Mono-InternVL-1.5: Towards Cheaper and Faster Monolithic Multimodal Large Language Models
作者: Gen Luo, Wenhan Dou, Wenhao Li, Zhaokai Wang, Xue Yang, Changyao Tian, Hao Li, Weiyun Wang, Wenhai Wang, Xizhou Zhu, Yu Qiao, Jifeng Dai
分类: cs.CV, cs.CL
发布日期: 2025-07-16
🔗 代码/项目: GITHUB
💡 一句话要点
提出Mono-InternVL-1.5,一种更经济高效的单体多模态大语言模型,通过改进的预训练策略和优化推理加速,降低训练和推理成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 单体模型 视觉预训练 混合专家模型 Delta Tuning 推理加速 内生视觉预训练
📋 核心要点
- 现有单体多模态大语言模型存在优化不稳定和灾难性遗忘问题,限制了其性能和训练效率。
- 通过将新的视觉参数空间嵌入预训练LLM,并采用delta tuning,实现从噪声数据中稳定学习视觉知识。
- Mono-InternVL-1.5通过改进的内生视觉预训练和优化的推理加速,显著降低了训练和推理成本,同时保持了竞争力的性能。
📝 摘要(中文)
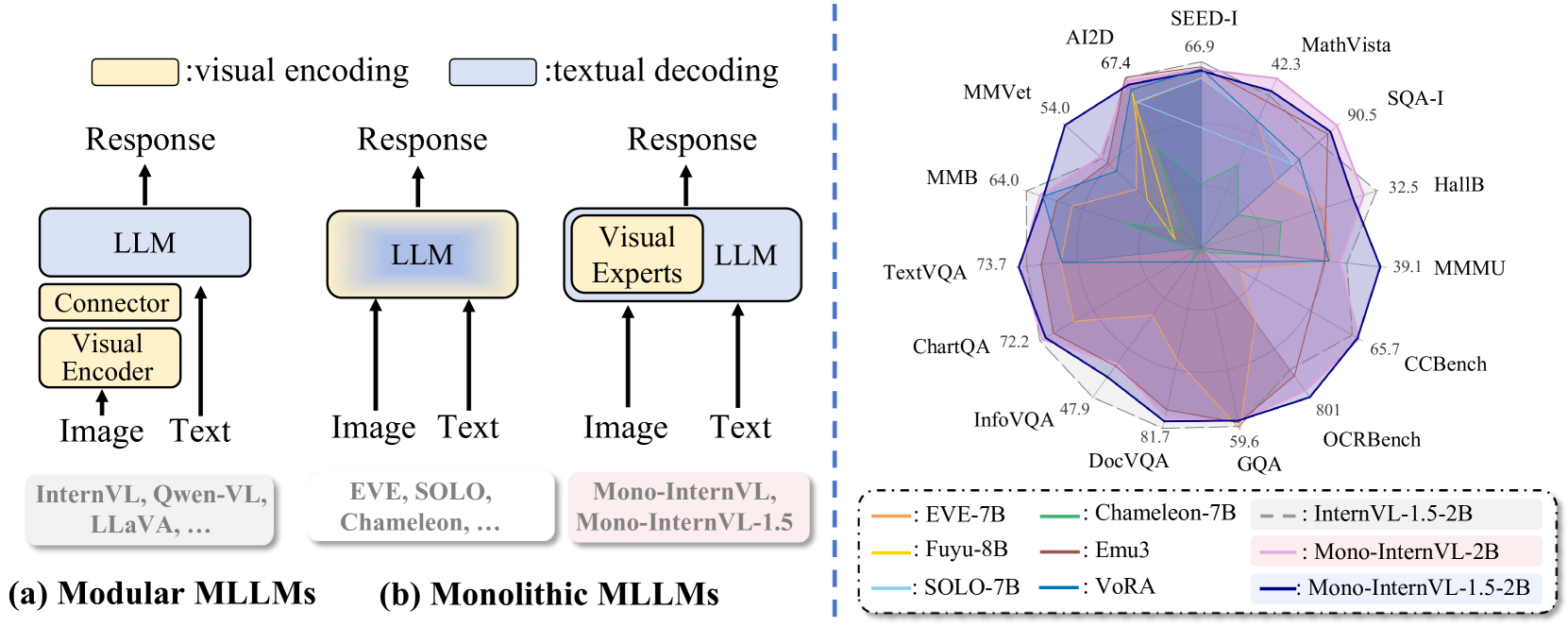
本文关注单体多模态大语言模型(MLLM),它将视觉编码和语言解码集成到单个模型中。现有的单体MLLM结构和预训练策略通常面临优化不稳定和灾难性遗忘的问题。为了解决这些挑战,我们的核心思想是将新的视觉参数空间嵌入到预训练的LLM中,从而通过delta tuning实现从噪声数据中稳定学习视觉知识。基于此,我们首先引入了Mono-InternVL,一种先进的单体MLLM,它通过多模态混合专家架构整合了一组视觉专家。此外,我们为Mono-InternVL设计了一种创新的内生视觉预训练(EViP),以通过渐进式学习最大化其视觉能力。Mono-InternVL在性能上与现有MLLM相比具有竞争力,但数据成本相对较高。因此,我们进一步提出了Mono-InternVL-1.5,一种更经济且更强大的单体MLLM,配备了改进的EViP(EViP++)。EViP++为Mono-InternVL-1.5引入了额外的视觉注意力专家,并以高效的方式重新组织了预训练过程。