Pixel Perfect MegaMed: A Megapixel-Scale Vision-Language Foundation Model for Generating High Resolution Medical Images
作者: Zahra TehraniNasab, Hujun Ni, Amar Kumar, Tal Arbel
分类: eess.IV, cs.CV
发布日期: 2025-07-17 (更新: 2025-08-25)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Pixel Perfect MegaMed:用于生成高分辨率医学图像的百万像素级视觉-语言基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像合成 视觉-语言模型 高分辨率图像生成 Transformer 数据增强 CheXpert数据集 多尺度特征 胸部X光片
📋 核心要点
- 现有GAN和VAE等方法难以在高分辨率医学图像生成中保留精细细节,影响诊断准确性。
- Pixel Perfect MegaMed采用多尺度Transformer架构,结合视觉-语言对齐,生成1024x1024高分辨率图像。
- 在CheXpert数据集上,该模型能从文本生成逼真的胸部X光片,并提升下游分类任务的性能。
📝 摘要(中文)
医学图像合成由于临床环境对固有复杂性和高分辨率细节的要求而面临独特的挑战。传统的生成架构,如生成对抗网络(GANs)或变分自编码器(VAEs),在高分辨率图像生成方面显示出巨大的潜力,但难以保留对准确诊断至关重要的精细细节。为了解决这个问题,我们推出了Pixel Perfect MegaMed,这是第一个以1024x1024分辨率合成图像的视觉-语言基础模型。我们的方法部署了一种专为超高分辨率医学图像生成而设计的多尺度Transformer架构,能够保留全局解剖学上下文和局部图像级细节。通过利用针对医学术语和成像模式量身定制的视觉-语言对齐技术,Pixel Perfect MegaMed以前所未有的分辨率水平弥合了文本描述和视觉表示之间的差距。我们将我们的模型应用于CheXpert数据集,并展示了其从文本提示生成临床上忠实的胸部X光片的能力。除了视觉质量之外,这些高分辨率合成图像被证明对分类等下游任务有价值,在用于数据增强时显示出可衡量的性能提升,尤其是在低数据情况下。
🔬 方法详解
问题定义:医学图像合成需要生成具有高分辨率和精细细节的图像,这对现有的生成模型(如GANs和VAEs)提出了挑战。这些模型在高分辨率下难以保持图像的细节,导致生成的图像在临床应用中不够准确。因此,需要一种能够生成高分辨率且保留细节的医学图像合成方法。
核心思路:Pixel Perfect MegaMed的核心思路是利用多尺度Transformer架构,结合视觉-语言对齐技术,从而在生成高分辨率医学图像的同时,保留图像的全局上下文信息和局部细节。通过视觉-语言对齐,模型能够理解文本描述并将其转化为对应的医学图像。
技术框架:Pixel Perfect MegaMed采用了一种多尺度Transformer架构,该架构包含多个Transformer模块,每个模块处理不同尺度的图像特征。模型首先将文本描述编码为向量表示,然后使用该向量表示作为条件,指导Transformer生成图像。整个流程包括文本编码、多尺度特征提取、图像生成和图像重建等阶段。
关键创新:Pixel Perfect MegaMed的关键创新在于其多尺度Transformer架构和视觉-语言对齐技术。多尺度Transformer架构能够有效地处理高分辨率图像,并保留图像的细节信息。视觉-语言对齐技术使得模型能够理解文本描述,并生成与文本描述相符的医学图像。这是首个能够生成1024x1024分辨率医学图像的视觉-语言基础模型。
关键设计:模型使用了交叉注意力机制来实现视觉和语言特征的融合。损失函数包括生成对抗损失、图像重建损失和视觉-语言对齐损失。在训练过程中,使用了梯度裁剪和学习率衰减等技巧来提高模型的稳定性和收敛速度。具体参数设置未知。
🖼️ 关键图片
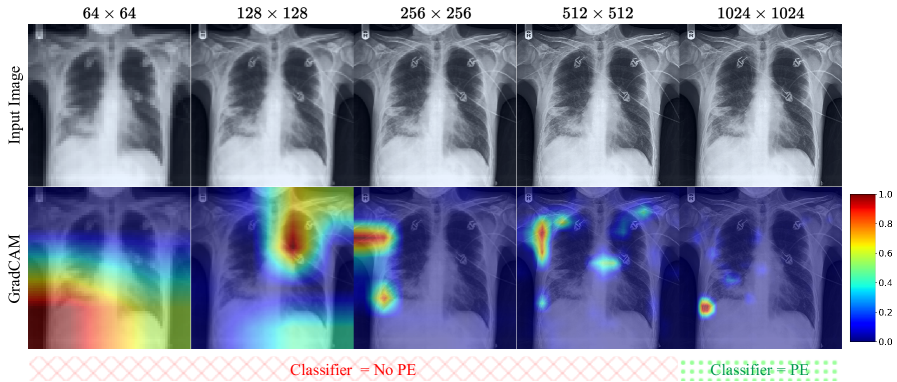
