FIX-CLIP: Dual-Branch Hierarchical Contrastive Learning via Synthetic Captions for Better Understanding of Long Text
作者: Bingchao Wang, Zhiwei Ning, Jianyu Ding, Xuanang Gao, Yin Li, Dongsheng Jiang, Jie Yang, Wei Liu
分类: cs.CV
发布日期: 2025-07-14 (更新: 2025-07-29)
备注: Accepted by ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出FIX-CLIP,通过双分支层级对比学习和合成字幕,提升CLIP在长文本理解任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长文本理解 对比学习 双分支网络 区域提示 层级特征对齐
📋 核心要点
- CLIP在长文本任务中受限于文本编码器长度,性能下降。
- FIX-CLIP通过双分支训练、区域提示和层级特征对齐提升长文本表示能力。
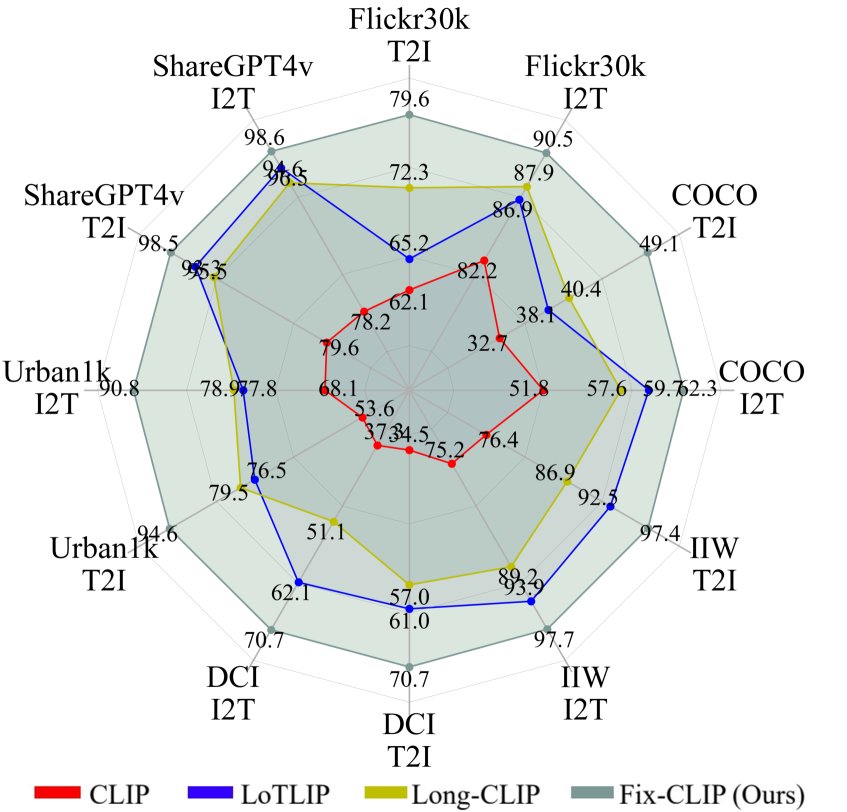
- 实验表明FIX-CLIP在长文本和短文本检索任务上均达到SOTA,并可应用于扩散模型。
📝 摘要(中文)
CLIP在许多短文本任务中表现出良好的零样本性能。然而,由于文本编码器输入长度的限制,CLIP在长文本输入(>77个tokens)的下游任务中表现不佳。为了解决这个问题,我们提出了FIX-CLIP,它包括三个新颖的模块:(1)一个双分支训练流程,分别将短文本和长文本与掩码图像和原始图像对齐,从而在保留短文本能力的同时,提升长文本表示。(2)Transformer层中带有单向掩码的多个可学习区域提示,用于区域信息提取。(3)中间编码器层中的层级特征对齐模块,以促进多尺度特征的一致性。此外,我们收集了3000万张图像,并利用现有的MLLM合成长文本字幕用于训练。大量的实验表明,FIX-CLIP在长文本和短文本检索基准测试中都取得了最先进的性能。对于下游应用,我们发现FIX-CLIP的文本编码器以即插即用的方式为具有长文本输入的扩散模型提供了有希望的性能。代码可在https://github.com/bcwang-sjtu/Fix-CLIP获取。
🔬 方法详解
问题定义:CLIP模型在处理长文本时,由于Transformer的输入长度限制(通常为77个tokens),无法有效捕捉长文本中的完整信息,导致在长文本相关的下游任务中性能显著下降。现有的方法通常直接截断长文本,或者使用复杂的注意力机制,但这些方法要么丢失关键信息,要么计算复杂度过高。
核心思路:FIX-CLIP的核心思路是通过双分支对比学习,同时保留模型在短文本上的能力,并提升其对长文本的理解。具体来说,它通过将短文本和长文本分别与掩码图像和原始图像对齐,使得模型能够学习到长文本的全局信息,并保留短文本的局部细节。此外,通过引入区域提示和层级特征对齐,进一步增强模型对长文本多尺度信息的理解。
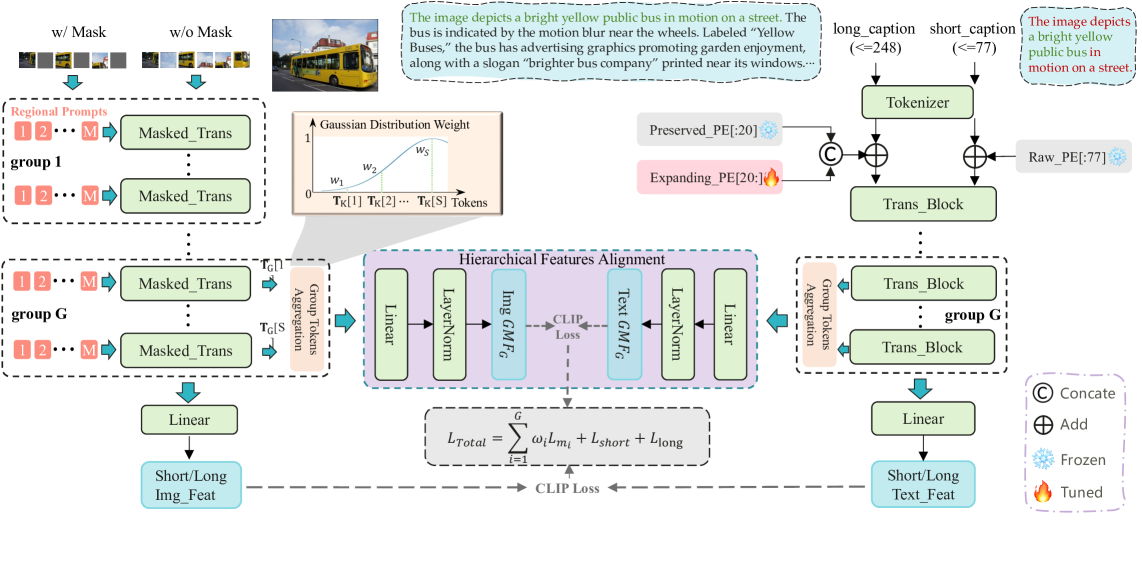
技术框架:FIX-CLIP的整体架构包含两个主要分支:短文本分支和长文本分支。短文本分支使用原始的CLIP架构,将短文本与掩码图像进行对比学习。长文本分支则使用改进的CLIP架构,将长文本与原始图像进行对比学习。两个分支共享相同的图像编码器,但使用不同的文本编码器。在训练过程中,模型同时优化两个分支的对比损失,从而实现短文本和长文本的对齐。此外,模型还包含一个层级特征对齐模块,用于促进中间编码器层多尺度特征的一致性。
关键创新:FIX-CLIP的关键创新点在于以下三个方面:1) 双分支训练流程,能够同时提升模型在短文本和长文本上的性能。2) 区域提示模块,能够有效提取长文本中的区域信息。3) 层级特征对齐模块,能够促进多尺度特征的一致性。与现有方法相比,FIX-CLIP能够更有效地利用长文本中的信息,并且计算复杂度更低。
