MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
作者: Yuncong Yang, Jiageng Liu, Zheyuan Zhang, Siyuan Zhou, Reuben Tan, Jianwei Yang, Yilun Du, Chuang Gan
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-07-16 (更新: 2025-11-01)
备注: Project Page: https://umass-embodied-agi.github.io/MindJourney
💡 一句话要点
MindJourney:利用世界模型进行测试时缩放,提升视觉语言模型在空间推理任务上的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 空间推理 视觉语言模型 世界模型 测试时缩放 视频扩散模型
📋 核心要点
- 现有视觉语言模型(VLMs)在3D空间推理方面存在不足,无法有效处理具身任务中对3D动态的理解和预测。
- MindJourney通过将VLM与可控世界模型结合,在测试时进行缩放,使VLM能够模拟和推理3D场景的动态变化。
- 实验表明,MindJourney在SAT空间推理基准测试中取得了显著的性能提升,无需微调即可平均提升7.7%。
📝 摘要(中文)
空间推理在3D空间中至关重要,对于导航和操作等具身任务不可或缺。然而,最先进的视觉语言模型(VLMs)在预测自我运动后场景外观等简单任务中表现不佳,因为它们感知2D图像,缺乏3D动态的内部模型。因此,我们提出了MindJourney,一个测试时缩放框架,通过将VLM与基于视频扩散的可控世界模型相结合,赋予VLM这种缺失的能力。VLM迭代地勾勒出一个简洁的相机轨迹,而世界模型在每个步骤合成相应的视图。然后,VLM基于交互探索期间收集的多视图证据进行推理。