(Almost) Free Modality Stitching of Foundation Models
作者: Jaisidh Singh, Diganta Misra, Boris Knyazev, Antonio Orvieto
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-14 (更新: 2025-07-17)
备注: Pre-print
💡 一句话要点
提出Hyma框架,利用超网络实现多模态模型高效拼接与最优单模态模型选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 超网络 模型拼接 单模态模型选择 连接器训练
📋 核心要点
- 现有方法在拼接多模态模型时,需要对大量单模态模型组合进行连接器训练,计算成本高昂。
- Hyma利用超网络预测连接器参数,实现对多个单模态模型组合的联合训练,从而降低搜索成本。
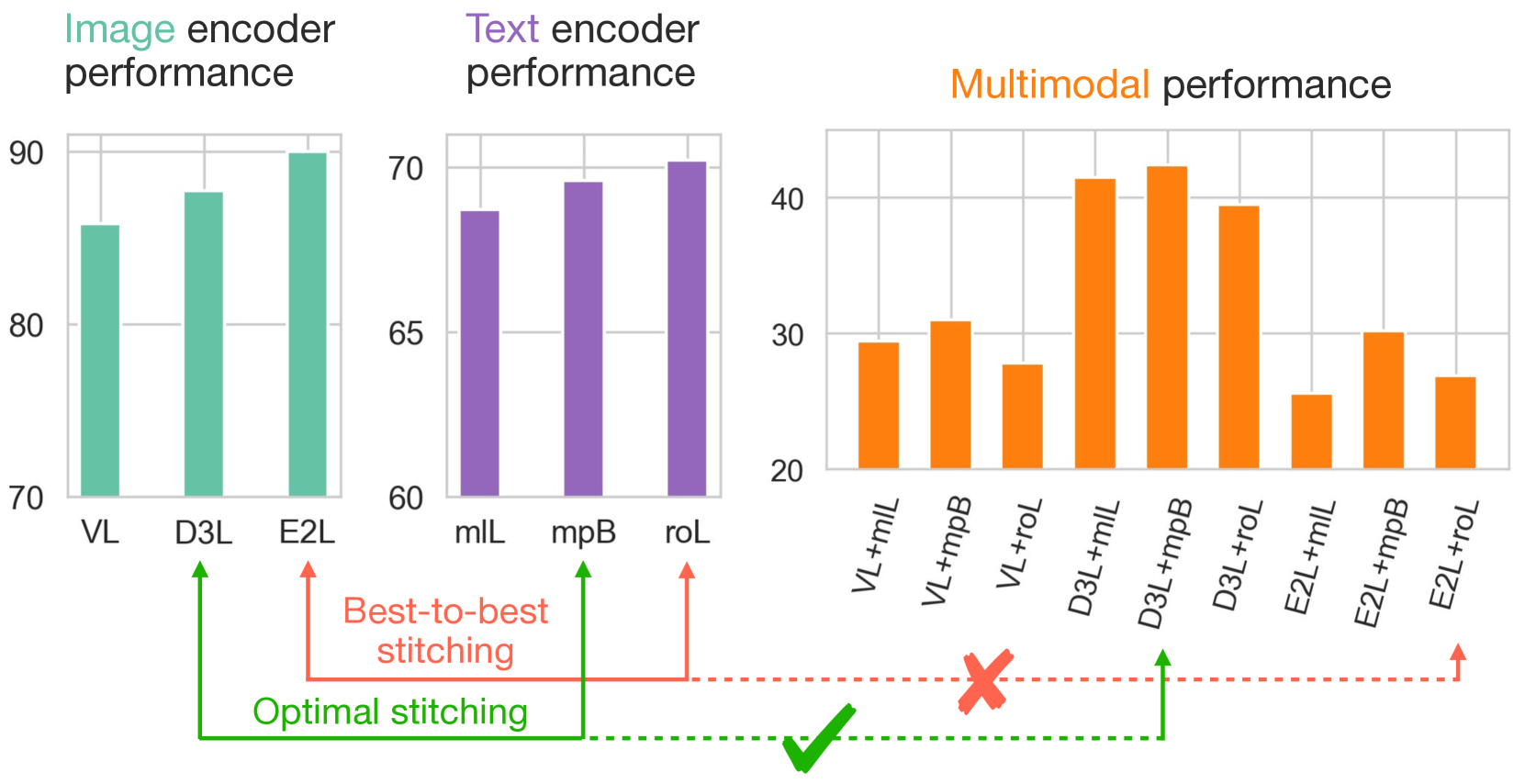
- 实验表明,Hyma能以10倍的效率降低搜索成本,同时保持与网格搜索相当的性能。
📝 摘要(中文)
本文提出了一种名为超网络模型对齐(Hyma)的全新一体化解决方案,旨在解决多模态模型中单模态模型选择和连接器训练的计算成本问题。多模态模型通常通过拼接多个预训练的单模态模型(例如图像分类器和文本模型)来构建。这个拼接过程需要训练一个连接器模块,以对齐这些单模态模型的表示空间,从而实现多模态目标。然而,由于大规模网络数据集上训练连接器的复杂性,以及可用的预训练单模态模型数量不断增加,单模态模型选择和后续连接器模块训练的任务变得计算密集。Hyma利用超网络的参数预测能力,为N×M个单模态模型组合联合训练连接器模块。实验表明,Hyma在匹配通过网格搜索获得的排名和训练连接器性能的同时,将搜索最佳单模态模型对的成本降低了10倍。
🔬 方法详解
问题定义:现有的多模态模型构建方法,通常需要通过训练连接器模块来对齐不同单模态模型的特征空间。然而,随着预训练单模态模型数量的爆炸式增长,对所有可能的单模态模型组合进行连接器训练的计算成本变得非常巨大,这使得找到最佳的单模态模型组合变得极具挑战性。现有方法缺乏一种高效的单模态模型选择和连接器训练方案。
核心思路:Hyma的核心思路是利用超网络(Hypernetwork)的参数预测能力,直接预测不同单模态模型组合的连接器参数。通过训练一个超网络,使其能够根据输入的单模态模型信息,生成对应的连接器参数,从而避免了对每个单模态模型组合都进行单独训练的需要。这种方法显著降低了计算成本,并实现了对最优单模态模型组合的快速搜索。
技术框架:Hyma框架主要包含两个核心模块:单模态模型编码器和超网络。单模态模型编码器负责将每个单模态模型的信息编码成一个向量表示。超网络接收这些向量表示作为输入,并预测对应的连接器参数。整个训练过程旨在优化超网络,使其能够为不同的单模态模型组合生成有效的连接器参数。在推理阶段,通过超网络预测连接器参数,即可快速评估不同单模态模型组合的性能。
关键创新:Hyma的关键创新在于利用超网络实现了对连接器参数的直接预测,从而避免了对每个单模态模型组合进行单独训练的需要。这与传统的连接器训练方法形成了鲜明对比,传统方法需要对每个单模态模型组合都进行完整的训练过程。Hyma通过参数预测的方式,极大地降低了计算成本,并实现了对最优单模态模型组合的高效搜索。
