Inversion-DPO: Precise and Efficient Post-Training for Diffusion Models
作者: Zejian Li, Yize Li, Chenye Meng, Zhongni Liu, Yang Ling, Shengyuan Zhang, Guang Yang, Changyuan Yang, Zhiyuan Yang, Lingyun Sun
分类: cs.CV, cs.AI
发布日期: 2025-07-14 (更新: 2025-08-03)
备注: Accepted by ACM MM25
🔗 代码/项目: GITHUB
💡 一句话要点
Inversion-DPO:一种精确高效的扩散模型后训练方法,无需奖励模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 后训练 直接偏好优化 DDIM反演 文本到图像生成
📋 核心要点
- 现有扩散模型对齐方法依赖计算密集的奖励模型训练,导致计算开销大,并可能降低模型精度和训练效率。
- Inversion-DPO通过DDIM反演重构DPO,避免了奖励模型的训练,实现了更精确和高效的扩散模型对齐。
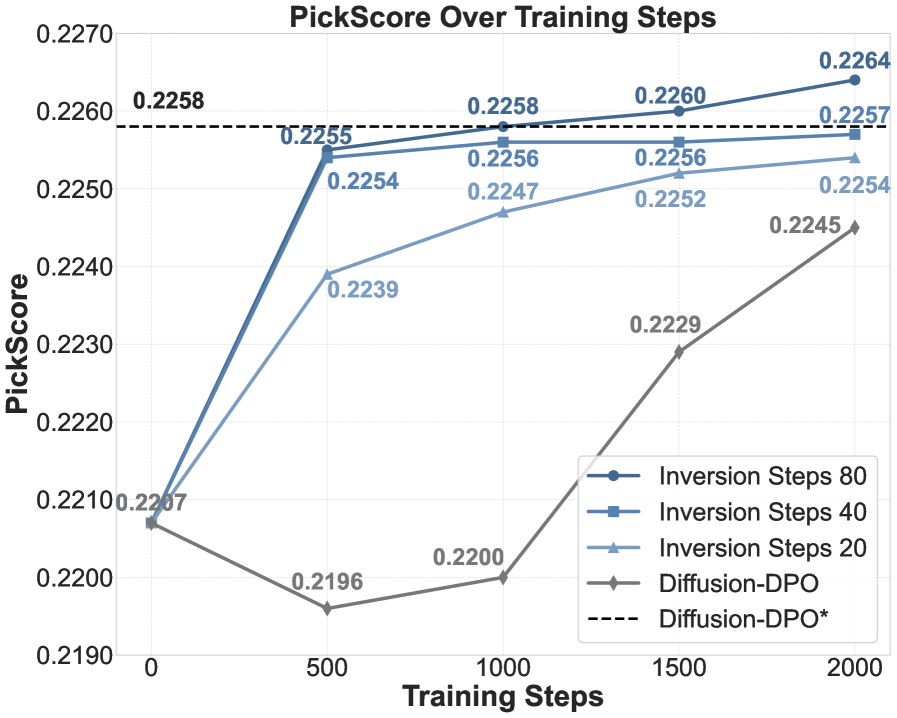
- 实验表明,Inversion-DPO在文本到图像生成和组合图像生成任务上,显著优于现有后训练方法,生成图像质量更高。
📝 摘要(中文)
扩散模型(DMs)的最新进展得益于对模型进行后训练以更好符合人类偏好的对齐方法。然而,这些方法通常需要计算密集的基础模型和奖励模型的训练,这不仅导致巨大的计算开销,还可能损害模型精度和训练效率。为了解决这些限制,我们提出Inversion-DPO,一种新颖的对齐框架,通过使用DDIM反演为DMs重新制定直接偏好优化(DPO)来规避奖励建模。我们的方法通过从获胜和失败样本到噪声的确定性反演,在Diffusion-DPO中进行难以处理的后验采样,从而推导出一种新的后训练范式。这种范式消除了对辅助奖励模型或不准确近似的需要,显著提高了训练的精度和效率。我们将Inversion-DPO应用于文本到图像生成的基本任务和组合图像生成的具有挑战性的任务。广泛的实验表明,与现有的后训练方法相比,Inversion-DPO取得了显著的性能改进,并突出了训练后的生成模型生成高保真度、组合连贯图像的能力。对于组合图像生成的后训练,我们整理了一个包含11,140张带有复杂结构注释和综合分数的配对数据集,旨在增强生成模型的组合能力。Inversion-DPO探索了一种在扩散模型中实现高效、高精度对齐的新途径,从而提高了它们在复杂现实生成任务中的适用性。
🔬 方法详解
问题定义:论文旨在解决扩散模型后训练对齐过程中,对奖励模型依赖所带来的计算开销大、训练效率低以及可能损害模型精度的问题。现有方法需要训练额外的奖励模型来指导扩散模型的生成过程,这增加了计算负担,并且奖励模型的准确性直接影响最终生成结果的质量。
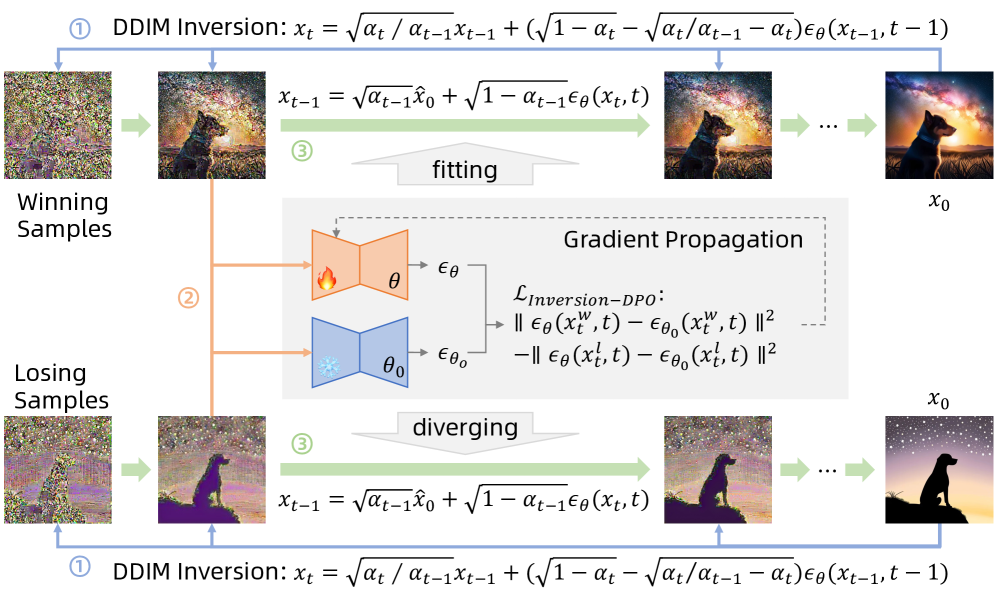
核心思路:论文的核心思路是利用DDIM反演来避免训练奖励模型。通过将DPO(Direct Preference Optimization)与DDIM反演相结合,直接从人类偏好数据中学习,而无需显式地建模奖励函数。这种方法利用DDIM反演的确定性特性,将图像映射到噪声空间,从而简化了后验采样过程。
技术框架:Inversion-DPO的整体框架包括以下几个主要步骤:1) 数据收集:收集包含偏好信息的图像对,即对于给定的文本提示,哪些图像更符合人类偏好。2) DDIM反演:使用DDIM反演将图像对中的获胜图像和失败图像分别反演到噪声空间。3) DPO优化:利用反演得到的噪声作为DPO的目标,直接优化扩散模型,使其生成的图像更接近获胜图像的噪声分布,远离失败图像的噪声分布。
关键创新:Inversion-DPO的关键创新在于利用DDIM反演将DPO应用于扩散模型。传统DPO需要对奖励函数进行建模和优化,而Inversion-DPO通过DDIM反演将图像映射到噪声空间,从而避免了奖励模型的训练。这种方法不仅提高了训练效率,还避免了奖励模型带来的误差累积。
关键设计:Inversion-DPO的关键设计包括:1) 使用DDIM反演作为连接图像空间和噪声空间的桥梁。2) 将DPO损失函数应用于反演得到的噪声,直接优化扩散模型。3) 针对组合图像生成任务,论文还构建了一个包含11,140张图像的配对数据集,该数据集带有复杂的结构注释和综合评分,用于提升生成模型的组合能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Inversion-DPO在文本到图像生成和组合图像生成任务上均取得了显著的性能提升。与现有的后训练方法相比,Inversion-DPO能够生成更高质量、更符合人类偏好的图像。特别是在组合图像生成任务上,Inversion-DPO能够生成具有更高保真度和组合连贯性的图像,证明了其在复杂生成任务上的有效性。论文构建的包含11,140张图像的配对数据集也为组合图像生成领域的研究提供了宝贵资源。
