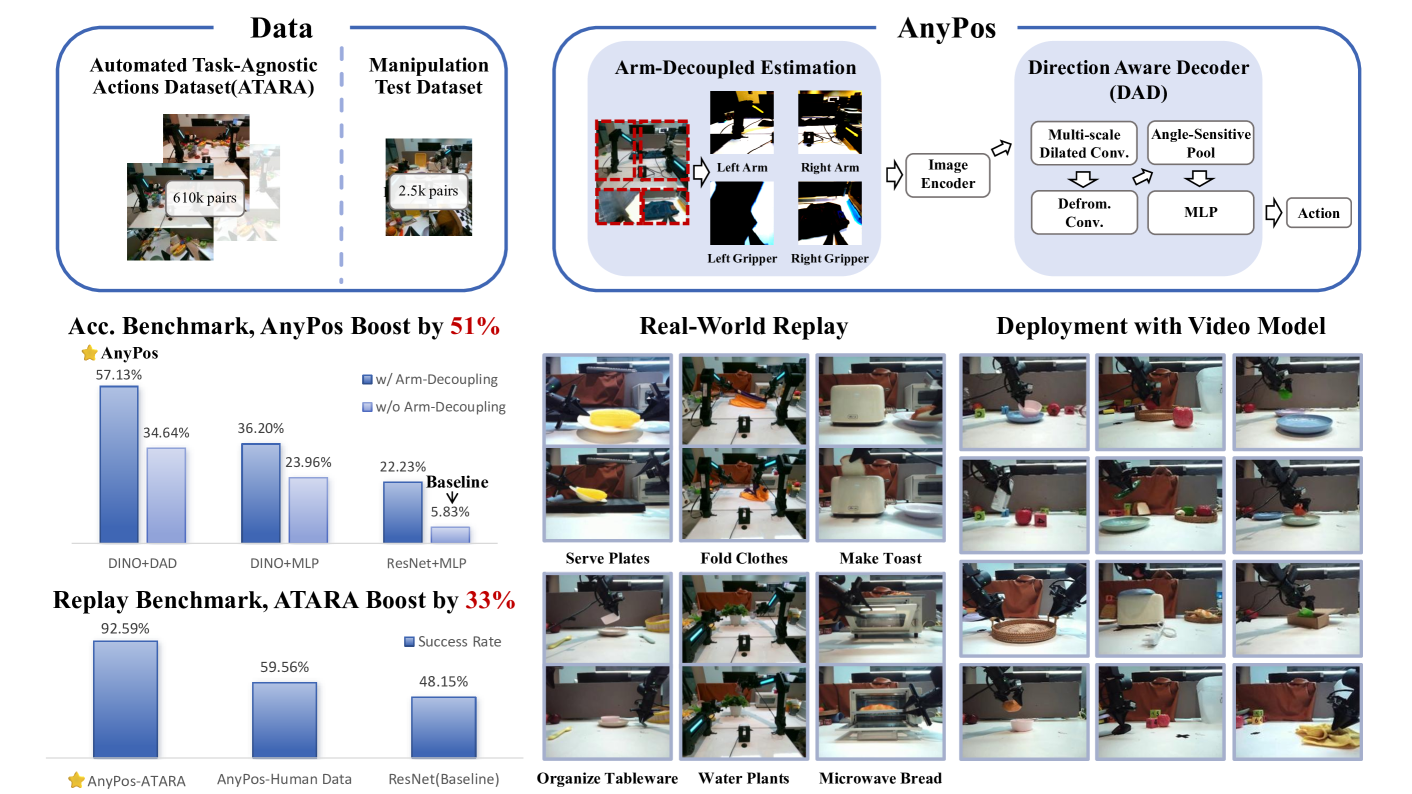
视觉-语言-动作(VLA)模型在双臂操作等复杂环境中展现了潜力,但对任务特定的人工演示的严重依赖限制了其泛化能力,并导致高昂的数据采集成本。本文提出了一种新的任务无关动作范式,将动作执行与任务特定条件解耦,从而提高可扩展性、效率和成本效益。为了应对这种范式带来的数据收集挑战(如覆盖密度低、行为冗余和安全风险),我们引入了ATARA(自动化任务无关随机动作),这是一个可扩展的自监督框架,与人工遥操作相比,可将收集速度提高30倍以上。为了进一步实现从任务无关数据中进行有效学习(这些数据通常存在分布不匹配和不相关轨迹的问题),我们提出了AnyPos,一个配备了手臂解耦估计和方向感知解码器(DAD)的逆动力学模型。此外,我们还集成了一个视频条件动作验证模块,以验证学习策略在各种操作任务中的可行性。大量实验表明,AnyPos-ATARA流程在测试精度方面提高了51%,并在诸如举起、拾取放置和点击等下游任务中实现了30-40%的更高成功率,并使用了基于回放的视频验证。
🔬 方法详解
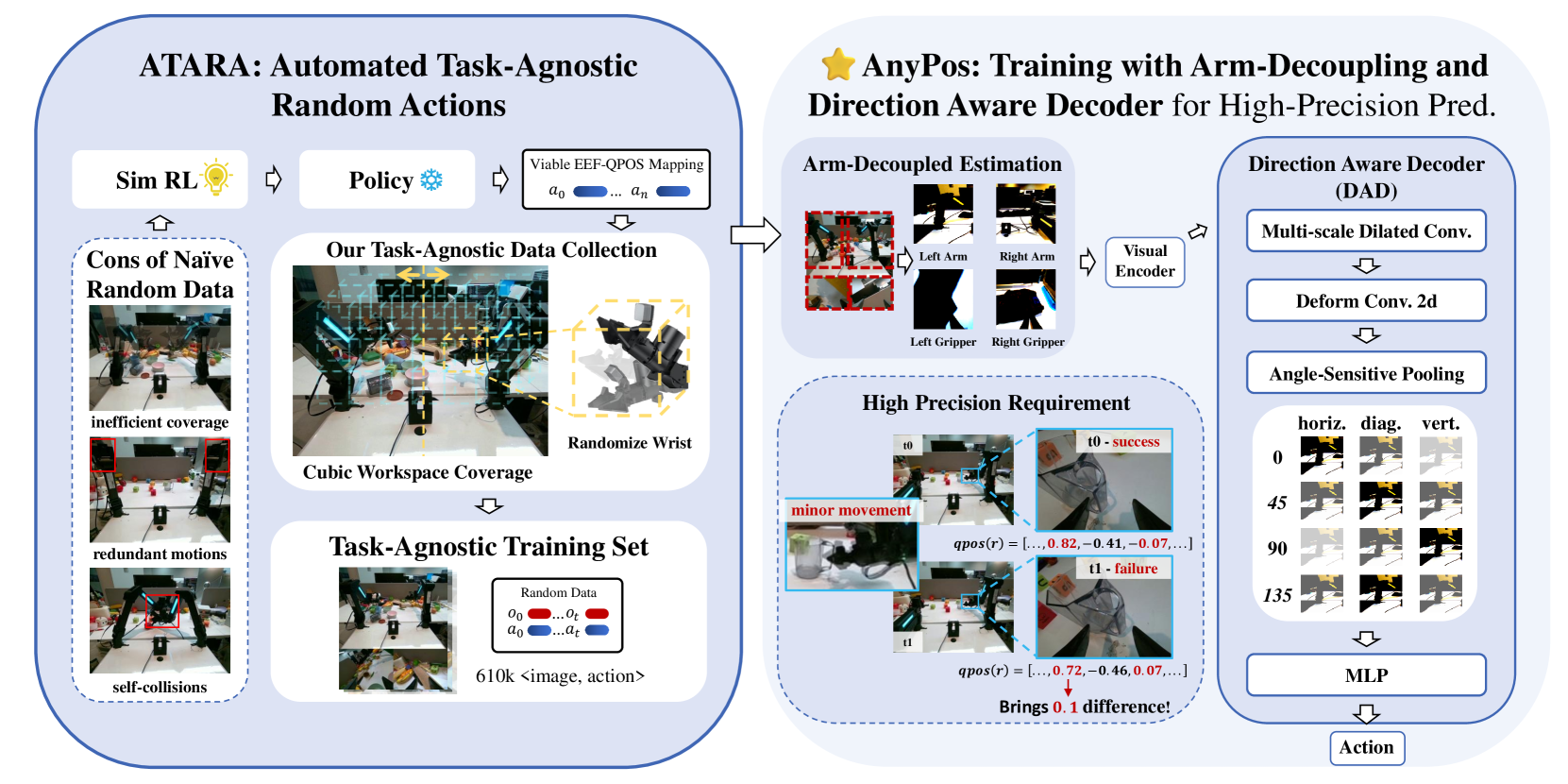
问题定义:现有基于视觉-语言-动作的双臂操作模型严重依赖于任务特定的人工演示数据,这限制了模型的泛化能力,并且数据采集成本非常高昂。人工演示不仅耗时,而且难以覆盖所有可能的动作空间,导致模型在未见过的情形下表现不佳。此外,人工操作还存在安全风险,尤其是在需要进行高强度或危险操作时。
核心思路:AnyPos的核心思路是提出一种任务无关的动作范式,将动作的执行与具体的任务条件解耦。这意味着模型学习的动作不再是针对特定任务设计的,而是通用的、可以适应多种任务的。通过这种方式,可以大大减少对任务特定数据的依赖,提高模型的泛化能力和数据效率。同时,通过自动化数据收集,可以降低人工成本和安全风险。
技术框架:AnyPos的整体框架包含两个主要部分:ATARA(Automated Task-Agnostic Random Actions)和AnyPos模型。ATARA负责自动生成任务无关的随机动作数据,解决数据收集问题。AnyPos模型是一个逆动力学模型,用于学习从视觉输入到动作的映射关系。该模型配备了手臂解耦估计(Arm-Decoupled Estimation)和方向感知解码器(Direction-Aware Decoder,DAD),以提高学习效率和动作精度。此外,还包含一个视频条件动作验证模块,用于验证学习策略在不同任务中的可行性。