在推理过程中,它包含一个融合的CUDA内核来加速其MoE操作。通过这些设计,Mono-InternVL-1.5显著降低了训练和推理成本,同时保持了与Mono-InternVL相当的性能。为了评估我们的方法,我们进行了跨15个基准的广泛实验。结果表明,Mono-InternVL在15个基准中的12个上优于现有的单体MLLM,例如,在OCRBench上比Emu3提高了114个百分点。与其模块化对应物InternVL-1.5相比,Mono-InternVL-1.5实现了相似的多模态性能,同时将首个token的延迟降低了高达69%。
🔬 方法详解
问题定义:论文旨在解决单体多模态大语言模型(MLLM)训练过程中存在的优化不稳定和灾难性遗忘问题。现有方法通常难以在保持语言能力的同时有效学习视觉知识,导致模型性能受限且训练成本高昂。
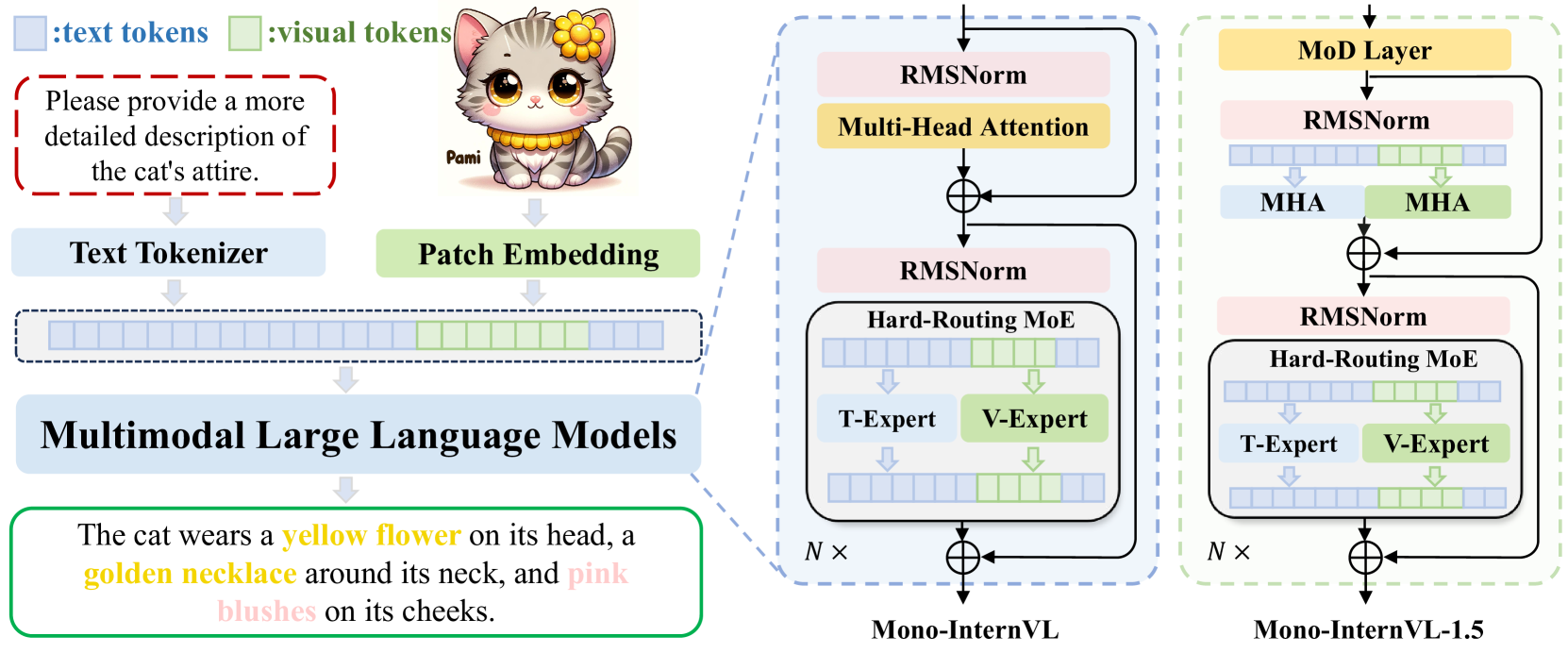
核心思路:论文的核心思路是将视觉知识的学习过程解耦,通过delta tuning的方式将新的视觉参数空间嵌入到预训练的LLM中。这种方法允许模型在不破坏原有语言知识的前提下,稳定地学习视觉信息,从而避免灾难性遗忘。同时,通过改进的预训练策略和推理优化,降低训练和推理成本。
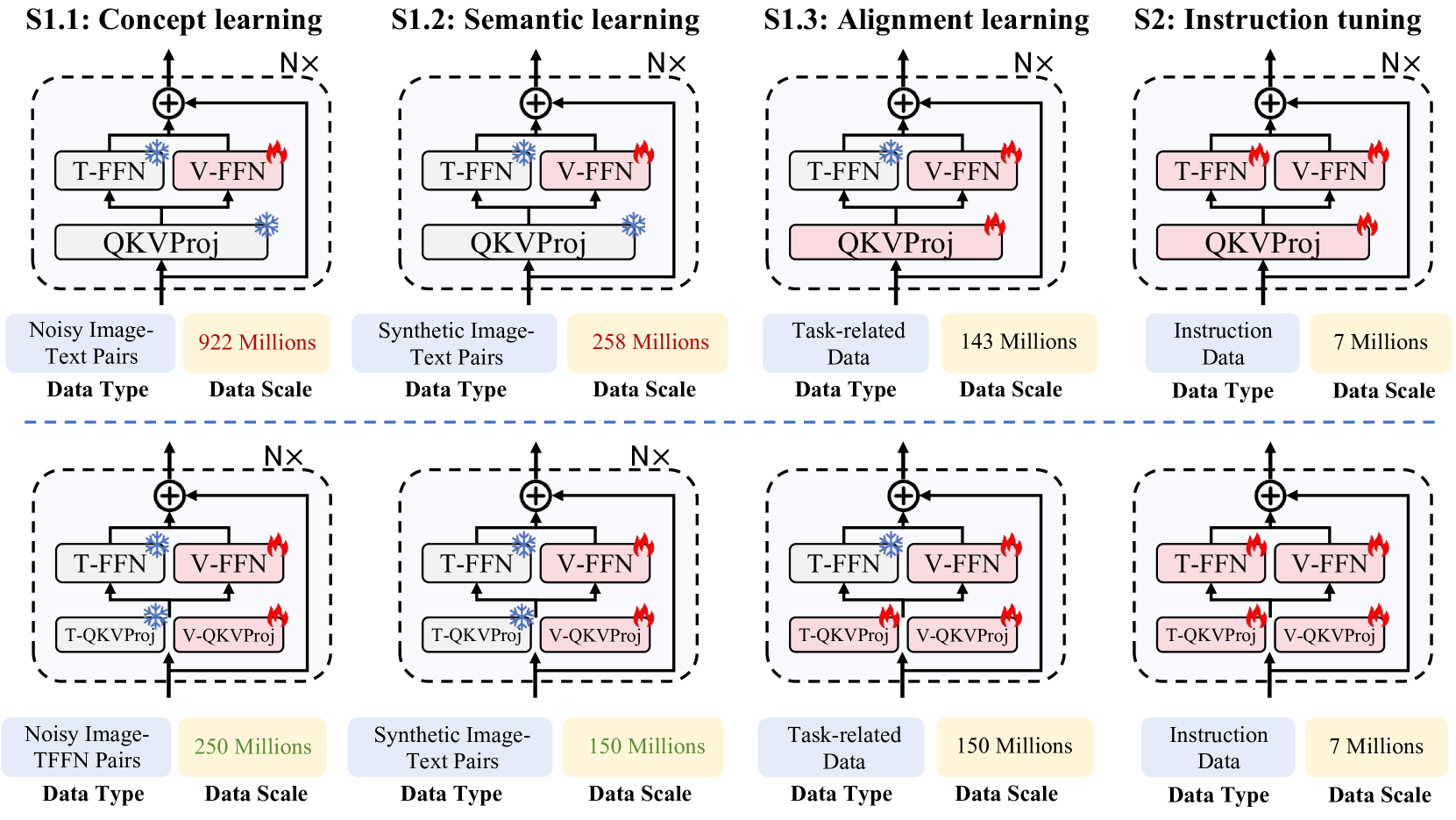
技术框架:Mono-InternVL-1.5的整体架构基于预训练的LLM,并引入了视觉专家模块。具体流程包括:1) 使用内生视觉预训练(EViP++)策略,逐步训练视觉专家模块,使其具备处理视觉信息的能力;2) 通过delta tuning将训练好的视觉专家模块嵌入到预训练的LLM中;3) 在下游任务上进行微调,以适应特定任务的需求。推理阶段,使用融合的CUDA内核加速MoE操作。
关键创新:论文的关键创新在于:1) 提出了内生视觉预训练(EViP++)策略,通过渐进式学习最大化视觉能力,并降低数据成本;2) 采用delta tuning的方式,将视觉知识嵌入到预训练的LLM中,避免灾难性遗忘;3) 使用融合的CUDA内核加速MoE操作,降低推理延迟。
关键设计:EViP++引入了额外的视觉注意力专家,并重新组织了预训练过程,使其更加高效。Delta tuning通过只更新少量参数,避免破坏预训练LLM的知识。融合的CUDA内核针对MoE操作进行了优化,提高了推理速度。具体的参数设置和损失函数细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