关键设计:超网络的设计是Hyma的关键。论文中可能采用了特定的超网络结构,例如多层感知机(MLP)或Transformer结构,用于参数预测。损失函数的设计也至关重要,可能包括多模态对齐损失和连接器性能损失等,用于指导超网络的训练。此外,单模态模型编码器的设计也需要考虑如何有效地提取单模态模型的关键信息,以便超网络能够准确地预测连接器参数。具体的参数设置(如超网络层数、隐藏层大小、学习率等)可能需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Hyma在多个多模态基准测试中取得了显著的性能提升。具体来说,Hyma能够以10倍的效率降低搜索最佳单模态模型对的成本,同时保持与网格搜索相当的性能。这表明Hyma是一种高效且有效的多模态模型构建方法。
🎯 应用场景
Hyma框架可广泛应用于多模态学习领域,例如视觉-语言任务、语音-文本任务等。它能够帮助研究人员和工程师快速构建高性能的多模态模型,并降低模型开发的计算成本。此外,Hyma还可以应用于模型压缩和知识迁移等领域,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Foundation multi-modal models are often designed by stitching of multiple existing pretrained uni-modal models: for example, an image classifier with an text model. This stitching process is performed by training a connector module that aims to align the representation spaces of these uni-modal models towards a multi-modal objective. However, given the complexity of training such connectors on large scale web-based datasets coupled with the ever-increasing number of available pretrained uni-modal models, the task of uni-modal models selection and subsequent connector module training becomes computationally demanding. To address this under-studied critical problem, we propose Hypernetwork Model Alignment (Hyma), a novel all-in-one solution for optimal uni-modal model selection and connector training by leveraging hypernetworks. Specifically, our framework utilizes the parameter prediction capability of a hypernetwork to obtain jointly trained connector modules for $N \times M$ combinations of uni-modal models. In our experiments, Hyma reduces the cost of searching for the best performing uni-modal model pair by $10\times$, while matching the ranking and trained connector performance obtained via grid search across a suite of diverse multi-modal benchmarks.