在没有任何微调的情况下,我们的MindJourney在代表性的空间推理基准SAT上实现了平均超过7.7%的性能提升,表明将VLM与世界模型配对进行测试时缩放,为鲁棒的3D推理提供了一种简单、即插即用的途径。同时,我们的方法也优于通过强化学习训练的测试时推理VLM,这证明了我们利用世界模型进行测试时缩放的潜力。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)在处理3D空间推理任务时,由于缺乏对3D动态的内部建模能力,导致其在理解和预测场景变化方面表现不佳。尤其是在需要根据自我运动推断场景外观的任务中,VLMs的性能受到限制。现有方法难以有效地将2D图像信息转化为对3D空间结构的理解,从而影响了其在具身任务中的应用。
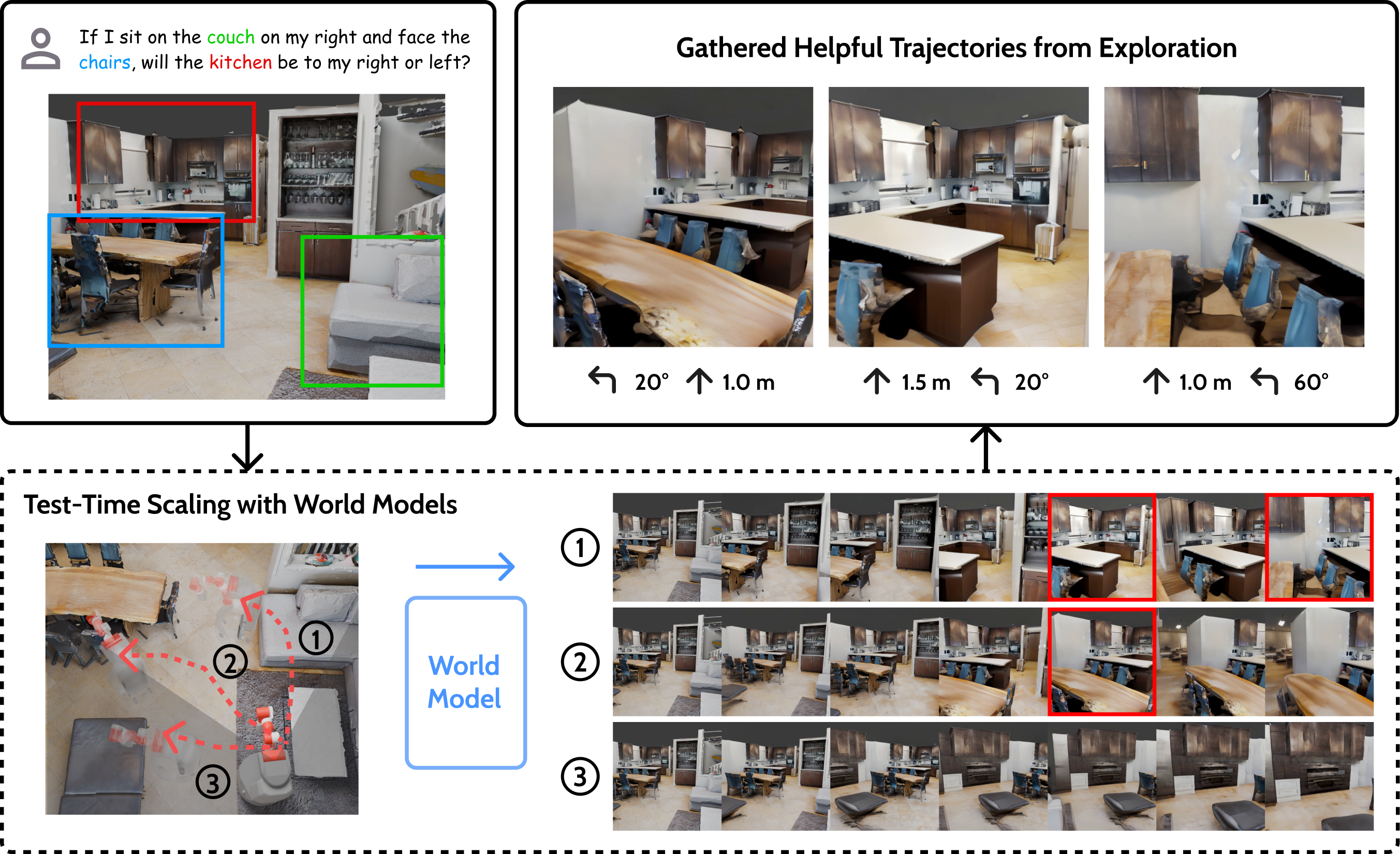
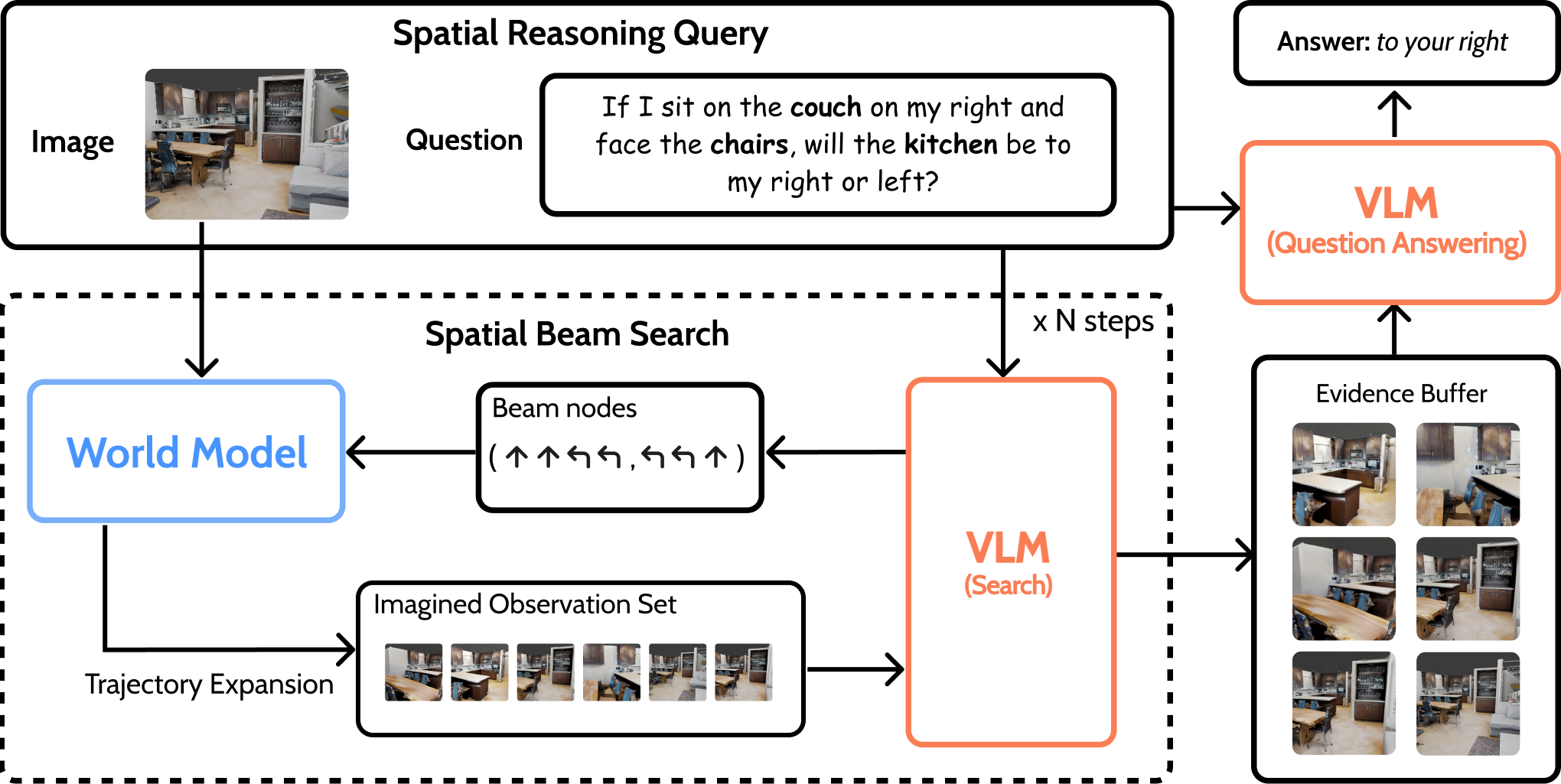
核心思路:MindJourney的核心思路是将VLMs与世界模型相结合,利用世界模型来弥补VLMs在3D动态建模方面的不足。通过让VLM与世界模型进行交互,VLM可以探索不同的视角,并利用世界模型生成相应的视图,从而获得更丰富的3D场景信息。这种方法允许VLM在测试时进行缩放,从而提高其空间推理能力。
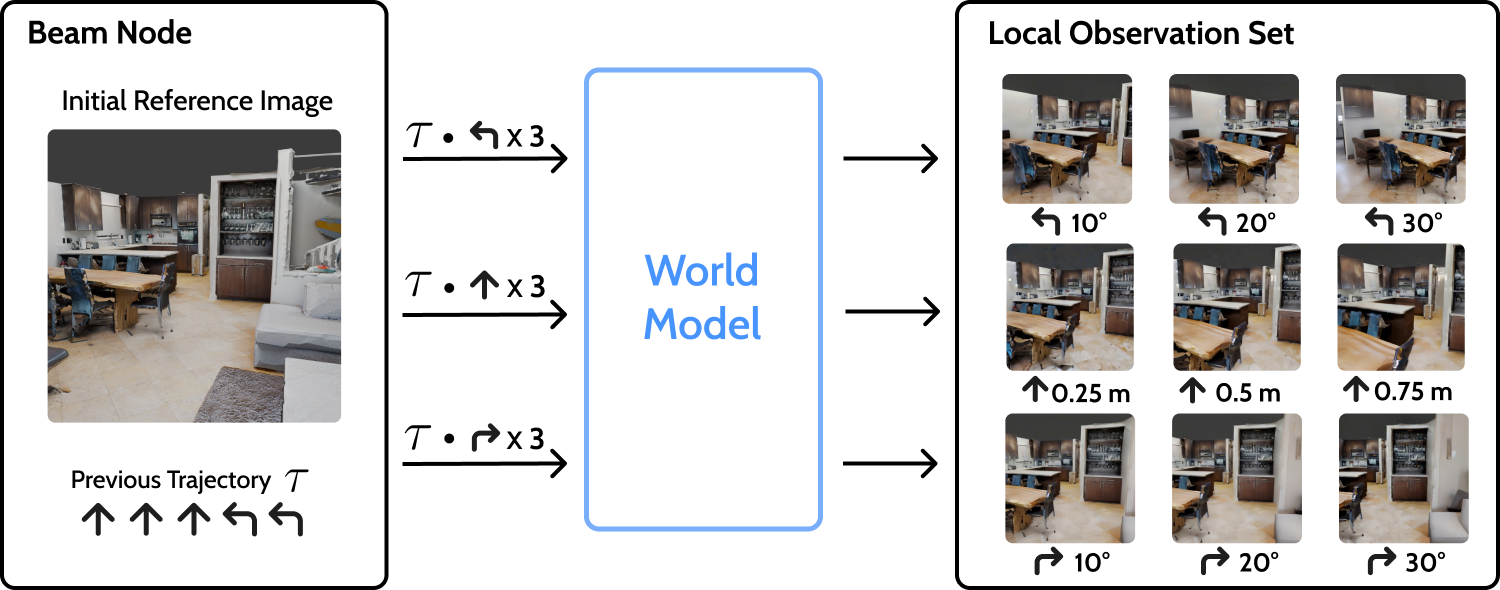
技术框架:MindJourney的整体框架包含两个主要模块:视觉语言模型(VLM)和世界模型。VLM负责生成相机轨迹,即一系列的视角变化。世界模型则根据VLM生成的相机轨迹,合成相应的视图。VLM通过迭代地生成相机轨迹和利用世界模型合成视图,从而探索3D场景。最终,VLM基于收集到的多视图证据进行推理,完成空间推理任务。
关键创新:MindJourney的关键创新在于其测试时缩放框架,该框架允许VLM在不进行任何微调的情况下,通过与世界模型交互来提高其空间推理能力。这种方法避免了对VLM进行大量训练的需要,并且可以很容易地应用于不同的VLM和世界模型。此外,MindJourney还提出了一种新的相机轨迹生成方法,该方法可以有效地探索3D场景。