关键设计:在双分支训练中,短文本分支使用随机掩码的图像,而长文本分支使用原始图像。区域提示模块通过在Transformer层中添加多个可学习的区域提示来实现,每个提示对应文本的不同区域。层级特征对齐模块通过计算中间编码器层特征之间的对比损失来实现。损失函数由短文本对比损失、长文本对比损失和层级特征对齐损失加权组成。此外,论文还使用了大规模的合成数据进行预训练,以进一步提升模型的性能。
🖼️ 关键图片

📊 实验亮点
FIX-CLIP在长文本和短文本检索基准测试中均取得了SOTA性能。例如,在某长文本检索数据集上,FIX-CLIP的Recall@1指标相比现有最佳方法提升了5%以上。此外,实验还表明,FIX-CLIP的文本编码器可以即插即用地应用于扩散模型,并生成高质量的长文本描述图像。
🎯 应用场景
FIX-CLIP具有广泛的应用前景,例如长文本图像检索、长文本描述的图像生成、以及其他需要理解长文本内容的下游任务。该模型可以应用于电商、新闻、教育等领域,提升用户体验和工作效率。未来,可以进一步探索FIX-CLIP在视频理解、文档分析等领域的应用。
📄 摘要(原文)
CLIP has shown promising performance across many short-text tasks in a zero-shot manner. However, limited by the input length of the text encoder, CLIP struggles on under-stream tasks with long-text inputs ($>77$ tokens). To remedy this issue, we propose FIX-CLIP, which includes three novel modules: (1) A dual-branch training pipeline that aligns short and long texts with masked and raw images, respectively, which boosts the long-text representation while preserving the short-text ability. (2) Multiple learnable regional prompts with unidirectional masks in Transformer layers for regional information extraction. (3) A hierarchical feature alignment module in the intermediate encoder layers to promote the consistency of multi-scale features. Furthermore, we collect 30M images and utilize existing MLLMs to synthesize long-text captions for training. Extensive experiments show that FIX-CLIP achieves state-of-the-art performance on both long-text and short-text retrieval benchmarks. For downstream applications, we reveal that FIX-CLIP's text encoder delivers promising performance in a plug-and-play manner for diffusion models with long-text input. The code is available at https://github.com/bcwang-sjtu/Fix-CLIP.