Mono-InternVL在15个基准测试中的12个上超越了现有的单体MLLM,例如在OCRBench上比Emu3提高了114个百分点。Mono-InternVL-1.5在保持与InternVL-1.5相似的多模态性能的同时,将首个token的延迟降低了高达69%,显著提升了推理效率。
🎯 应用场景
该研究成果可广泛应用于需要理解图像和文本信息的场景,例如智能客服、视觉问答、图像描述生成、OCR识别等。通过降低训练和推理成本,使得单体多模态大语言模型能够更容易地部署到资源受限的设备上,促进多模态人工智能技术的普及。
📄 摘要(原文)
This paper focuses on monolithic Multimodal Large Language Models (MLLMs), which integrate visual encoding and language decoding into a single model. Existing structures and pre-training strategies for monolithic MLLMs often suffer from unstable optimization and catastrophic forgetting. To address these challenges, our key idea is to embed a new visual parameter space into a pre-trained LLM, enabling stable learning of visual knowledge from noisy data via delta tuning. Based on this principle, we first introduce Mono-InternVL, an advanced monolithic MLLM that incorporates a set of visual experts through a multimodal mixture-of-experts architecture. In addition, we design an innovative Endogenous Visual Pre-training (EViP) for Mono-InternVL to maximize its visual capabilities via progressive learning. Mono-InternVL achieves competitive performance against existing MLLMs but also leads to relatively expensive data cost. Therefore, we further present Mono-InternVL-1.5, a cheaper and stronger monolithic MLLM equipped with an improved EViP (EViP++). EViP++ introduces additional visual attention experts to Mono-InternVL-1.5 and re-organizes the pre-training process in an efficient manner. During inference, it includes a fused CUDA kernel to speed up its MoE operations. With these designs, Mono-InternVL-1.5 significantly reduces training and inference costs, while still maintaining competitive performance with Mono-InternVL. To evaluate our approach, we conduct extensive experiments across 15 benchmarks. Results demonstrate that Mono-InternVL outperforms existing monolithic MLLMs on 12 out of 15 benchmarks, e.g., +114-point improvement over Emu3 on OCRBench. Compared to its modular counterpart, i.e., InternVL-1.5, Mono-InternVL-1.5 achieves similar multimodal performance while reducing first-token latency by up to 69%. Code and models are released at https://github.com/OpenGVLab/Mono-InternVL.