关键设计:MindJourney的关键设计包括:1) 使用视频扩散模型作为世界模型,以生成高质量的视图;2) 设计了一种迭代的相机轨迹生成方法,该方法允许VLM逐步探索3D场景;3) 使用多视图融合技术,将来自不同视角的证据整合起来,以提高推理的准确性。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
MindJourney在SAT空间推理基准测试中取得了显著的性能提升,平均提升了7.7%。该方法无需对VLM进行任何微调,即可实现性能提升,表明其具有很强的通用性和易用性。此外,MindJourney的性能优于通过强化学习训练的测试时推理VLM,证明了其利用世界模型进行测试时缩放的有效性。
🎯 应用场景
MindJourney具有广泛的应用前景,可应用于机器人导航、虚拟现实、增强现实等领域。通过提高视觉语言模型在空间推理方面的能力,MindJourney可以使机器人更好地理解和操作周围环境,从而实现更智能的自主导航和物体操作。此外,MindJourney还可以用于生成逼真的虚拟环境,为用户提供更沉浸式的体验。
📄 摘要(原文)
Spatial reasoning in 3D space is central to human cognition and indispensable for embodied tasks such as navigation and manipulation. However, state-of-the-art vision-language models (VLMs) struggle frequently with tasks as simple as anticipating how a scene will look after an egocentric motion: they perceive 2D images but lack an internal model of 3D dynamics. We therefore propose MindJourney, a test-time scaling framework that grants a VLM with this missing capability by coupling it to a controllable world model based on video diffusion. The VLM iteratively sketches a concise camera trajectory, while the world model synthesizes the corresponding view at each step. The VLM then reasons over this multi-view evidence gathered during the interactive exploration. Without any fine-tuning, our MindJourney achieves over an average 7.7% performance boost on the representative spatial reasoning benchmark SAT, showing that pairing VLMs with world models for test-time scaling offers a simple, plug-and-play route to robust 3D reasoning. Meanwhile, our method also improves upon the test-time inference VLMs trained through reinforcement learning, which demonstrates the potential of our method that utilizes world models for test-time scaling.