关键创新:AnyPos的关键创新在于其任务无关的动作范式和ATARA自动化数据收集方法。任务无关范式使得模型可以学习到更通用的动作表示,从而提高泛化能力。ATARA通过自动探索动作空间,高效地生成大量训练数据,解决了数据稀缺问题。手臂解耦估计和方向感知解码器则进一步提高了模型的学习效率和动作精度。
关键设计:手臂解耦估计将双臂的动作分别进行估计,降低了学习难度。方向感知解码器(DAD)在解码动作时考虑了动作的方向信息,提高了动作的准确性。视频条件动作验证模块使用视频作为条件,判断学习到的动作是否可行,从而过滤掉不合理的动作。损失函数的设计也至关重要,需要平衡动作的准确性和多样性。具体的网络结构和参数设置需要根据实际任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AnyPos-ATARA流程在测试精度方面比现有方法提高了51%,并在举起、拾取放置和点击等下游任务中实现了30-40%的更高成功率。这些结果验证了AnyPos的任务无关动作范式的有效性和ATARA自动化数据收集方法的优势。视频条件动作验证模块也显著提高了策略的可靠性。
🎯 应用场景
AnyPos具有广泛的应用前景,可应用于工业自动化、家庭服务机器人、医疗康复等领域。例如,在工业自动化中,机器人可以利用AnyPos学习到的通用动作来完成各种装配、搬运任务。在家庭服务机器人中,可以帮助机器人完成清洁、整理等家务。在医疗康复领域,可以辅助患者进行肢体康复训练,提高康复效果。该研究降低了机器人学习成本,加速了机器人智能化进程。
📄 摘要(原文)
Vision-language-action (VLA) models have shown promise on task-conditioned control in complex settings such as bimanual manipulation. However, the heavy reliance on task-specific human demonstrations limits their generalization and incurs high data acquisition costs. In this work, we present a new notion of task-agnostic action paradigm that decouples action execution from task-specific conditioning, enhancing scalability, efficiency, and cost-effectiveness. To address the data collection challenges posed by this paradigm -- such as low coverage density, behavioral redundancy, and safety risks -- we introduce ATARA (Automated Task-Agnostic Random Actions), a scalable self-supervised framework that accelerates collection by over $ 30\times $ compared to human teleoperation. To further enable effective learning from task-agnostic data, which often suffers from distribution mismatch and irrelevant trajectories, we propose AnyPos, an inverse dynamics model equipped with Arm-Decoupled Estimation and a Direction-Aware Decoder (DAD). We additionally integrate a video-conditioned action validation module to verify the feasibility of learned policies across diverse manipulation tasks. Extensive experiments show that the AnyPos-ATARA pipeline yields a 51% improvement in test accuracy and achieves 30-40% higher success rates in downstream tasks such as lifting, pick-and-place, and clicking, using replay-based video validation. Project Page: https://embodiedfoundation.github.io/vidar_anypos