🎯 应用场景
Inversion-DPO可广泛应用于各种需要对扩散模型进行对齐的任务,例如文本到图像生成、图像编辑、风格迁移等。该方法能够提高生成图像的质量和与人类偏好的一致性,在艺术创作、设计、内容生成等领域具有重要的应用价值和潜力。未来,该方法可以进一步扩展到视频生成、3D内容生成等更复杂的任务中。
📄 摘要(原文)
Recent advancements in diffusion models (DMs) have been propelled by alignment methods that post-train models to better conform to human preferences. However, these approaches typically require computation-intensive training of a base model and a reward model, which not only incurs substantial computational overhead but may also compromise model accuracy and training efficiency. To address these limitations, we propose Inversion-DPO, a novel alignment framework that circumvents reward modeling by reformulating Direct Preference Optimization (DPO) with DDIM inversion for DMs. Our method conducts intractable posterior sampling in Diffusion-DPO with the deterministic inversion from winning and losing samples to noise and thus derive a new post-training paradigm. This paradigm eliminates the need for auxiliary reward models or inaccurate appromixation, significantly enhancing both precision and efficiency of training. We apply Inversion-DPO to a basic task of text-to-image generation and a challenging task of compositional image generation. Extensive experiments show substantial performance improvements achieved by Inversion-DPO compared to existing post-training methods and highlight the ability of the trained generative models to generate high-fidelity compositionally coherent images. For the post-training of compostitional image geneation, we curate a paired dataset consisting of 11,140 images with complex structural annotations and comprehensive scores, designed to enhance the compositional capabilities of generative models. Inversion-DPO explores a new avenue for efficient, high-precision alignment in diffusion models, advancing their applicability to complex realistic generation tasks. Our code is available at https://github.com/MIGHTYEZ/Inversion-DPO