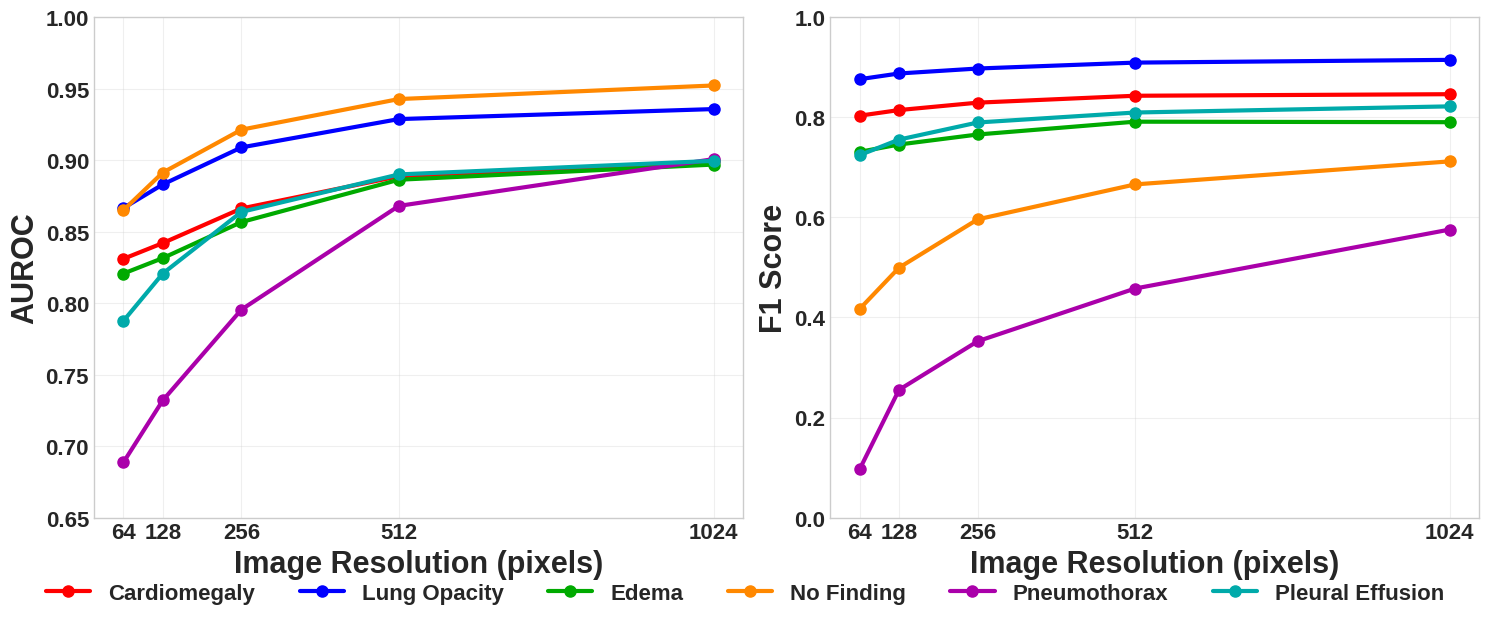
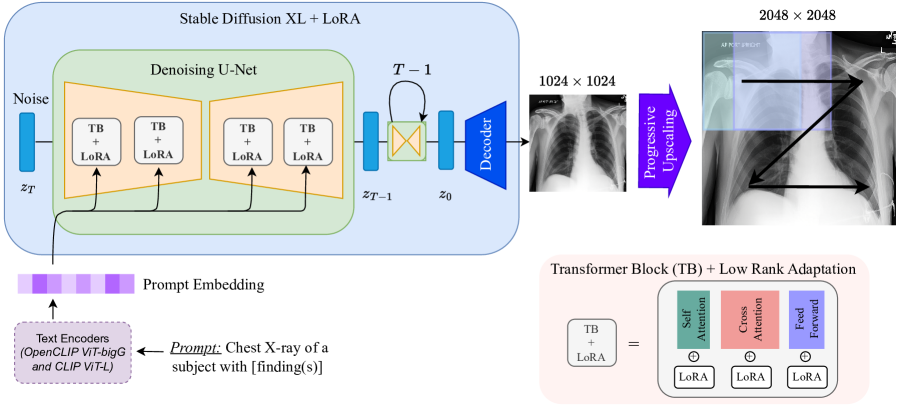
📊 实验亮点
Pixel Perfect MegaMed在CheXpert数据集上展示了其生成临床上忠实的胸部X光片的能力。实验结果表明,使用该模型生成的合成图像进行数据增强,可以显著提高下游分类任务的性能,尤其是在低数据情况下。具体的性能提升数据未知,但结果表明该模型具有实际应用价值。
🎯 应用场景
该研究成果可应用于医学图像合成、数据增强、辅助诊断等领域。通过生成高质量的合成医学图像,可以缓解医学图像数据稀缺的问题,提高医学图像分析算法的性能,并为医生提供更准确的诊断依据。未来,该技术有望应用于更多医学成像模态和疾病诊断场景。
📄 摘要(原文)
Medical image synthesis presents unique challenges due to the inherent complexity and high-resolution details required in clinical contexts. Traditional generative architectures such as Generative Adversarial Networks (GANs) or Variational Auto Encoder (VAEs) have shown great promise for high-resolution image generation but struggle with preserving fine-grained details that are key for accurate diagnosis. To address this issue, we introduce Pixel Perfect MegaMed, the first vision-language foundation model to synthesize images at resolutions of 1024x1024. Our method deploys a multi-scale transformer architecture designed specifically for ultra-high resolution medical image generation, enabling the preservation of both global anatomical context and local image-level details. By leveraging vision-language alignment techniques tailored to medical terminology and imaging modalities, Pixel Perfect MegaMed bridges the gap between textual descriptions and visual representations at unprecedented resolution levels. We apply our model to the CheXpert dataset and demonstrate its ability to generate clinically faithful chest X-rays from text prompts. Beyond visual quality, these high-resolution synthetic images prove valuable for downstream tasks such as classification, showing measurable performance gains when used for data augmentation, particularly in low-data regimes. Our code is accessible through the project website - https://tehraninasab.github.io/pixelperfect-megamed.