Cameras as Relative Positional Encoding
作者: Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, Angjoo Kanazawa
分类: cs.CV, cs.AI
发布日期: 2025-07-14 (更新: 2025-11-13)
备注: Project Page: https://www.liruilong.cn/prope/
期刊: NeurIPS 2025
💡 一句话要点
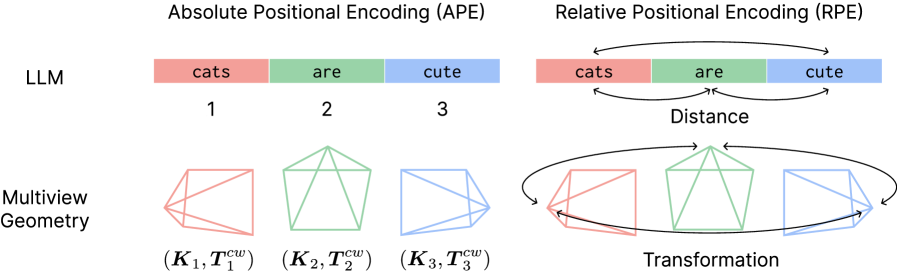
提出PRoPE:将相机参数作为相对位置编码,提升多视角Transformer的3D感知能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多视角学习 Transformer 位置编码 相机几何 三维感知
📋 核心要点
- 多视角Transformer需要有效利用相机几何信息进行3D感知,现有方法在相机信息的编码方式上存在不足。
- 论文提出Projective Positional Encoding (PRoPE),将相机视锥作为相对位置编码,同时考虑相机内参和外参。
- 实验表明,PRoPE能够提升新视角合成、立体深度估计和空间认知等任务的性能,并具有良好的泛化能力。
📝 摘要(中文)
Transformer在多视角计算机视觉任务中日益普及,而视角间的几何关系对于3D感知至关重要。为了利用这些关系,多视角Transformer必须使用相机几何信息将视觉tokens定位到3D空间中。本文比较了多种将相机信息融入Transformer的方法:token级别的raymap编码、attention级别的相对位姿编码,以及我们提出的新型相对编码——Projective Positional Encoding (PRoPE),它将完整的相机视锥(包括内参和外参)作为相对位置编码进行建模。实验表明,相对相机信息能够提升前馈式新视角合成的性能,而PRoPE能进一步提升性能。这一结论在不同场景下都成立:包括共享和变化的相机内参、token级别和attention级别信息的结合,以及推广到具有分布外序列长度和相机内参的输入。我们还验证了这些优势在不同任务(立体深度估计和判别空间认知)以及更大模型尺寸下依然存在。
🔬 方法详解
问题定义:多视角3D感知任务依赖于准确的相机几何信息。现有的Transformer架构在处理多视角数据时,如何有效地将相机参数融入到模型中是一个关键问题。已有的方法,如直接编码相机位姿或使用raymap,可能无法充分捕捉相机之间的相对关系,或者忽略了相机内参的影响。这些局限性导致模型在复杂场景或具有变化相机参数的场景下性能下降。
核心思路:论文的核心思路是将相机参数(包括内参和外参)以相对位置编码的形式融入到Transformer的注意力机制中。通过将相机视锥投影到特征空间,模型能够学习到不同视角之间的几何关系,从而提高3D感知的准确性。这种方法的核心在于将相机参数视为一种空间关系,而不是简单的附加信息。
技术框架:整体框架包括一个标准的Transformer架构,但在注意力机制中引入了PRoPE模块。首先,从多个视角获取图像特征。然后,利用相机内参和外参计算每个视角对应的相机视锥。接下来,PRoPE模块将这些视锥投影到特征空间,生成相对位置编码。最后,将这些编码添加到注意力权重中,从而使模型能够感知不同视角之间的几何关系。
关键创新:最重要的技术创新点是Projective Positional Encoding (PRoPE)。与现有的方法相比,PRoPE能够同时考虑相机内参和外参,并将它们以相对位置编码的形式融入到注意力机制中。这种方法能够更全面地捕捉相机之间的几何关系,从而提高3D感知的准确性。此外,PRoPE的设计允许模型处理具有不同相机参数和序列长度的输入,提高了模型的泛化能力。
关键设计:PRoPE模块的关键设计包括:1) 使用相机内参和外参计算相机视锥;2) 将视锥投影到特征空间,生成相对位置编码;3) 将相对位置编码添加到注意力权重中。损失函数方面,使用了标准的图像重建损失和深度预测损失。网络结构方面,使用了标准的Transformer架构,并根据具体任务进行了调整。参数设置方面,对学习率、batch size等超参数进行了优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PRoPE在多个任务上都取得了显著的性能提升。在新视角合成任务中,PRoPE相比于基线方法取得了明显的PSNR和SSIM提升。在立体深度估计任务中,PRoPE也降低了深度误差。此外,实验还验证了PRoPE在具有不同相机参数和序列长度的输入上的泛化能力。例如,在泛化性实验中,PRoPE在未见过的相机内参设置下仍然表现出良好的性能。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实、增强现实等领域。通过更准确地理解多视角图像中的3D几何信息,可以提高自动驾驶系统的环境感知能力,改善机器人的导航精度,并增强虚拟现实和增强现实的用户体验。此外,该方法还可以用于三维重建、场景理解等任务。
📄 摘要(原文)
Transformers are increasingly prevalent for multi-view computer vision tasks, where geometric relationships between viewpoints are critical for 3D perception. To leverage these relationships, multi-view transformers must use camera geometry to ground visual tokens in 3D space. In this work, we compare techniques for conditioning transformers on cameras: token-level raymap encodings, attention-level relative pose encodings, and a new relative encoding we propose -- Projective Positional Encoding (PRoPE) -- that captures complete camera frustums, both intrinsics and extrinsics, as a relative positional encoding. Our experiments begin by showing how relative camera conditioning improves performance in feedforward novel view synthesis, with further gains from PRoPE. This holds across settings: scenes with both shared and varying intrinsics, when combining token- and attention-level conditioning, and for generalization to inputs with out-of-distribution sequence lengths and camera intrinsics. We then verify that these benefits persist for different tasks, stereo depth estimation and discriminative spatial cognition, as well as larger model sizes.